Más allá de las listas de filtros: repensando el bloqueo de anuncios con LLMs
Um dos maiores obstáculos que os bloqueadores de anúncios vêm enfrentando de forma consistente ao longo de toda a sua existência está profundamente ligado à sua própria natureza — as limitações das listas de filtros e a necessidade de mantê-las. Essa manutenção é, na maioria dos casos, manual e extremamente trabalhosa.
Nesta pesquisa, vou explorar como o bloqueio de anúncios funciona atualmente e revisar tentativas anteriores de automatizá-lo aplicando aprendizado de máquina. Em seguida, apresentarei meus próprios experimentos adicionando LLM ao bloqueio de anúncios, discutirei para onde essa abordagem está caminhando e até mostrarei a extensão de navegador protótipo funcional que você pode baixar e testar por conta própria.
E embora eu saiba que você provavelmente esteja ansioso para saber mais sobre os experimentos com LLM e conferir a extensão — antes, vamos contextualizar com algumas informações.
Como o bloqueio de anúncios funciona hoje
No núcleo de todos os bloqueadores de anúncios estão as listas de filtros mantidas pela comunidade. Essas listas consistem em milhares de regras que se dividem em duas categorias principais: regras de rede e regras cosméticas.
Reglas de red: la primera línea de defensa
Acciones: Bloquear, redirigir o modificar solicitudes.
Ejemplo: ||evil-ads.com^ — esta regla bloquea el sitio evil-ads.com y sus subdominios.
Las reglas de red bloquean solicitudes a servidores de anuncios de terceros incluso antes de que el contenido llegue a tu navegador. Es un enfoque rápido y eficiente. Estas reglas pueden bloquear, redirigir o modificar solicitudes.
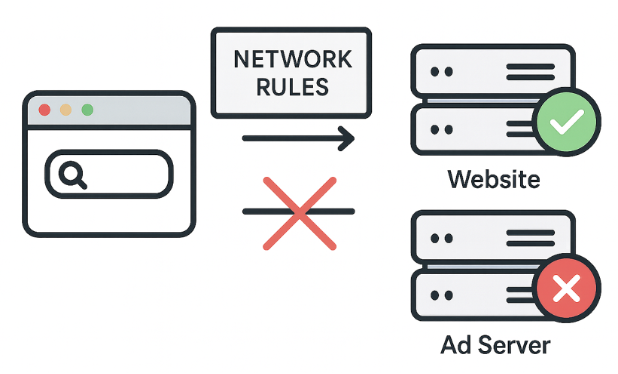
Pero las reglas de red no pueden bloquearlo todo. Por ejemplo, algunos anuncios se sirven desde el mismo dominio del contenido, así que bloquearlos a nivel de red rompería el sitio. Ahí es donde entran las reglas cosméticas.
Reglas cosméticas: limpiando la página
Acciones: Usar selectores CSS para ocultar elementos no deseados directamente en la página o aplicar estilos personalizados.
Ejemplo: example.com##.ad-banner — oculta elementos con la clase “ad-banner” en example.com.
CSS (Cascading Style Sheets) es un lenguaje de hojas de estilo que define cómo se presentan visualmente los documentos HTML o XML. Especifica cómo deben aparecer los elementos en la pantalla de tu dispositivo.
Las reglas cosméticas básicamente limpian los elementos publicitarios restantes que las reglas de red más simples no pueden bloquear.
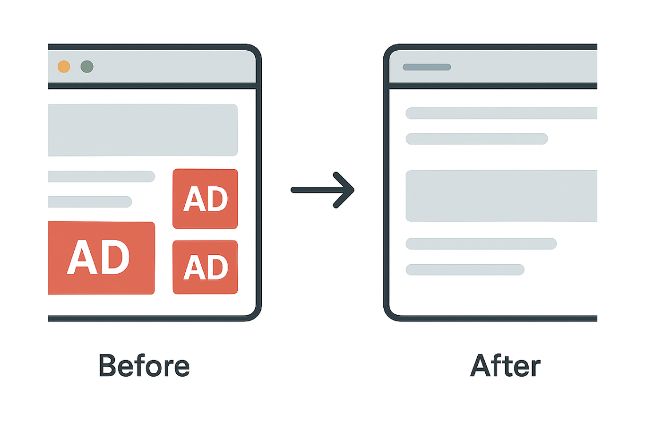
Más allá del CSS: reglas de scriptlet
Acciones: Modificar o desactivar funcionalidades específicas de scripts en la página.
Ejemplo: example.com#%#//scriptlet('abort-on-property-read', 'alert') — impide que un script en example.com acceda a un recurso específico del navegador, como alert.
Cuando el CSS no es suficiente para manejar scripts complejos —como la reinserción de anuncios— usamos scriptlets. Los scriptlets son pequeños fragmentos de JavaScript inyectados por los bloqueadores de anuncios para neutralizar comportamientos no deseados.
Los scriptlets se han convertido en la herramienta favorita de los desarrolladores de filtros porque resuelven problemas que el CSS y las reglas de red no pueden.
El poder y los límites
Ya vimos rápidamente cómo funcionan las listas de filtros. Son poderosas y funcionan muy bien para patrones conocidos, pero también tienen algunas limitaciones. Les cuesta lidiar con la publicidad nativa, requieren actualizaciones constantes y, con el Manifest v3, esas actualizaciones se vuelven más difíciles.
Estas limitaciones nos llevan a una pregunta fundamental: ¿y si pudiéramos eliminar por completo las listas de filtros? ¿Y si el bloqueador de anuncios pudiera decidir por sí mismo qué bloquear?
Imagina: sin filtros, sin actualizaciones, sin perseguir a las redes publicitarias. Sin ajustes manuales ni el juego del gato y el ratón. Al final, ¿no es eso exactamente lo que los usuarios esperan naturalmente de un bloqueador de anuncios? “Instalar y olvidar”, disfrutando de una web limpia sin tener que preocuparse por él. Y eso es precisamente lo que los primeros experimentos con aprendizaje automático buscaban lograr.
Con esa motivación en mente, veamos cómo empresas e investigadores han intentado usar aprendizaje automático para resolver estos problemas.
Una breve historia del machine learning en el bloqueo de anuncios
Demos un vistazo a varios intentos pasados de reemplazar las listas de filtros con aprendizaje automático. Esto nos ayudará a entender por qué eso aún no ha sucedido, al menos no por completo.
Project Moonshot de eyeo
Objetivo: Automatizar el bloqueo cosmético a gran escala.
Método:
- Entrenó un modelo de ML basado en la estructura de la página (DOM, HTML, CSS)
- Usó listas de filtros existentes para el etiquetado
- Analizó páginas directamente dentro de la extensión del navegador
El Project Moonshot de eyeo fue presentado en el Ad-Filtering Dev Summit en 2021. Entrenaron un modelo usando la estructura de la página y listas de filtros como etiquetas. El modelo corría dentro de la extensión del navegador para predecir y ocultar elementos publicitarios. Funcionó, pero enfrentó desafíos: datos desbalanceados, dificultades de implementación y necesidad constante de reentrenamiento.
Idea principal: Tomar decisiones basadas en la estructura de la página, no en imágenes.
Resultado: Predecía y ocultaba elementos de anuncios, complementando el bloqueo de red.
Desafíos: Datos desbalanceados, implementación compleja y necesidad de reentrenamiento constante.
AdGraph de Brave
Objetivo: Bloquear anuncios y rastreadores en tiempo real.
Método:
- Construyó un grafo conectando todas las actividades de la página (DOM, red, JavaScript)
- Clasificó el contenido según el contexto dentro del grafo
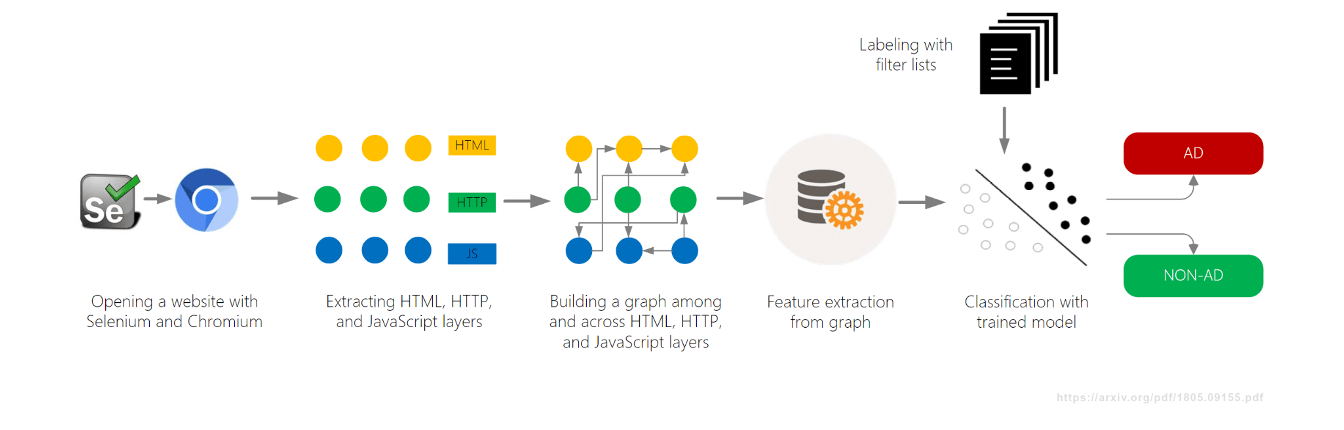
Otro proyecto de aprendizaje automático, AdGraph, fue desarrollado por el navegador Brave y presentado en 2019, también en el AFDS. Construyeron un grafo que rastreaba cómo todo en una página se conecta —DOM, red, JavaScript— y luego clasificaban los recursos basándose en el contexto.
AdGraph logró alta precisión al rastrear scripts hasta los servidores de anuncios, incluso con nombres aleatorios. Pero requería una integración profunda con el navegador y mantenimiento constante.
Idea principal: Tomar decisiones basadas en causalidad, no solo en patrones estáticos de URL.
Resultado: Precisión muy alta (~95–98%) y gran resistencia a la ofuscación.
Desafíos: Requería integración profunda con el navegador y mantenimiento continuo.
PERCIVAL de Brave
Objetivo: Bloquear imágenes publicitarias en tiempo real.
Método:
- Usó una red neuronal compacta (CNN) para clasificar imágenes
- Se integró directamente en la pipeline de renderizado del navegador
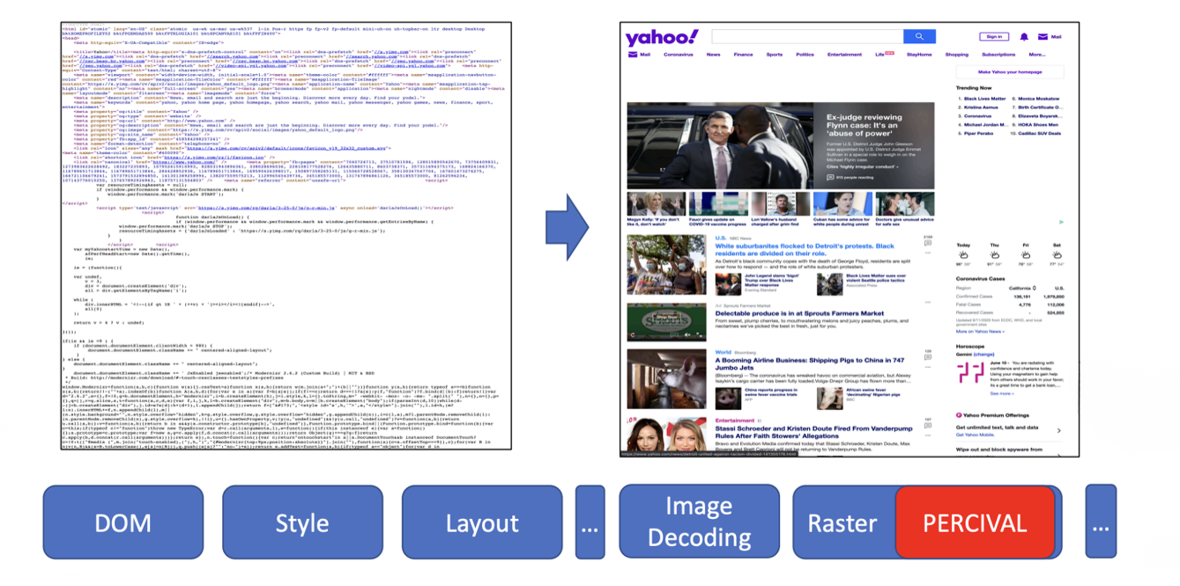
En 2020, Brave presentó otra técnica de aprendizaje automático llamada PERCIVAL, enfocada en bloquear imágenes de anuncios. Integraron una red neuronal compacta directamente en la pipeline de renderizado del navegador para clasificar imágenes mientras eran cargadas. Los resultados fueron impresionantes: alcanzaron un 97% de precisión analizando el contenido visual. Pero también tenía limitaciones —era vulnerable a imágenes adversarias y solo funcionaba para anuncios basados en imágenes.
Idea principal: Analizar el contenido visual de la imagen, no solo la URL o metadatos.
Resultado: ~97% de precisión con bajo impacto en el renderizado.
Desafíos: Vulnerable a imágenes adversarias; limitado a anuncios basados en imagen.
AutoFR (investigación académica)
Objetivo: Generar automáticamente reglas de filtro desde cero.
Método:
- Usó aprendizaje por refuerzo (sistema de prueba y error) para poner a prueba reglas
- Analizó el contenido de la página para evitar romper el sitio
Además de los esfuerzos de la industria, investigadores académicos también buscaron mejores soluciones. Un proyecto interesante fue AutoFR, cuyo objetivo era generar reglas de filtro automáticamente.
AutoFR fue presentado por Hieu Van Le en el AFDS 2022 y AFDS 2023.
Generaba patrones de URL y selectores CSS, los probaba y aprendía de los resultados, evitando romper el sitio. Los resultados fueron bastante impresionantes: AutoFR alcanzó un 86 % de eficacia (comparado con EasyList), con reglas generadas en minutos.
Idea principal: Generación automatizada de reglas con conciencia de quiebre del sitio.
Resultado: ~86 % de eficacia en el bloqueo; reglas generadas en minutos.
SINBAD (investigación académica)
Objetivo: Detectar e identificar quiebres de sitios causados por el bloqueo de anuncios.
Método:
- Usó “saliency web” para identificar elementos visualmente importantes
- Comparó versiones de la página con y sin bloqueador para encontrar qué se rompió
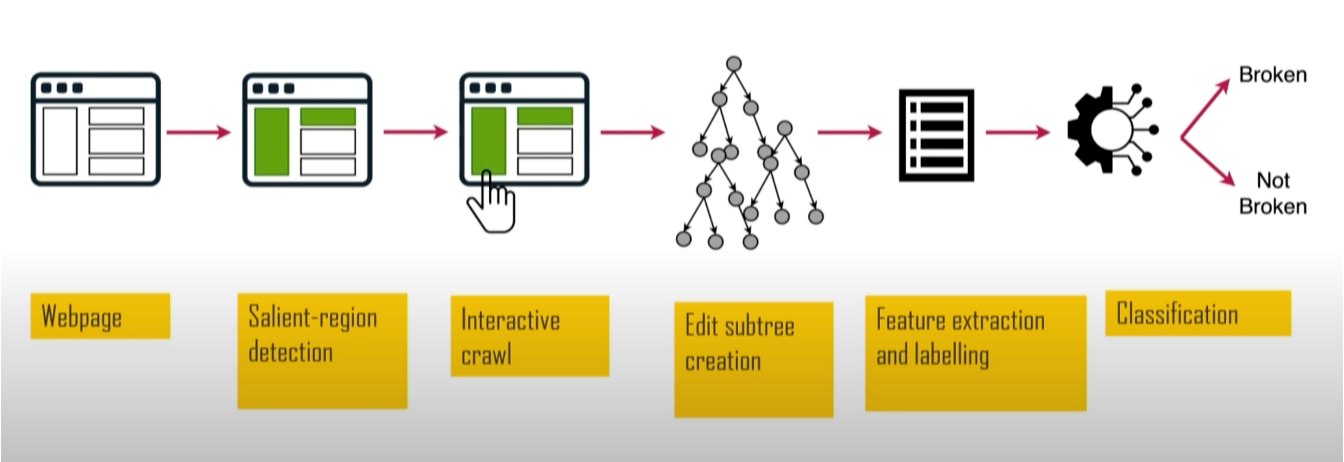
Otro proyecto académico fue SINBAD. Se enfocó en detectar cuando las reglas de filtro rompen sitios. Este proyecto fue valioso porque el rompimiento de sitios es una de las principales razones por las que los usuarios abandonan los bloqueadores de anuncios. Fue presentado en el AFDS 2023 por Sandra Siby del Imperial College London (en ese entonces).
Analizando tamaño, posición y contraste, identificaba elementos visualmente prominentes, como encabezados y botones, y luego verificaba si hubo ruptura. SINBAD alcanzó alta precisión en la detección de quiebres, con reportes específicos que mostraban exactamente qué se rompió y qué reglas causaron el problema.
Idea principal: Enfocarse en el impacto visible para detectar y corregir problemas más rápido.
Resultado: Mayor precisión en detección de quiebres, con reportes claros y accionables.
Resumen: por qué el machine learning no dominó
Entonces, vimos todos estos experimentos y proyectos de investigación. Pero aquí está el punto: a pesar de todo ese trabajo, ninguna de estas herramientas basadas en aprendizaje automático ganó adopción amplia. Así que surge la pregunta lógica: ¿por qué el machine learning no reemplazó los filtros?
Varias razones:
- Estándar muy alto: Las listas de filtros curadas por humanos son extremadamente eficaces y maduras. Igualarlas no es sencillo.
- Alto costo: Crear y mantener grandes datasets de alta calidad es caro, mientras que la mayoría de las listas son mantenidas por la comunidad de forma gratuita.
- Evasión: Modelos especializados pueden ser vulnerables a ataques adversarios.
En resumen: construir modelos especializados desde cero es lento, caro e inflexible. Por eso el ML todavía no despega y seguimos dependiendo de las buenas y viejas listas de filtros. ¿Pero está a punto de cambiar?
Llegan los LLMs: grandes, costosos… pero diferentes
Y aquí es donde entran los Large Language Models (LLMs), que están cambiando el mundo. ¿Podrían también cambiar el bloqueo de anuncios? Veamos cómo se pueden usar los LLMs en extensiones de navegador. Pero primero, déjame presentar brevemente algunas características clave que definen a los LLMs.
Repensando el bloqueo con LLMs: El poder del prototipado rápido
Los Large Language Models (LLMs) aún son un desarrollo reciente, pero su progreso ha sido sorprendentemente rápido. Ahora están ampliamente disponibles mediante APIs, permitiendo que los desarrolladores integren capacidades basadas en LLM en sus productos con mínimo esfuerzo. Muchos modelos existen tanto en versiones en la nube como locales, ofreciendo flexibilidad según las necesidades del usuario.
Las capacidades de los LLMs van desde generar texto de alta calidad hasta analizar datos, crear imágenes y videos, escribir código y apoyar flujos de trabajo complejos. Esto los hace valiosos en muchas industrias y altamente demandados. Pero no todo es perfecto —ejecutarlos o acceder a ellos puede ser caro, especialmente a gran escala, lo que limita su adopción en muchos casos.
Pero lo más importante es que los LLMs permiten probar ideas muy rápido. Así que, por fin, mostraré mis experimentos aplicando LLMs al bloqueo de anuncios en extensiones de navegador.
Experimento 1: bloqueo por significado
La idea de mi primer experimento fue ver si un LLM podía distinguir diferentes tipos de contenido en tiempo real.
La idea:
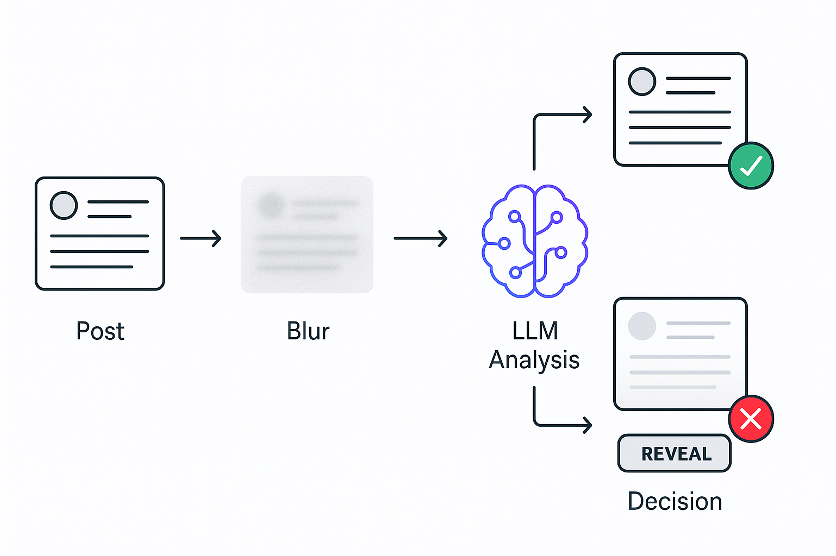
- Desenfocar las publicaciones inmediatamente
- El LLM analiza el contenido
- Revelar si es seguro o mantenerlo desenfocado si no lo es
Decidí probar en el feed de X. Tomaba el código de cada publicación y lo enviaba a un LLM, preguntando si era sobre política. Como los LLM son un poco lentos, desenfocaba todo de inmediato, lo analizaba y luego revelaba lo seguro.
¡Y funcionó!
Lo cual demuestra que una nueva forma semántica de filtrar contenido es posible. Y prototipé toda la extensión en solo unas horas —algo que habría tomado meses con ML tradicional.
Aquí tienes una demostración rápida:
Aquí puedes ver cómo funciona. La publicación aparece, se desenfoca de inmediato, el LLM analiza y luego revela si es segura o la mantiene oculta si no lo es. Los usuarios pueden revelar manualmente cualquier publicación desenfocada.
Mientras experimentaba en X, noté que algunas publicaciones no se bloqueaban porque estaban compuestas principalmente de imágenes. Eso me llevó al segundo experimento.
Experimento 2: bloqueo por significado visual
En este experimento, voy a enseñar al bloqueador a “ver”.
La idea:
- Desenfocar publicaciones inmediatamente
- Un LLM con visión analiza la captura de pantalla de la publicación
- Revelar si es segura o mantener desenfocada si no lo es
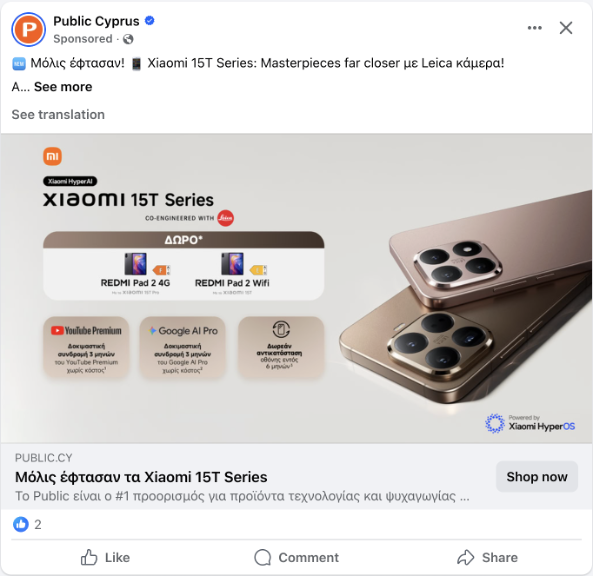
Las publicaciones suelen tener muy poco texto. Aquí tienes un ejemplo del problema: una publicación de Facebook con casi nada de texto, solo una imagen.
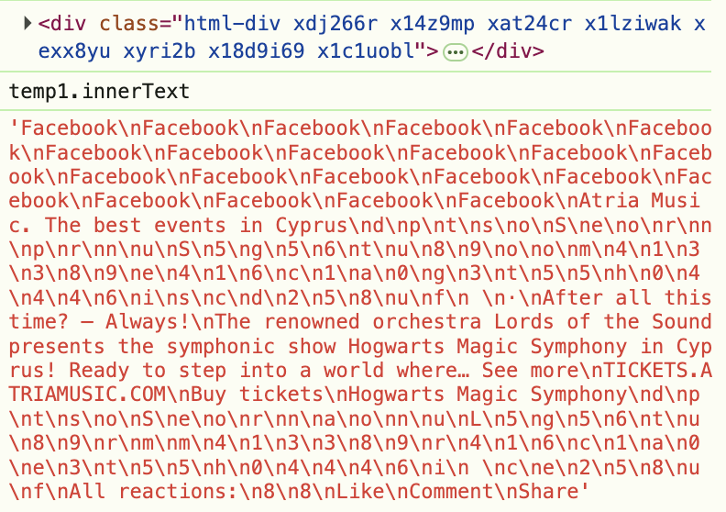
Pero no se trata solo de publicaciones sin texto. Incluso cuando lo hay, los sitios lo esconden usando HTML ofuscado. Por ejemplo, observa este screenshot en las herramientas de desarrollador —la etiqueta "Patrocinado" está escondida en HTML aleatorio.
Por eso debemos dejar de analizar el código y empezar a analizar lo que los usuarios realmente ven. La idea es similar al primer experimento, pero ahora analizamos no el código, sino lo que el usuario ve en la página. Así que tomamos una captura, la enviamos a un LLM con visión y preguntamos si trata sobre política.
¡Y funcionó nuevamente! La idea central quedó prototipada en alrededor de una hora. Pero luego vino el verdadero desafío: tomar capturas de pantalla desde una extensión resultó un dolor de cabeza.
Déjame explicar por qué. Una aproximación que intenté fue la Debugger API. Esta API permite capturar cualquier elemento, incluso fuera del viewport (la parte visible), pero hace que la página parpadee, lo cual puede resultar molesto para los usuarios. Mira la demostración:
La otra opción fue usar chrome.tabs.captureVisibleTab, la API estándar del navegador para capturas. Esta no produce parpadeo, pero solo captura lo visible en pantalla, y Chrome limita cuántas puedes tomar por segundo.
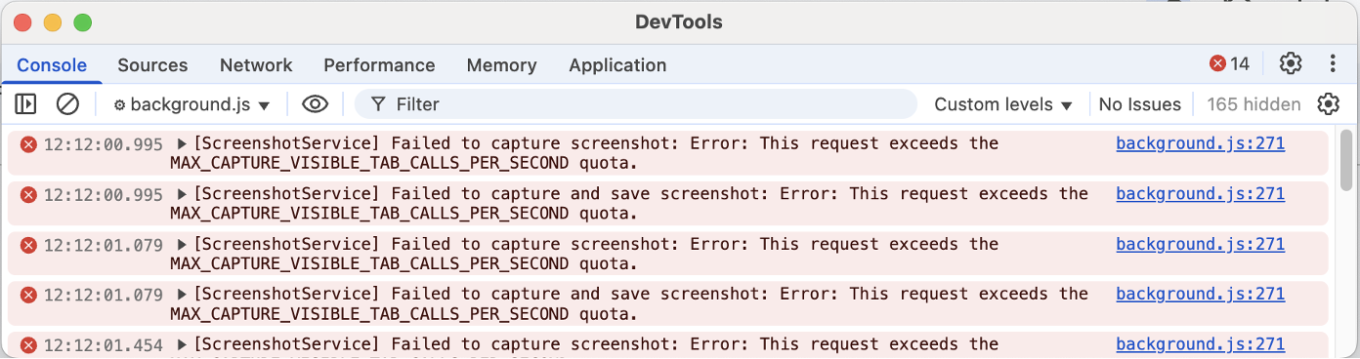
Así que si tienes múltiples elementos que analizar, debes esperar, y solo puedes checar publicaciones ya visibles.
Estos experimentos demostraron que los LLMs pueden analizar publicaciones y decidir si deben bloquearse. ¿Significa eso que podemos reemplazar por completo las listas de filtros? La respuesta es no —aún las necesitamos para saber qué verificar. Una página web tiene miles de elementos, y analizarlos todos sería lento y caro.
Experimento 3: extendiendo listas de filtros
Si aún necesitamos saber qué elementos revisar, el siguiente paso lógico es conectar los LLM con las listas de filtros y generalizar el poder de los LLM en una herramienta reutilizable para autores de listas de filtros. Pero el problema es que escribir una nueva extensión personalizada para cada tarea semántica no es escalable: necesitamos una solución más genérica.
La inspiración: la pseudoclase CSS extendida :contains.
La pregunta: ¿y si pudiéramos verificar el significado, no solo el texto?
El resultado: tres nuevas pseudoclases experimentales:
selector:contains-meaning-embedding('criteria')
selector:contains-meaning-prompt('criteria')
selector:contains-meaning-vision('criteria')
Para crear esta solución genérica, me inspiré en la biblioteca Extended CSS de AdGuard. Extended CSS es una biblioteca de JavaScript que añade pseudoclases adicionales, ampliando lo que es posible más allá del CSS nativo.
Incluye la pseudoclase :contains(), que oculta elementos que contienen texto específico. Decidí que podríamos actualizar este enfoque para verificar significado semántico en lugar de solo palabras clave. Esto llevó a tres prototipos: embedding, prompt y vision.
:contains-meaning-embedding
Cómo funciona: compara la similitud entre el texto y los criterios
Pros: muy rápido y barato
Contras: requiere ajustar umbrales y puede tener dificultades con varios idiomas
Empezamos con :contains-meaning-embedding. Esta regla usa modelos de embedding, que transforman el texto en números que representan su significado. Calculamos la similitud entre el texto del elemento y los criterios, y decidimos si coinciden. La ventaja es que es rápido y barato, especialmente con caché. La desventaja es que requiere ajustar umbrales y puede tener problemas en entornos multilingües.
:contains-meaning-prompt
Cómo funciona: le pregunta al LLM si el contenido coincide con los criterios
Pros: más preciso, sin umbrales, independiente del idioma
Contras: más lento y más costoso
Luego tenemos :contains-meaning-prompt. Estas reglas usan una API sencilla basada en prompts, donde simplemente preguntamos si el contenido de un elemento coincide o no con los criterios. Es más preciso, no requiere umbrales y funciona en varios idiomas. La desventaja es que es más lento y costoso que los embeddings.
:contains-meaning-vision
Cómo funciona: le pregunta al LLM si el screenshot coincide con los criterios
Pros: detecta elementos que el texto y los embeddings no pueden
Contras: UX compleja
El último método es :contains-meaning-vision. Toma capturas de pantalla de los elementos seleccionados y le pregunta a un LLM con visión si la imagen coincide con los criterios. Después, funciona igual que :contains-meaning-prompt. Su gran ventaja es que detecta contenido visual que los métodos basados en texto no pueden ver. La desventaja es una UX compleja, con posible parpadeo visual.
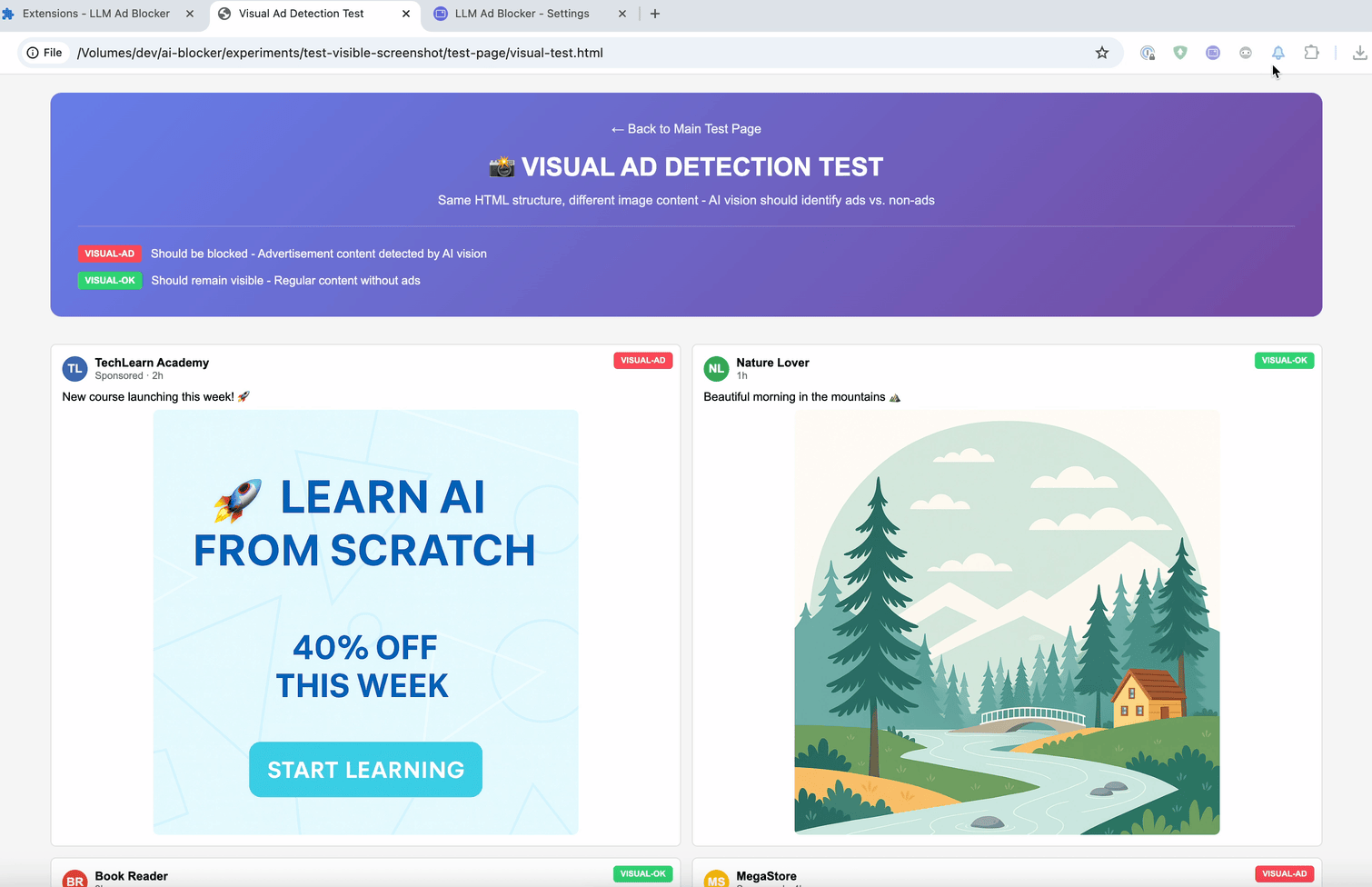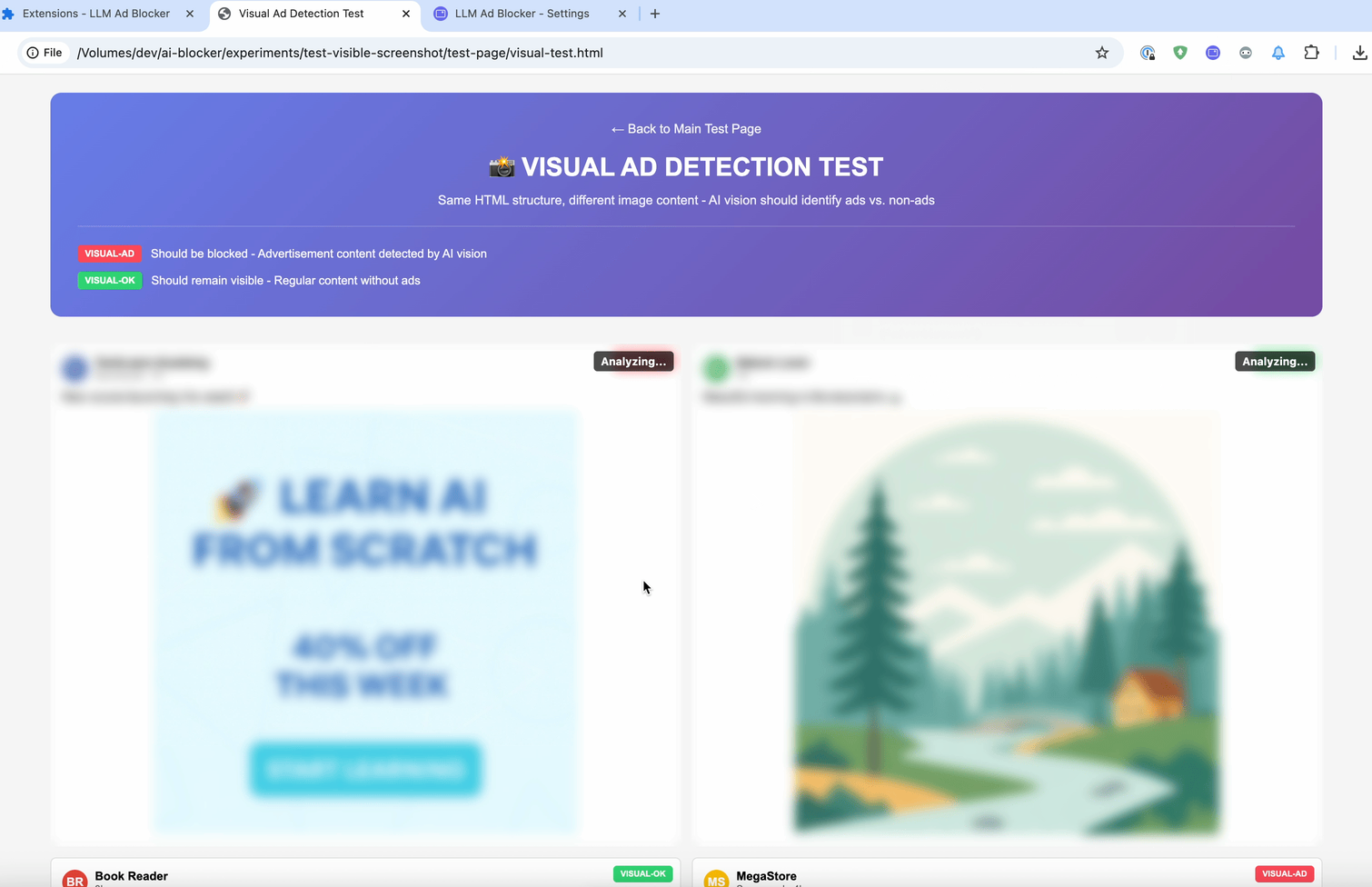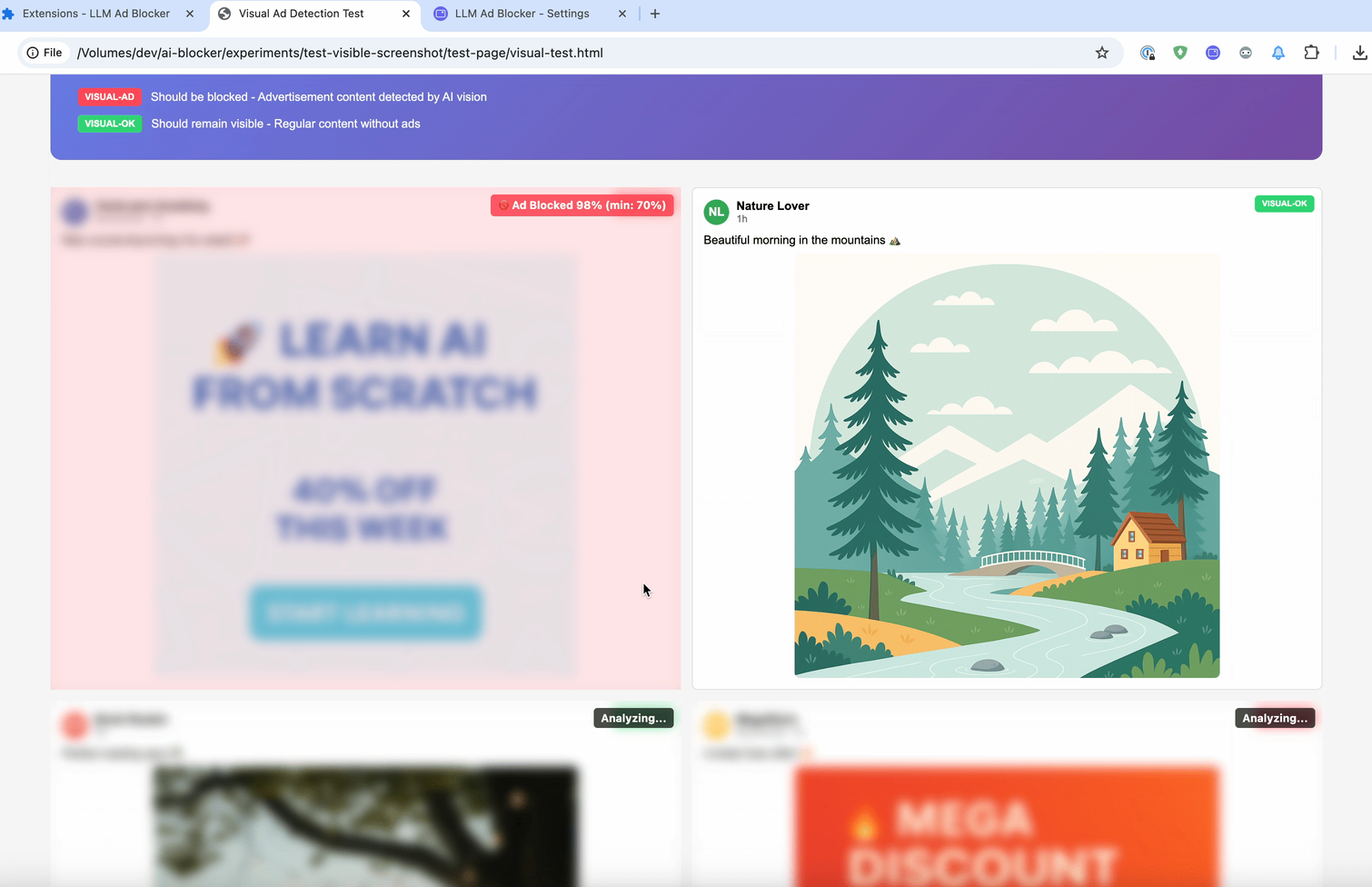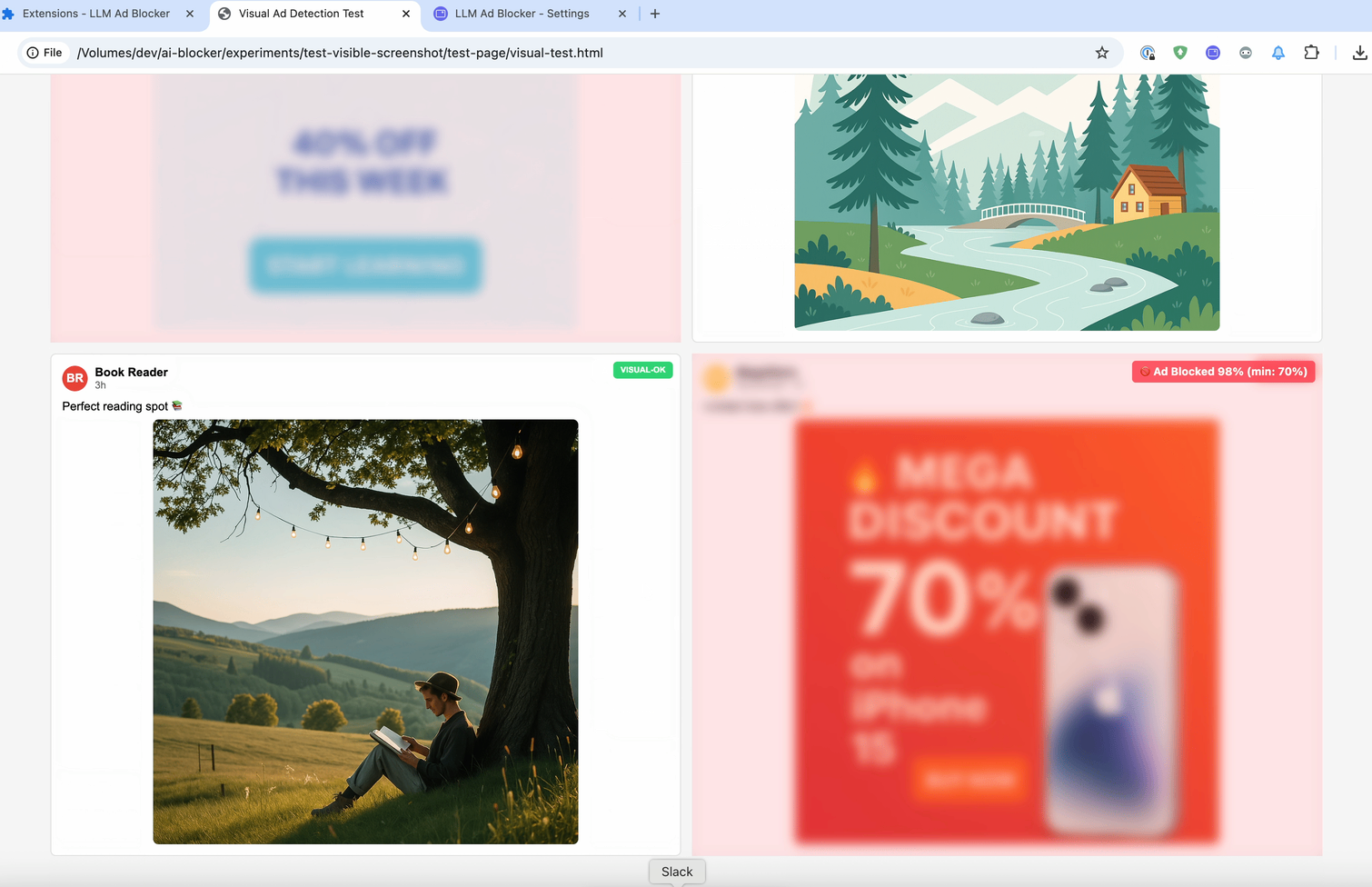
Estas tres reglas pueden ofrecer a los desarrolladores de filtros una herramienta flexible. Pueden elegir: la velocidad del embedding, la precisión del prompt o la percepción visual del vision. Para reducir la latencia del análisis, una solución es desenfocar primero los elementos y luego mostrarlos, o simplemente mantenerlos ocultos.
Análisis de desempeño y costo
Ahora que tenemos estos tres prototipos, surge la pregunta más importante: ¿son prácticos? ¿Realmente funcionarían en producción? Para responderla, analicé el desempeño y el costo de cada enfoque.
Embeddings
Empezando con embeddings. Inicialmente usé el modelo en la nube de OpenAI y, siendo sincero, los resultados no fueron muy buenos. Pero luego decidí probar un modelo pequeño local —y el resultado me sorprendió. Fue más rápido, completamente gratuito y alcanzó un 100% de precisión en mis pruebas. Esto muestra que, para ciertas tareas, los modelos locales pequeños pueden superar a las grandes APIs en la nube.

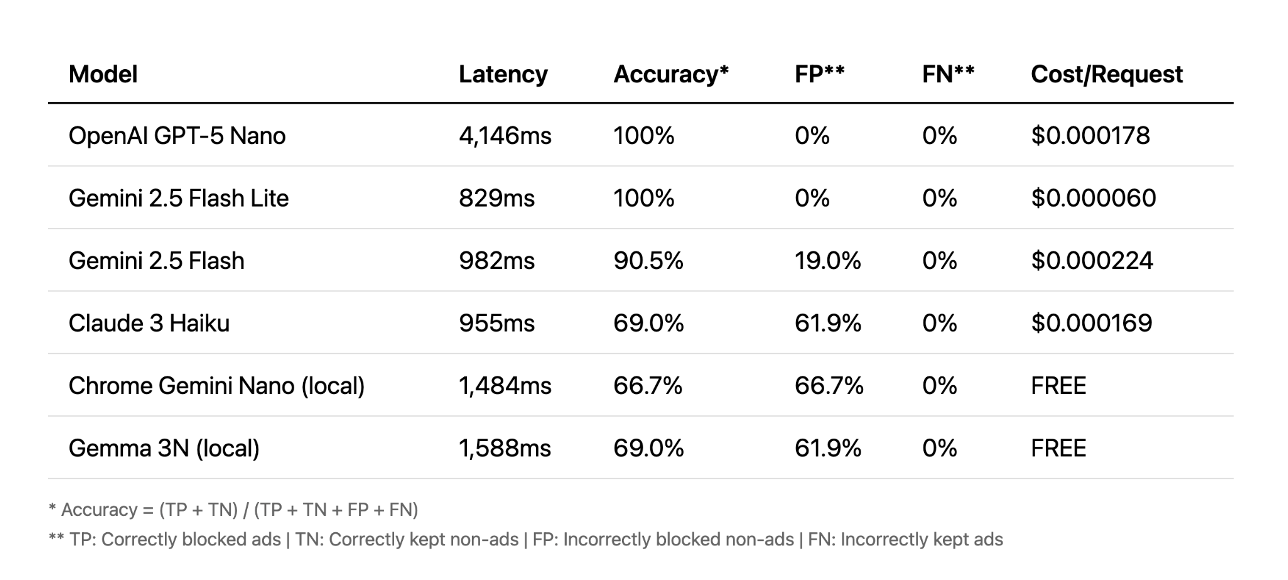
Prompts
Pasemos a los prompts. Aquí la situación es distinta. Las APIs en la nube tuvieron mejor desempeño; algunas lograron 100% de precisión en menos de un segundo. Otras tardaron más de cuatro segundos, lo cual es demasiado lento para una buena experiencia de usuario. En este caso, los modelos locales simplemente no lograron llegar al nivel de precisión de los modelos en la nube.
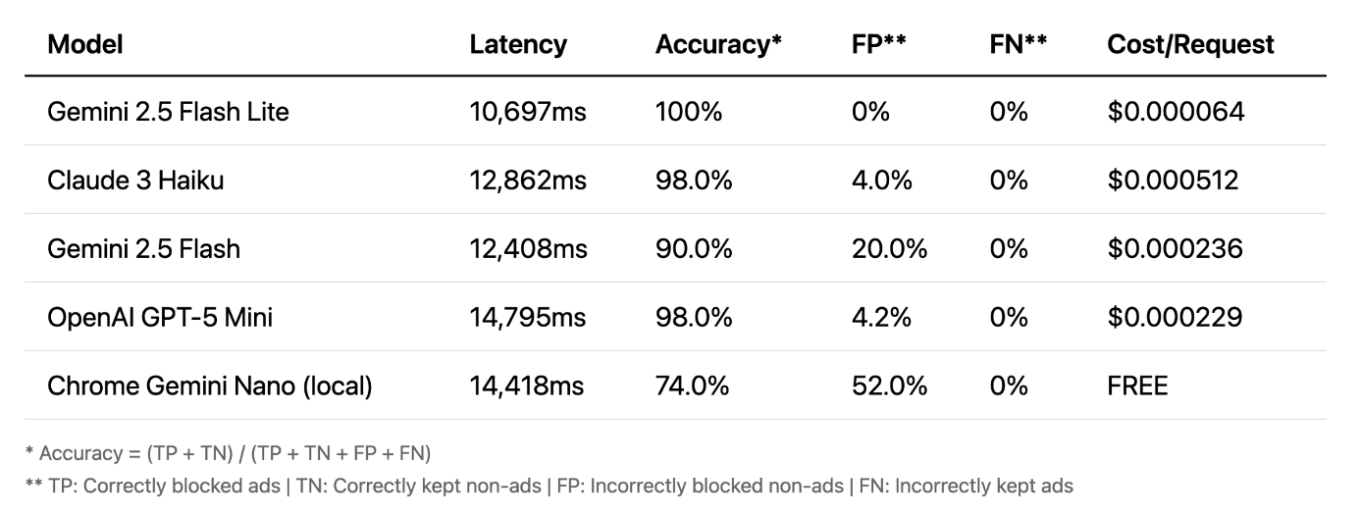
Vision
Y finalmente, vision. Aquí es donde las cosas se ponen realmente interesantes. La precisión es muy alta — incluso los modelos locales se desempeñan bien. Vision suele ser el método más preciso. Su gran ventaja es que trabaja con imágenes, no con texto, detectando anuncios que los otros métodos no ven. Pero hay una desventaja importante: la latencia. Un retraso de 10 a 15 segundos no es práctico para bloqueo en tiempo real.
Comparación de los métodos
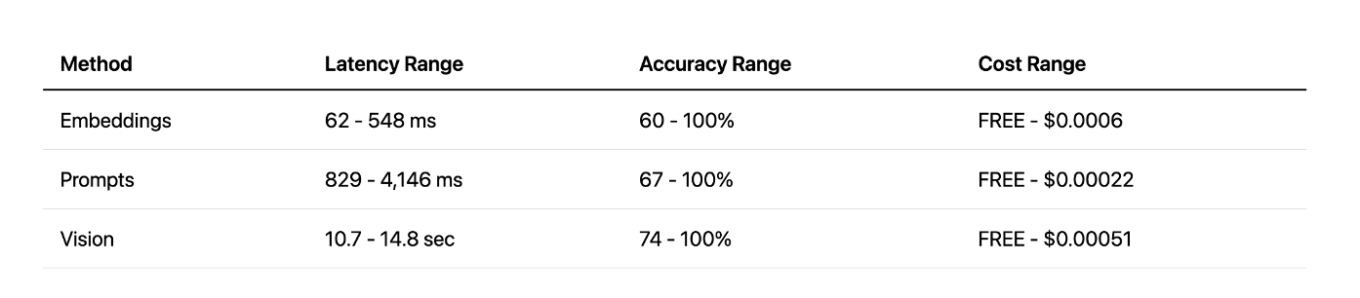
Comparando todos los métodos, vision ofrece excelente precisión, pero con una latencia demasiado alta. El enfoque basado en prompts ofrece un buen equilibrio entre velocidad y precisión, especialmente con APIs en la nube. Y los embeddings locales fueron una sorpresa agradable: muy rápidos y efectivos, aunque solo para tareas específicas. Al final, cada método tiene sus fortalezas y debilidades.
El futuro de este enfoque
Vision: demasiado lenta por ahora, pero debería mejorar con el tiempo
Embeddings: poco prácticos en extensiones, ideales si se integran al navegador
Prompts con LLMs locales: experimentales, requieren mejor precisión
¿Qué significa esto para el futuro? En mi opinión, vision sigue siendo demasiado lenta por el momento. Los embeddings no son muy prácticos en extensiones de navegador, pero podrían funcionar bien como una API nativa del propio navegador. Y los prompts de LLMs locales parecen ser el camino más prometedor para un experimento real y utilizable con la Prompt API de Chrome. También existe el desafío de mejorar la experiencia del usuario; el enfoque actual de desenfocar elementos no es ideal. Con modelos más rápidos, podríamos reducir el tiempo de desenfoque, o incluso crear una solución completamente nueva.
¿Qué aprendimos?
Primero, los LLM nos permiten ir más allá de la simple coincidencia de patrones y realmente entender el significado del contenido web, abriendo una nueva y poderosa aproximación semántica a la filtración.
Segundo, los LLM permiten una prototipación extremadamente rápida. Ideas que antes requerían meses de ingeniería ahora se pueden probar en cuestión de horas. Aunque aún hay retos prácticos, este nuevo enfoque nos permite replantear lo que es posible en el mundo del filtrado de contenido.
Espero que esto te haya dado una nueva perspectiva sobre la filtración de contenido. Puedes probar todo lo que mencioné en este artículo — solo descarga AI AdBlocker desde la Chrome Store.
El código fuente completo también está disponible en GitHub. ¡No dudes en contactarme si tienes preguntas o sugerencias!
















































