Cómo crear tus propios filtros de anuncios
En este artículo, explicamos cómo escribir reglas de filtrado personalizadas para usar en los productos de AdGuard. Para probar tus reglas, puedes descargar la app AdGuard
Un filtrado es un conjunto de reglas de filtrado aplicadas a contenido específico, como banners o ventanas emergentes. AdGuard tiene una lista de filtros estándar creados por nuestro Equipo. We constantly improve and update them, striving to meet the needs of most of our users.
At the same time, AdGuard allows you to create your own custom filters using the same types of rules that we have in our filters.
To describe the syntax of our filtering rules, we use Augmented BNF for Syntax Specifications, but we do not always strictly follow this specification.
Originally, the AdGuard's syntax was based on the syntax of Adblock Plus rules. Later, we extended it with new types of rules for better ad filtering. Some parts of this article about the rules common both to AdGuard and ABP were taken from the Adblock Plus guide on how to write filters.
Comments
Any line that starts with an exclamation mark is a comment. In the list of rules it is displayed in gray color. AdGuard will ignore this line, so you can write anything you want. Comments are usually placed above the rules and used to describe what a rule does.
For example:
! This is the comment. Below this line, there is an actual filtering rule.
||example.org^
Examples
Blocking by domain name

This rule blocks:
https://example.org/ad1.gifhttps://subdomain.example.org/ad1.gifhttps://ads.example.org:8000/
Esta regla no bloquea:
https://ads.example.org.us/ad1.gifhttps://example.com/redirect/https://ads.example.org/
Por defecto, tales reglas no funcionan para las peticiones de documentos. Esto significa que la regla ||example.org^ bloqueará una solicitud realizada a example.org cuando intentes navegar a este dominio desde otro sitio web, pero si escribes example.org en la barra de direcciones e intentas navegar hasta él, el sitio web se abrirá. Para bloquear la Petición de documento, necesitarás usar una regla con el $document modificador: ||example.org^$document.
Bloqueando una dirección exacta

Esta regla bloquea:
https://example.org/
Esta regla no bloquea:
https://example.org/banner/img
Basic rule modifiers
El soporte de reglas de filtrado admite numerosos modificadores que permiten ajustar el comportamiento de la regla. Aquí hay un ejemplo de una regla con algunos modificadores simples.

Esta regla bloquea:
https://example.org/script.jsif this script is loaded fromexample.com.
Esta regla no bloquea:
https://example.org/script.jsse o script for carregado deexample.org.https://example.org/banner.pngporque não é um script.
Desbloqueo de una dirección

Esta regla desbloquea:
https://example.org/banner.pngeven if there is a blocking rule for this address.
Las reglas bloqueadas con el modificador $important pueden anular excepciones.
Desbloqueo de un sitio web completo

Esta regla desbloquea
- Deshabilita todas las reglas cosméticas en
example.com. - Desbloquea todas las peticiones enviadas desde este sitio web, incluso si hay reglas bloqueando estas peticiones.
Regla cosmética

Las reglas cosméticas se basan en el uso de un lenguaje especial llamado CSS, que todos los navegadores entienden. Básicamente, añade un nuevo estilo CSS al sitio web cuyo propósito es ocultar elementos particulares. You can learn more about CSS in general.
AdGuard extiende CSS y permite a los desarrolladores de filtrado manejar casos mucho más complicados. Sin embargo, para utilizar estas reglas extendidas, es necesario dominar el CSS regular.
Selectores CSS populares
| Nombre | Selector CSS | Descripción |
|---|---|---|
| Selector de ID | #banners | Coincide con todos los elementos con el atributo id igual a banners.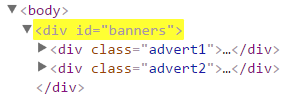 |
| Class selector | .banners | Matches all elements with class attribute containing banners.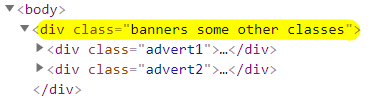 |
| Attribute selector | div[class="banners"] | Matches all div elements with class attribute exactly equal to banners.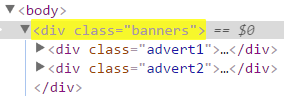 |
| Selector de subcadenas de atributos | div[class^="advert1"] | Matches all div elements which class attribute starts with the advert1 string.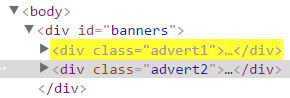 |
| Selector de subcadenas de atributos | div[class$="banners_ads"] | Matches all div elements which class attribute ends with the banners_ads string.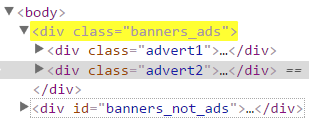 |
| Selector de subcadenas de atributos | a[href^="https://example.com/"] | Matches all links that are loaded from https://example.com/ domain.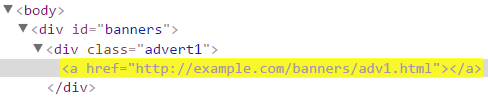 |
| Attribute selector | a[href="https://example.com/"] | Matches all links to exactly the https://example.com/ address.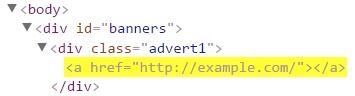 |
Restrictions and limitations
Trusted filters
Some rules can be used only in trusted filters. This category includes:
- filter lists created by the AdGuard team,
- custom filter lists installed as
trusted, - user rules.
Bloqueador de contenido AdGuard
AdGuard Content Blocker is an extension for Samsung and Yandex browsers that can be installed from Google Play. It is not to be confused with the fully functional AdGuard for Android that can only be downloaded from our website. Unfortunately, AdGuard Content Blocker capabilities are limited by what the browsers allow and they only support an old Adblock Plus filters syntax:
- Basic blocking rules with the following modifiers:
$domain,$third-party, content-type modifiers. - Basic exception rules with the following modifiers:
$document,$elemhide. - Basic element hiding rules with no extended CSS support.
Because of the limitations above AdGuard Content Blocker will not be mentioned in the compatibility notes.
SafariConverterLib
Safari Converter aims to support AdGuard filtering rules syntax as much as possible, but still there are limitations and shortcomings that are hard to overcome.
Basic (network) rules
Safari Converter supports a substantial subset of basic rules and certainly supports the most important types of those rules.
Supported with limitations
-
Regular expression rules are limited to the subset of regex that is supported by Safari.
-
$domain- domain modifier is supported with several limitations:- It's impossible to mix allowed and disallowed domains (like
$domain=example.org|~sub.example.org). Please upvote the feature request to WebKit to lift this limitation. - "Any TLD" (i.e.
domain.*) is not fully supported. In the current implementation the converter just replaces.*with top 100 popular TLDs. This implementation will be improved in the future. - Using regular expressions in
$domainis not supported, but it also will be improved in the future.
- It's impossible to mix allowed and disallowed domains (like
-
$denyallow- this modifier is supported via converting$denyallowrule to a set of rules (one blocking rule + several unblocking rules).Due to that limitation
$denyallowis only allowed when the rule also has$domainmodifier.- Generic rule
*$denyallow=x.com,image,domain=a.comwill be converted to:
*$image,domain=a.com@@||x.com$image,domain=a.com- Rule
/banner.png$image,denyallow=test1.com|test2.com,domain=example.orgwill be converted to:
/banner.png$image,domain=example.org@@||test1.com/banner.png$image,domain=example.org@@||test1.com/*/banner.png$image,domain=example.org@@||test2.com/banner.png$image,domain=example.org@@||test2.com/*/banner.png$image,domain=example.org- Rule without
$domainis not supported:$denyallow=a.com|b.com.
- Generic rule
-
$popup- popup rules are supported, but they're basically the same as$document-blocking rules and will not attempt to close the tab. -
Exception rules (
@@) disable cosmetic filtering on matching domains.Exception rules in Safari rely on the rule type
ignore-previous-rulesso to make it work we have to order the rules in a specific order. Exception rules without modifiers are placed at the end of the list and therefore they disable not just URL blocking, but cosmetic rules as well.This limitation may be lifted if #70 is implemented.
-
$urlblock,$genericblockis basically the same as$document, i.e. it disables all kinds of filtering on websites.These limitations may be lifted when #69 and #71 are implemented.
-
$contentmakes no sense in the case of Safari since HTML filtering rules are not supported so it's there for compatibility purposes only. Rules with$contentmodifier are limited todocumentresource type. -
$specifichideis implemented by scanning existing element hiding rules and removing the target domain from theirif-domainarray.$specifichiderules MUST target a domain, i.e. be like this:||example.org^$specifichide. Rules with more specific patterns will be discarded, i.e.||example.org/path$specifichidewill not be supported.$specifichiderules only cover rules that target the same domain as the rule itself, subdomains are ignored. I.e. the rule@@||example.org^$specifichidewill disableexample.org##.banner, but will ignoresub.example.org##.banner. This limitation may be lifted if #72 is implemented.
-
urlblock,genericblock,generichide,elemhide,specifichide, andjsinjectmodifiers can be used only as a single modifier in a rule. This limitation may be lifted in the future: #73. -
$websocket(fully supported starting with Safari 15). -
$ping(fully supported starting with Safari 14).
Not supported
$app$header$method$strict-first-party(to be supported in the future: #64)$strict-third-party(to be supported in the future: #65)$to(to be supported in the future: #60)$extension$stealth$cookie(partial support in the future: #54)$csp$hls$inline-script$inline-font$jsonprune$xmlprune$network$permissions$redirect$redirect-rule$referrerpolicy$removeheader$removeparam$replace$urltransform
Cosmetic rules
Safari Converter supports most of the cosmetic rules although only element hiding rules with basic CSS selectors are supported natively via Safari Content Blocking, everything else needs to be interpreted by an additional extension.
Limitations of cosmetic rules
-
Specifying domains is subject to the same limitations as the
$domainmodifier of basic rules. -
Non-basic rules modifiers are supported with some limitations:
$domain- the same limitations as everywhere else.$path- supported, but if you use regular expressions, they will be limited to the subset of regex that is supported by Safari.$url- to be supported in the future: #68
Script/scriptlet rules
Safari Converter fully supports both script rules and scriptlet rules. However, these rules can only be interpreted by a separate extension.
For scriptlet rules, it is very important that they are run as early as possible when the page loads. The reason for that is that it's important to run them before the page scripts. Unfortunately, with Safari there will always be a slight delay that can decrease the quality of blocking.
HTML filtering rules
HTML filtering rules are not supported and will not be supported in the future. Unfortunately, Safari does not provide necessary technical capabilities to implement them.
Reglas básicas
The most simple rules are so-called Basic rules. They are used to block requests to specific URLs. Or to unblock it, if there is a special marker "@@" at the beginning of the rule. The basic principle for this type of rules is quite simple: you have to specify the address and additional parameters that limit or expand the rule scope.
Basic rules for blocking requests are applied only to sub-requests. That means they will not block the loading of the page unless it is explicitly specified with a $document modifier.
Browser detects a blocked request as completed with an error.
Rules shorter than 4 characters are considered incorrect and will be ignored.
Basic rule syntax
rule = ["@@"] pattern [ "$" modifiers ]
modifiers = [modifier0, modifier1[, ...[, modifierN]]]
pattern— an address mask. Every request URL is collated to this mask. In the template, you can also use the special characters described below. Note that AdGuard truncates URLs to a length of 4096 characters in order to speed up matching and avoid issues with ridiculously long URLs.@@— a marker that is used in rules of exception. To turn off filtering for a request, start your rule with this marker.modifiers— parameters that "clarify" the basic rule. Some of them limit the rule scope and some can completely change they way it works.
Special characters
*— a wildcard character. It is used to represent any set of characters. This can also be an empty string or a string of any length.||— an indication to apply the rule to the specified domain and its subdomains. With this character, you do not have to specify a particular protocol and subdomain in address mask. It means that||stands forhttps://*.,https://*.,ws://*.,wss://*.at once.^— a separator character mark. Separator character is any character, but a letter, a digit, or one of the following:_-.%. In this example separator characters are shown in bold:http://example.com/?t=1&t2=t3. The end of the address is also accepted as separator.|— a pointer to the beginning or the end of address. The value depends on the character placement in the mask. For example, a ruleswf|corresponds tohttps://example.com/annoyingflash.swf, but not tohttps://example.com/swf/index.html.|https://example.orgcorresponds tohttps://example.org, but not tohttps://domain.com?url=https://example.org.
|, ||, ^ can only be used with rules that have a URL pattern. For example, ||example.com##.advert is incorrect and will be ignored by the blocker.
We also recommend to get acquainted with the Adblock Plus filter cheatsheet, for better understanding of how such rules should be made.
Regular expressions support
If you want even more flexibility in making rules, you can use Regular expressions instead of a default simplified mask with special characters.
Rules with regular expressions work more slowly, therefore it is recommended to avoid them or to limit their scope to specific domains.
If you want a blocker to determine a regular expression, the pattern has to look like this:
pattern = "/" regexp "/"
For example, /banner\d+/$third-party this rule will apply the regular expression banner\d+ to all third-party requests. Exclusion rule with regular expression looks like this: @@/banner\d+/.
AdGuard Safari and AdGuard for iOS do not fully support regular expressions because of Content Blocking API restrictions (look for "The Regular expression format" section).
Wildcard support for TLD (top-level domains)
Wildcard characters are supported for TLDs of the domains in patterns of cosmetic, HTML filtering and JavaScript rules.
For cosmetic rules, e.g. example.*##.banner, multiple domains are matched due to the part .*, i.e. example.com, sub.example.net, example.co.uk, etc.
For basic rules the described logic is applicable only for the domains specified in $domain modifier, e.g. ||*/banners/*$image,domain=example.*.
In AdGuard for Windows, Mac, Android, and AdGuard Browser Extension rules with wildcard .* match any public suffix (or eTLD). But for AdGuard for Safari and iOS the supported list of top-level domains is limited due to Safari limitations.
Rules with wildcard for TLD are not supported by AdGuard Content Blocker.
Basic rule examples
-
||example.com/ads/*— a simple rule, which corresponds to addresses likehttps://example.com/ads/banner.jpgand evenhttps://subdomain.example.com/ads/otherbanner.jpg. -
||example.org^$third-party— this rule blocks third-party requests toexample.organd its subdomains. -
@@||example.com$document— general exception rule. It completely disables filtering forexample.comand all subdomains. There is a number of modifiers which can be used in exception rules. For more details, please follow the link below.
Basic rule modifiers
The features described in this section are intended for experienced users. They extend capabilities of "Basic rules", but in order to use them you need to have a basic understanding of the way your browser works.
You can change the behavior of a "basic rule" by using additional modifiers. Modifiers should be located in the end of the rule after a $ sign and be separated by commas.
Example:
||domain.com^$popup,third-party
Basic modifiers
The following modifiers are the most simple and frequently used. Basically, they just limit the scope of rule application.
| Modifier \ Products | CoreLibs apps | AdGuard para Chromium | AdGuard para Chrome MV3 | AdGuard para Firefox | AdGuard para iOS | AdGuard Mini for Mac | Bloqueador de contenido AdGuard |
|---|---|---|---|---|---|---|---|
| $app | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| $denyallow | ✅ | ✅ | ✅ | ✅ | ❌ | ✅ | ❌ |
| $domain | ✅ | ✅ | ✅ *[1] | ✅ | ✅ *[1] | ✅ *[1] | ✅ |
| $header | ✅ | ✅ *[2] | ✅ *[2] | ✅ *[2] | ❌ | ❌ | ❌ |
| $important | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| $match-case | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| $method | ✅ | ✅ | ✅ | ✅ | ✅ *[2] | ✅ *[2] | ❌ |
| $popup | ✅ *[3] | ✅ | ✅ *[3] | ✅ | ✅ *[3] | ✅ *[3] | ❌ |
| $strict-first-party | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| $strict-third-party | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| $third-party | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ❌ |
- ✅ — totalmente compatible
- ✅ * — compatible, pero la confiabilidad puede variar o pueden ocurrir limitaciones; verifica la descripción del modificador para más detalles
- ❌ — not supported
$app
Este modificador te permite restringir la cobertura de la regla a una aplicación específica (o a una lista de aplicaciones). Esto puede no ser demasiado importante en Windows y Mac, pero es muy importante en los dispositivos móviles donde algunas de las reglas de filtrado deben ser específicas de la app.
- Android — utiliza el nombre del paquete de la app, por ejemplo,
org.example.app. - Windows — use the process name, e.g.
chrome.exe. - Mac — use the bundle ID or the process name, e.g.
com.google.Chrome.
For Mac, you can find out the bundle ID or the process name of the app by viewing the respective request details in the Filtering log.
Sintaxis
The modifier is a list of one or more expressions, each of which is matched against an application in a particular way depending on its type. These expressions are separated by the | symbol.
applications = ["~"] entry_0 ["|" ["~"] entry_1 ["|" ["~"]entry_2 ["|" ... ["|" ["~"]entry_N]]]]
entry_i = ( regular_app / wildcard_app / regexp )
regular_app— a regular application name (example.app). It corresponds to the specified application and is matched lexicographically.wildcard_app— an application name ending with a wildcard character*, such asorg.example.*orcom.ad*. It matches all applications whose names start with the specified prefix. Matching is done lexicographically.regexp— a regular expression that starts and ends with/. It works the same way as the basic URL rules, but the characters/,$,,, and|must be escaped with\.
Examples
||baddomain.com^$app=org.example.app— a rule to block requests that match the specified mask and are sent from theorg.example.appAndroid app.||baddomain.com^$app=org.example.app1|org.example.app2— the same rule but it works for bothorg.example.app1andorg.example.app2apps.
If you want the rule not to be applied to certain apps, start the app name with the ~ sign.
||baddomain.com^$app=~org.example.app— a rule to block requests that match the specified mask and are sent from any app except for theorg.example.app.||baddomain.com^$app=~org.example.app1|~org.example.app2— same as above, but now two apps are excluded:org.example.app1andorg.example.app2.
You can use wildcards in the $app modifier:
||baddomain.com^$app=org.example.*— applies to all apps whose package names start withorg.example.
You can use regular expressions in the $app modifier by enclosing them in forward slashes /.../. This allows for more flexible matching — for example, targeting a group of apps from the same publisher or matching complex patterns.
||baddomain.com^$app=/org\.example\.[a-z0-9_]+/— applies to all apps whose package name starts withorg.example(e.g.org.example.app1,org.example.utility, etc.).||baddomain.com^$app=/^org\.example\.app\$\|^org\.example\.[ab].*/— applies toorg.example.appand to any app whose package starts withorg.example.aororg.example.b.
The $app modifier supports combining all three types of entries — plain names, wildcards, and regular expressions — within the same rule, but it does not allow combining negated and non-negated expressions together.
||example.com^$app=org.example.app|org.example.*|/org\.example\.[a-z]+/— applies toorg.example.app, all matchingorg.example.*andorg.example.[a-z]+apps.
- Apps in the modifier value cannot include a wildcard inside the string , e.g.
$app=com.*.music. Use a regular expression instead:$app=/com\..*\.music/. - You cannot combine negated (
~) and non-negated expressions in the same$appmodifier — this would be ambiguous.
- Only AdGuard for Windows, Mac, Android are technically capable of using rules with
$appmodifier. - On Windows the process name is case-insensitive starting with AdGuard for Windows with CoreLibs v1.12 or later.
- Support for regular expressions and for combining different types of entries (plain names, wildcards, and regular expressions) in the
$appmodifier is available starting from CoreLibs v1.19 or later.
$denyallow
$denyallow modifier allows to avoid creating additional rules when it is needed to disable a certain rule for specific domains. $denyallow matches only target domains and not referrer domains.
Adding this modifier to a rule is equivalent to excluding the domains by the rule's matching pattern or to adding the corresponding exclusion rules. To add multiple domains to one rule, use the | character as a separator.
Ejemplos
Esta regla:
*$script,domain=a.com|b.com,denyallow=x.com|y.com
equivale a esto:
/^(?!.*(x.com|y.com)).*$/$script,domain=a.com|b.com
o a la combinación de estos tres:
*$script,domain=a.com|b.com
@@||x.com$script,domain=a.com|b.com
@@||y.com$script,domain=a.com|b.com
- El patrón de coincidencia de la regla no puede dirigirse a ningún dominio específico, por ejemplo, no puede comenzar con
||. - Los dominios en el valor del modificador no pueden ser negados, por ejemplo,
$denyallow=~x.com, o tener un TLD comodín, por ejemplo,$denyallow=x.*, o ser una expresión regular, por ejemplo,$denyallow=/\.(com\|org)/. $denyallowno se puede usar junto con$to. Se puede expresar con$toinvertido:$denyallow=a.com|b.comes equivalente a$to=~a.com|~b.com.
Las reglas que violen estas restricciones se consideran inválidas.
Las reglas con el modificador $denyallow no son compatibles con AdGuard para iOS, Safari y el Bloqueador de contenido AdGuard.
$domain
$domain limits the rule scope to requests made from the specified domains and their subdomains (as indicated by the Referer HTTP header).
Syntax
El modificador es una lista de una o más expresiones separadas por el símbolo |, cada una de las cuales se empareja con un dominio de una manera particular dependiendo de su tipo (ver más abajo).
domains = ["~"] entry_0 ["|" ["~"] entry_1 ["|" ["~"]entry_2 ["|" ... ["|" ["~"]entry_N]]]]
entry_i = ( regular_domain / any_tld_domain / regexp )
regular_domain— a regular domain name (domain.com). Corresponds the specified domain and its subdomains. It is matched lexicographically.any_tld_domain— a domain name ending with a wildcard character as a public suffix, e.g. forexample.*it isco.ukinexample.co.uk. Corresponds to the specified domain and its subdomains with any public suffix. It is matched lexicographically.regexp— a regular expression, starts and ends with/. The pattern works the same way as in the basic URL rules, but the characters/,$,,, and|must be escaped with\.
Rules with $domain modifier as regular_domain are supported by all AdGuard products.
Examples
Just $domain:
||baddomain.com^$domain=example.orgblocks requests that match the specified mask, and are sent from domainexample.orgor its subdomains.||baddomain.com^$domain=example.org|example.com— the same rule, but it works for bothexample.organdexample.com.
If you want the rule not to be applied to certain domains, start a domain name with ~ sign.
$domain and negation ~:
||baddomain.com^$domain=example.orgblocks requests that match the specified mask and are sent from theexample.orgdomain or its subdomains.||baddomain.com^$domain=example.org|example.com— the same rule, but it works for bothexample.organdexample.com.||baddomain.com^$domain=~example.orgblocks requests matching the pattern sent from any domain exceptexample.organd its subdomains.||baddomain.com^$domain=example.org|~foo.example.orgblocks requests sent fromexample.organd its subdomains, except the subdomainfoo.example.org.||baddomain.com^$domain=/(^\|.+\.)example\.(com\|org)\$/blocks requests sent fromexample.organdexample.comdomains and all their subdomains.||baddomain.com^$domain=~a.com|~b.*|~/(^\|.+\.)c\.(com\|org)\$/blocks requests sent from any domains, excepta.com,bwith any public suffix (b.com,b.co.uk, etc.),c.com,c.org, and their subdomains.
$domain modifier matching target domain:
In some cases the $domain modifier can match not only the referrer domain, but also the target domain.
This happens when the rule has one of the following modifiers: $cookie, $csp, $permissions, $removeparam.
These modifiers will not be applied if the referrer matches a rule with $domain that explicitly excludes the referrer domain, even if the target domain also matches the rule.
Examples
*$cookie,domain=example.org|example.comwill block cookies for all requests to and fromexample.organdexample.com.*$document,domain=example.org|example.comwill block requests only fromexample.organdexample.com, but not to them.
In the following examples it is implied that requests are sent from https://example.org/page (the referrer) and the target URL is https://targetdomain.com/page.
page$domain=example.orgwill be matched, as it matches the referrer domain.page$domain=targetdomain.comwill not be matched because it does not match the referrer domain.||*page$domain=targetdomain.com,cookiewill be matched because the rule contains$cookiemodifier despite the pattern||*pagemay match specific domains.page$domain=targetdomain.com|~example.org,cookiewill not be matched because the referrer domain is explicitly excluded.
$domain modifier limitations
In AdGuard for Chrome MV3, regexp and any_tld_domain entries and the $removeparam modifier are not supported.
AdGuard for iOS and AdGuard for Safari support the $domain modifier but have some limitations. For more details, see the SafariConverterLib section.
Rules with regexp in the $domain modifier are not supported by AdGuard for Safari and AdGuard for iOS.
Rules with regular expressions in the $domain modifier are supported by AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for Linux with CoreLibs v1.11 or later, and AdGuard Browser Extension with TSUrlFilter v3.0.0 or later.
In AdGuard for Windows, Mac and Android with CoreLibs v1.12 or later the $domain modifier can be alternatively spelled as $from.
$header
The $header modifier allows matching the HTTP response having a specific header with (optionally) a specific value.
Syntax
$header "=" h_name [":" h_value]
h_value = string / regexp
where:
h_name— required, an HTTP header name. It is matched case-insensitively.h_value— optional, an HTTP header value matching expression, it may be one of the following:string— a sequence of characters. It is matched against the header value lexicographically;regexp— a regular expression, starts and ends with/. The pattern works the same way as in the basic URL rules, but the characters/,$and,must be escaped with\.
The modifier part, ":" h_value, may be omitted. In that case, the modifier matches the header name only.
Examples
||example.com^$header=set-cookie:fooblocks requests whose responses have theSet-Cookieheader with the value matchingfooliterally.||example.com^$header=set-cookieblocks requests whose responses have theSet-Cookieheader with any value.@@||example.com^$header=set-cookie:/foo\, bar\$/unblocks requests whose responses have theSet-Cookieheader with value matching thefoo, bar$regular expression.@@||example.com^$header=set-cookieunblocks requests whose responses have aSet-Cookieheader with any value.
$header modifier limitations
-
The
$headermodifier can be matched only when headers are received. So if the request is blocked or redirected at an earlier stage, the modifier cannot be applied. -
In AdGuard Browser Extension, the
$headermodifier is only compatible with$csp,$removeheader(response headers only),$important,$badfilter,$domain,$third-party,$match-case, and content-type modifiers such as$scriptand$stylesheet. The rules with other modifiers are considered invalid and will be discarded. -
In AdGuard Browser Extension MV3, regular expressions in the
$headermodifier values are not supported.
Rules with the $header modifier are supported by AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for Linux with CoreLibs v1.11 or later, AdGuard Browser Extension with TSUrlFilter v3.0.0 or later, and AdGuard Browser Extension MV3 v5.3 or later.
$important
The $important modifier applied to a rule increases its priority over rules without the identical modifier. Even over basic exception rules.
Go to rules priorities for more details.
Examples
! blocking rule will block all requests despite of the exception rule
||example.org^$important
@@||example.org^
! if the exception rule also has `$important` modifier, it will prevail and requests won't be blocked
||example.org^$important
@@||example.org^$important
$match-case
This modifier defines a rule which applies only to addresses that match the case. Default rules are case-insensitive.
Examples
*/BannerAd.gif$match-case— this rule will blockhttps://example.com/BannerAd.gif, but nothttps://example.com/bannerad.gif.
Rules with the $match-case are supported by AdGuard for iOS and AdGuard for Safari with SafariConverterLib v2.0.43 or later.
All other products already support this modifier.
$method
This modifier limits the rule scope to requests that use the specified set of HTTP methods. Negated methods are allowed. The methods must be specified in all lowercase characters, but are matched case-insensitively. To add multiple methods to one rule, use the vertical bar | as a separator.
Examples
||evil.com^$method=get|headblocks only GET and HEAD requests toevil.com.||evil.com^$method=~post|~putblocks any requests toevil.comexcept POST or PUT.@@||evil.com$method=getunblocks only GET requests toevil.com.@@||evil.com$method=~postunblocks any requests toevil.comexcept POST.
-
In AdGuard for iOS and AdGuard Mini for Mac, the
$methodmodifier does not support negation. Therefore, rules such as$method=~getare not supported. -
Rules with a combination of negated and non-negated values are considered invalid. So, for example, the rule
||evil.com^$method=get|~headwill be ignored.
Rules with $method modifier are supported by AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for Linux with CoreLibs v1.12 or later, and AdGuard Browser Extension for Chrome, Firefox, and Edge with TSUrlFilter v2.1.1 or later.
In AdGuard for iOS (v4.5.15 or later) and AdGuard Mini for Mac (v2.1 or later), the $method modifier is supported with limitations.
$popup
AdGuard will try to close the browser tab with any address that matches a blocking rule with this modifier. Please note that not all the tabs can be closed.
Examples
||domain.com^$popup— if you try to go tohttps://domain.com/from any page in the browser, a new tab in which specified site has to be opened will be closed by this rule.
$popup modifier limitations
- The
$popupmodifier works best in AdGuard Browser Extension for Chromium-based browsers and Firefox. - In AdGuard for Chrome MV3 rules with the
$popupmodifier would not work, so we disable converting them to declarative rules. We will try to use them only in our TSUrlFilter engine and close new tabs programmatically. - In AdGuard for iOS and AdGuard for Safari,
$popuprules simply block the page right away. - In AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for Linux, the
$popupmodifier may not detect a popup in some cases and it will not be blocked. The$popupmodifier applies thedocumentcontent type with a special flag which is passed to a blocking page. Blocking page itself can do some checks and close the window if it is really a popup. Otherwise, page should be loaded. It can be combined with other request type modifiers, such as$third-party,$strict-third-party,$strict-first-party, and$important.
Rules with the $popup modifier are not supported by AdGuard Content Blocker.
$strict-first-party
Works the same as the $~third-party modifier, but only treats the request as first-party if the referrer and origin have exactly the same hostname.
Requests without a referrer are also treated as first-party requests, and the rules with the $strict-first-party modifier are applied to such requests.
Examples
- domain.com$strict-first-party' — this rule applies only to
domain.com. For example, a request fromdomain.comtohttps://domain.com/icon.icois a first-party request. A request fromsub.domain.comtohttps://domain.com/icon.icois treated as a third-party one (as opposed to the$~third-partymodifier).
You can use a shorter name (alias) instead of using the full modifier name: $strict1p.
Rules with the $strict-first-party modifier are supported by AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for Linux with CoreLibs v1.16 or later.
Requests without a referrer are matched by rules with $strict-first-party in AdGuard for Windows, AdGuard for Mac, and AdGuard for Android with CoreLibs v1.18 or later.
$strict-third-party
Works the same as the $third-party modifier but also treats requests from the domain to its subdomains and vice versa as third-party requests.
Examples
||domain.com^$strict-third-party— this rule applies to all domains exceptdomain.com. An example of a third-party request:https://sub.domain.com/banner.jpg(as opposed to the$third-partymodifier).
You can use a shorter name (alias) instead of using the full modifier name: $strict3p.
Rules with the $strict-third-party modifier are supported by AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for Linux with CoreLibs v1.16 or later.
$third-party
A restriction on third-party and custom requests. A third-party request is a request from an external domain. For example, a request to example.org from domain.com is a third-party request.
To be considered as such, a third-party request should meet one of the following conditions:
- Its referrer is not a subdomain of the target domain or vice versa. For example, a request to
subdomain.example.orgfromexample.orgis not a third-party request - Its
Sec-Fetch-Siteheader is set tocross-site
Examples
$third-party:
||domain.com^$third-party— this rule applies to all domains exceptdomain.comand its subdomains. The rule is never applied if there is no referrer. An example of a third-party request:https://example.org/banner.jpg.
If there is a $~third-party modifier, the rule is only applied to requests that are not from third parties. Which means they have to be sent from the same domain or shouldn't have a referrer at all.
$~third-party:
||domain.com$~third-party— this rule applies only todomain.comand its subdomains. Example of a non third-party request:https://sub.domain.com/icon.ico.
Requests without a referrer are also treated as non third-party requests and the rules with the $~third-party modifier are applied to such requests.
You may use a shorter name (alias) instead of using the full modifier name: $3p.
Requests without a referrer are matched by rules with $~third-party in AdGuard for Windows, AdGuard for Mac, and AdGuard for Android with CoreLibs v1.18 or later.
✅
$to limits the rule scope to requests made to the specified domains and their subdomains. To add multiple domains to one rule, use the | character as a separator.
Examples
/ads$to=evil.com|evil.orgblocks any request toevil.comorevil.organd their subdomains with a path matching/ads./ads$to=~not.evil.com|evil.comblocks any request toevil.comand its subdomains, with a path matching/ads, except requests tonot.evil.comand its subdomains./ads$to=~good.com|~good.orgblocks any request with a path matching/ads, except requests togood.comorgood.organd their subdomains.
$denyallow cannot be used together with $to. Se puede expresar con $to invertido: $denyallow=a.com|b.com es equivalente a $to=~a.com|~b.com.
Rules with the $to modifier are supported by AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for Linux with CoreLibs v1.12 or later, and AdGuard Browser Extension with TSUrlFilter v2.1.3 or later.
Content-type modifiers
There is a set of modifiers, which can be used to limit the rule's application area to certain type of content. These modifiers can also be combined to cover, for example, both images and scripts.
There is a big difference in how AdGuard determines the content type on different platforms. For AdGuard Browser Extension, content type for every request is provided by the browser. AdGuard for Windows, Mac, and Android use the following method: first, the apps try to determine the type of the request by the Sec-Fetch-Dest request header or by the filename extension. If the request is not blocked at this stage, the type will be determined using the Content-Type header at the beginning of the server response.
Examples of content-type modifiers
||example.org^$image— corresponds to all images fromexample.org.||example.org^$script,stylesheet— corresponds to all the scripts and styles fromexample.org.||example.org^$~image,~script,~stylesheet— corresponds to all requests toexample.orgexcept for the images, scripts and styles.
| Modifier \ Products | CoreLibs apps | AdGuard para Chromium | AdGuard para Chrome MV3 | AdGuard para Firefox | AdGuard para iOS | AdGuard para Safari | Bloqueador de contenido AdGuard |
|---|---|---|---|---|---|---|---|
| $document | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| $font | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| $image | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| $media | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| $object | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ✅ |
| $other | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| $ping | ✅ *[1] | ✅ | ✅ | ✅ | ❌ | ❌ | ✅ |
| $script | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| $stylesheet | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| $subdocument | ✅ *[2] | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| $websocket | ✅ | ✅ | ✅ | ✅ | ✅ *[3] | ✅ *[3] | ❌ |
| $xmlhttprequest | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| $webrtc 🚫 | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| $object-subrequest 🚫 | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
- ✅ — totalmente compatible
- ✅ * — compatible, pero la confiabilidad puede variar o pueden ocurrir limitaciones; verifica la descripción del modificador para más detalles
- ❌ — not supported
- 🚫 — removed and no longer supported
$document
The rule corresponds to the main frame document requests, i.e. HTML documents that are loaded in the browser tab. It does not match iframes, there is a $subdocument modifier for these.
By default, AdGuard does not block the requests that are loaded in the browser tab (e.g. "main frame bypass"). The idea is not to prevent pages from loading as the user clearly indicated that they want this page to be loaded. However, if the $document modifier is specified explicitly, AdGuard does not use that logic and prevents the page load. Instead, it responds with a "blocking page".
If this modifier is used with an exclusion rule (@@), it completely disables blocking on corresponding pages. It is equivalent to using $elemhide, $content, $urlblock, $jsinject, $extension modifiers simultaneously.
Examples
-
@@||example.com^$documentcompletely disables filtering on all pages atexample.comand all subdomains. -
||example.com^$documentblocks HTML document request toexample.comwith a blocking page. -
||example.com^$document,redirect=noopframeredirects HTML document request toexample.comto an empty html document. -
||example.com^$document,removeparam=testremovestestquery parameter from HTML document request toexample.com. -
||example.com^$document,replace=/test1/test2/replacestest1withtest2in HTML document request toexample.com.
You may use a shorter name (alias) instead of using the full modifier name: $doc.
$font
The rule corresponds to requests for fonts, e.g. .woff filename extension.
$image
The rule corresponds to images requests.
$media
The rule corresponds to requests for media files — music and video, e.g. .mp4 files.
$object
The rule corresponds to browser plugins resources, e.g. Java or Flash.
Rules with $object modifier are not supported by AdGuard for Safari and AdGuard for iOS.
$other
The rule applies to requests for which the type has not been determined or does not match the types listed above.
$ping
The rule corresponds to requests caused by either navigator.sendBeacon() or the ping attribute on links.
$ping modifier limitations
AdGuard for Windows, Mac, and Android often cannot accurately detect navigator.sendBeacon(). Using $ping is not recommended in the filter lists that are supposed to be used by CoreLibs-based AdGuard products.
Rules with $ping modifier are not supported by AdGuard for Safari and AdGuard for iOS.
$script
The rule corresponds to script requests, e.g. JavaScript, VBScript.
$stylesheet
The rule corresponds to CSS files requests.
You may use a shorter name (alias) instead of using the full modifier name: $css.
$subdocument
The rule corresponds to requests for built-in pages — HTML tags frame and iframe.
Examples
||example.com^$subdocumentblocks built-in page requests (frameandiframe) toexample.comand all its subdomains anywhere.||example.com^$subdocument,domain=domain.comblocks built-in page requests (frameиiframe) toexample.com(and its subdomains) fromdomain.comand all its subdomains.
You may use a shorter name (alias) instead of using the full modifier name: $frame.
$subdocument modifier limitations
In AdGuard for Windows, Mac, and Android subdocuments are being detected by the Sec-Fetch-Dest header if it is present. Otherwise, some main pages may be treated as subdocuments.
Rules with $subdocument modifier are not supported by AdGuard Content Blocker.
$websocket
The rule applies only to WebSocket connections.
$websocket modifier limitations
For AdGuard for Safari and AdGuard for iOS, it is supported on devices with macOS Monterey (version 12) and iOS 16 or higher respectively.
$websocket modifier is supported in all AdGuard products except AdGuard Content Blocker.
$xmlhttprequest
The rule applies only to ajax requests (requests sent via the JavaScript object XMLHttpRequest).
You may use a shorter name (alias) instead of using the full modifier name: $xhr.
AdGuard for Windows, Mac, Android when filtering older browsers cannot accurately detect this type and sometimes detects it as $other or $script. They can only reliably detect this content type when filtering modern browsers that support Fetch metadata request headers.
$object-subrequest (removed)
$object-subrequest modifier is removed and is no longer supported. Rules with it are considered as invalid. The rule corresponds to requests by browser plugins (it is usually Flash).
$webrtc (removed)
This modifier is removed and is no longer supported. Rules with it are considered as invalid. If you need to suppress WebRTC, consider using the nowebrtc scriptlet.
The rule applies only to WebRTC connections.
Examples
||example.com^$webrtc,domain=example.orgblocks webRTC connections toexample.comfromexample.org.@@*$webrtc,domain=example.orgdisables the RTC wrapper forexample.org.
Exception rules modifiers
Exception rules disable the other basic rules for the addresses to which they correspond. They begin with a @@ mark. All the basic modifiers listed above can be applied to them and they also have a few special modifiers.
We recommend to get acquainted with the Adblock Plus filter cheatsheet, for better understanding of how exception rules should be made.
| Modifier \ Products | CoreLibs apps | AdGuard para Chromium | AdGuard para Chrome MV3 | AdGuard para Firefox | AdGuard para iOS | AdGuard para Safari | Bloqueador de contenido AdGuard |
|---|---|---|---|---|---|---|---|
| $content | ✅ | ❌ | ❌ | ✅ | ❌ | ❌ | ❌ |
| $elemhide | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| $extension | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| $jsinject | ✅ | ✅ | ✅ *[1] | ✅ | ✅ | ✅ | ❌ |
| $stealth | ✅ | ✅ | ❌ | ✅ | ❌ | ❌ | ❌ |
| $urlblock | ✅ | ✅ | ❌ | ✅ | ✅ *[2] | ✅ *[2] | ❌ |
| $genericblock | ✅ | ✅ | ✅ | ✅ | ✅ *[3] | ✅ *[3] | ❌ |
| $generichide | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| $specifichide | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ❌ |
- ✅ — totalmente compatible
- ✅ * — compatible, pero la confiabilidad puede variar o pueden ocurrir limitaciones; verifica la descripción del modificador para más detalles
- ❌ — not supported
By default, without specifying additional content type modifiers, exception rule modifiers override other basic rules only for main frame document requests (see $document for more information about main frame document).
For example:
- The website
example.comcontains aniframepointing toexample1.com. - The rule
#%#//console.log('test')is applied.
In this case, the log will appear twice in the console: once for the main frame document and once for iframe.
If you add the @@||example.com^$jsinject rule, the log will appear only once for iframe.
$content
Disables HTML filtering, $hls, $replace, and $jsonprune rules on the pages that match the rule.
Examples
@@||example.com^$contentdisables all content modifying rules on pages atexample.comand all its subdomains.
$elemhide
Disables any cosmetic rules on the pages matching the rule.
Examples
@@||example.com^$elemhidedisables all cosmetic rules on pages atexample.comand all subdomains.
You may use a shorter name (alias) instead of using the full modifier name: $ehide.
$extension
Disables specific userscripts or all userscripts for a given domain.
Syntax
$extension[="userscript_name1"[|"userscript_name2"[|"userscript_name3"[...]]]]
userscript_name(i) stands for a specific userscript name to be disabled by the modifier. The modifier can contain any number of userscript names or none. In the latter case the modifier disables all the userscripts.
Userscript names usually contain spaces or other special characters, which is why you should enclose the name in quotes. Both single (') and double (") ASCII quotes are supported. Multiple userscript names should be separated with a pipe (|). However, if a userscript name is a single word without any special characters, it can be used without quotes.
You can also exclude a userscript by adding a ~ character before it. In this case, the userscript will not be disabled by the modifier.
$extension=~"userscript name"
When excluding a userscript, you must place ~ outside the quotes.
If a userscript's name includes quotes ("), commas (,), or pipes (|), they must be escaped with a backslash (\).
$extension="userscript name\, with \"quote\""
Examples
@@||example.com^$extension="AdGuard Assistant"disables theAdGuard Assistantuserscript onexample.comwebsite.@@||example.com^$extension=MyUserscriptdisables theMyUserscriptuserscript onexample.comwebsite.@@||example.com^$extension='AdGuard Assistant'|'AdGuard Popup Blocker'disables bothAdGuard AssistantandAdGuard Popup Blockeruserscripts onexample.comwebsite.@@||example.com^$extension=~"AdGuard Assistant"disables all user scripts onexample.comwebsite, exceptAdGuard Assistant.@@||example.com^$extension=~"AdGuard Assistant"|~"AdGuard Popup Blocker"disables all user scripts onexample.comwebsite, exceptAdGuard AssistantandAdGuard Popup Blocker.@@||example.com^$extensionno userscript will work on webpages onexample.com.@@||example.com^$extension="AdGuard \"Assistant\""disables theAdGuard "Assistant"userscript onexample.comwebsite.
- Only AdGuard for Windows, Mac, Android are technically capable of using rules with
$extensionmodifier. - Rules with
$extensionmodifier with specific userscript name are supported by AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for Linux with CoreLibs v1.13 or later.
$jsinject
Forbids adding of JavaScript code to the page. You can read about scriptlets and javascript rules further.
Examples
@@||example.com^$jsinjectdisables javascript on pages atexample.comand all subdomains.
$jsinject modifier limitations
Rules with the $jsinject modifier cannot be converted to DNR in AdGuard for Chrome MV3. We only use them in the TSUrlFilter engine to disable some cosmetic rules.
The $jsinject modifier is not supported by AdGuard for Chrome MV3 (yet) and AdGuard Content Blocker.
$stealth
Disables the Tracking protection (formerly Stealth Mode) module for all corresponding pages and requests.
Syntax
$stealth [= opt1 [| opt2 [| opt3 [...]]]]
opt(i) stand for certain Tracking protection options disabled by the modifier. The modifier can contain any number of specific options (see below) or none. In the latter case the modifier disables all the Tracking protection features.
The list of the available modifier options:
searchqueriesdisables Hide your search queries optiondonottrackdisables Ask websites not to track you option3p-cookiedisables Self-destructing third-party cookies option1p-cookiedisables Self-destructing first-party cookies option3p-cachedisables Disable cache for third-party requests option3p-authdisables Block third-party Authorization header optionwebrtcdisables Block WebRTC optionpushdisables Block Push API optionlocationdisables Block Location API optionflashdisables Block Flash optionjavadisables Block Java optionreferrerdisables Hide Referer from third parties optionuseragentdisables Hide your User-Agent optionipdisables Hide your IP address optionxclientdatadisables Remove X-Client-Data header from HTTP requests optiondpidisables Protect from DPI option
Examples
@@||example.com^$stealthdisables Tracking protection forexample.com(and subdomains) requests, except for blocking cookies and hiding tracking parameters (see below).@@||domain.com^$script,stealth,domain=example.comdisables Tracking protection only for script requests todomain.com(and its subdomains) onexample.comand all its subdomains.@@||example.com^$stealth=3p-cookie|dpidisables blocking third-party cookies and DPI fooling measures forexample.com.
Blocking cookies and removing tracking parameters is achieved by using rules with the $cookie, $urltransform and $removeparam modifiers. Exception rules that contain only the $stealth modifier will not do these things. If you want to completely disable all Tracking protection features for a given domain, you must include all three modifiers: @@||example.org^$stealth,removeparam,cookie.
- Modifier options must be lowercase, i.e.
$stealth=DPIwill be rejected. - Modifier options cannot be negated, i.e.
$stealth=~3p-cookiewill be rejected. - AdGuard Browser Extension supports only
searchqueries,donottrack,referrer,xclientdata,1p-cookieand3p-cookieoptions.
- Tracking protection (formerly Stealth Mode) is available in AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard Browser Extension for Firefox and Chromium-based browsers, except AdGuard for Chrome MV3. All other products will ignore the rules with
$stealthmodifier. - Rules with
$stealthmodifier with specific options are supported by AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for Linux with CoreLibs v1.10 or later, and AdGuard Browser Extension with TSUrlFilter v3.0.0 or later. - In AdGuard Browser Extension, Block WebRTC is applied globally and cannot be controlled on a per-site basis. Exception rules like
$stealth=webrtchave no effect.
$urlblock
Disables blocking of all requests sent from the pages matching the rule and disables all $cookie rules.
Examples
@@||example.com^$urlblock— any requests sent from the pages atexample.comand all subdomains are not going to be blocked.
$urlblock modifier limitations
In AdGuard for iOS and AdGuard for Safari, rules with $urlblock work as $document exclusion — unblock everything.
Rules with $urlblock modifier are not supported by AdGuard Content Blocker, and AdGuard for Chrome MV3.
Generic rules
Before we can proceed to the next modifiers, we have to make a definition of generic rules. The rule is generic if it is not limited to specific domains. Wildcard character * is supported as well.
For example, these rules are generic:
###banner
*###banner
#@#.adsblock
*#@#.adsblock
~domain.com###banner
||domain.com^
||domain.com^$domain=~example.com
And these are not:
domain.com###banner
||domain.com^$domain=example.com
$genericblock
Disables generic basic rules on pages that correspond to exception rule.
Examples
@@||example.com^$genericblockdisables generic basic rules on any pages atexample.comand all subdomains.
$genericblock modifier limitations
In AdGuard for iOS and AdGuard for Safari, rules with $genericblock work as $document exclusion — unblock everything.
Rules with $genericblock modifier are not supported by AdGuard Content Blocker, and AdGuard for Chrome MV3.
$generichide
Disables all generic cosmetic rules on pages that correspond to the exception rule.
Examples
@@||example.com^$generichidedisables generic cosmetic rules on any pages atexample.comand its subdomains.
You may use a shorter name (alias) instead of using the full modifier name: $ghide.
specifichide
Disables all specific element hiding and CSS rules, but not general ones. Has an opposite effect to $generichide.
Examples
@@||example.org^$specifichidedisablesexample.org##.bannerbut not##.banner.
You may use a shorter name (alias) instead of using the full modifier name: $shide.
All cosmetic rules — not just specific ones — can be disabled by $elemhide modifier.
Rules with $specifichide modifier are not supported by AdGuard for iOS, AdGuard for Safari, and AdGuard Content Blocker.
Advanced capabilities
These modifiers are able to completely change the behavior of basic rules.
| Modifier \ Products | CoreLibs apps | AdGuard para Chromium | AdGuard para Chrome MV3 | AdGuard para Firefox | AdGuard para iOS | AdGuard para Safari | Bloqueador de contenido AdGuard |
|---|---|---|---|---|---|---|---|
| $all | ✅ | ✅ | ✅ *[1] | ✅ | ✅ | ✅ | ❌ |
| $badfilter | ✅ | ✅ | ✅ *[2] | ✅ | ✅ | ✅ | ❌ |
| $cookie | ✅ | ✅ | ✅ *[3] | ✅ | ❌ | ❌ | ❌ |
| $csp | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ❌ |
| $hls | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| $inline-font | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ❌ |
| $inline-script | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ❌ |
| $jsonprune | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| $xmlprune | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| $network | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| $permissions | ✅ *[4] | ✅ | ✅ | ✅ *[4] | ❌ | ❌ | ❌ |
| $redirect | ✅ | ✅ | ✅ *[5] | ✅ | ❌ | ❌ | ❌ |
| $redirect-rule | ✅ | ✅ | ❌ | ✅ | ❌ | ❌ | ❌ |
| $referrerpolicy | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| $removeheader | ✅ | ✅ *[7] | ✅ *[7] | ✅ *[7] | ❌ | ❌ | ❌ |
| $removeparam | ✅ | ✅ | ✅ *[6] | ✅ | ❌ | ❌ | ❌ |
| $replace | ✅ | ❌ | ❌ | ✅ | ❌ | ❌ | ❌ |
| $urltransform | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| $reason | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| noop | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| $empty 👎 | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ❌ |
| $mp4 👎 | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ❌ |
- ✅ — totalmente compatible
- ✅ * — compatible, pero la confiabilidad puede variar o pueden ocurrir limitaciones; verifica la descripción del modificador para más detalles
- ❌ — not supported
- 👎 — deprecated; still supported but will be removed in the future
$all
$all modifier is made of all content-types modifiers and $popup. E.g. rule ||example.org^$all is converting into rule:
||example.org^$document,subdocument,font,image,media,object,other,ping,script,stylesheet,websocket,xmlhttprequest,popup
This modifier cannot be used as an exception with the @@ mark.
$all modifier limitations
Since $popup is a part if $all, the $all modifier is not supported by AdGuard for Chrome MV3 because of $popup modifier limitations.
Rules with $all modifier are not supported by AdGuard Content Blocker.
$badfilter
The rules with the $badfilter modifier disable other basic rules to which they refer. It means that the text of the disabled rule should match the text of the $badfilter rule (without the $badfilter modifier).
Examples
||example.com$badfilterdisables||example.com||example.com$image,badfilterdisables||example.com$image@@||example.com$badfilterdisables@@||example.com||example.com$domain=domain.com,badfilterdisables||example.com$domain=domain.com
Rules with $badfilter modifier can disable other basic rules for specific domains if they fulfill the following conditions:
- The rule has a
$domainmodifier - The rule does not have a negated domain
~in$domainmodifier value
In that case, the $badfilter rule will disable the corresponding rule for domains specified in both the $badfilter and basic rules. Please note that wildcard-TLD logic works here as well.
Examples
/some$domain=example.com|example.org|example.iois disabled forexample.comby/some$domain=example.com,badfilter/some$domain=example.com|example.org|example.iois disabled forexample.comandexample.orgby/some$domain=example.com|example.org,badfilter/some$domain=example.com|example.organd/some$domain=example.ioare disabled completely by/some$domain=example.com|example.org|example.io,badfilter/some$domain=example.com|example.org|example.iois disabled completely by/some$domain=example.*,badfilter/some$domain=example.*is disabled forexample.comandexample.orgby/some$domain=example.com|example.org,badfilter/some$domain=example.com|example.org|example.iois NOT disabled forexample.comby/some$domain=example.com|~example.org,badfilterbecause the value of$domainmodifier contains a negated domain
$badfilter modifier limitations
In AdGuard for Chrome MV3 a rule with the $badfilter modifier is applied in DNR only if it fully cancels the source rule. We cannot calculate it if it is only partially canceled. Examples.
Rules with $badfilter modifier are not supported by AdGuard Content Blocker.
$cookie
The $cookie modifier completely changes rule behavior. Instead of blocking a request, this modifier makes AdGuard suppress or modify the Cookie and Set-Cookie headers.
Multiple rules matching a single request
In case if multiple $cookie rules match a single request, we will apply each of them one by one.
Syntax
$cookie [= name[; maxAge = seconds [; sameSite = strategy ]]]
where:
name— optional, string or regular expression to match cookie name.seconds— number of seconds for current time to offset the expiration date of cookie.strategy— string for Same-Site strategy to be applied to the cookie.
For example,
||example.org^$cookie=NAME;maxAge=3600;sameSite=lax
every time AdGuard encounters a cookie called NAME in a request to example.org, it will do the following:
- Set its expiration date to current time plus
3600seconds - Makes the cookie use Same-Site "lax" strategy.
Escaping special characters
If regular expression name is used for matching, two characters must be escaped: comma , and dollar sign $. Use backslash \ to escape each of them. For example, escaped comma looks like this: \,.
Examples
||example.org^$cookieblocks all cookies set byexample.org; this is an equivalent to settingmaxAge=0$cookie=__cfduidblocks CloudFlare cookie everywhere$cookie=/__utm[a-z]/blocks Google Analytics cookies everywhere||facebook.com^$third-party,cookie=c_userprevents Facebook from tracking you even if you are logged in
There are two methods to deactivate $cookie rules: the primary method involves using an exception marked with @@ — @@||example.org^$cookie. The alternative method employs a $urlblock exception (also included under the $document exception alias — $elemhide,jsinject,content,urlblock,extension). Here's how it works:
@@||example.org^$cookieunblocks all cookies set byexample.org@@||example.org^$urlblockunblocks all cookies set byexample.organd disables blocking of all requests sent fromexample.org@@||example.org^$cookie=conceptunblocks a single cookie namedconcept@@||example.org^$cookie=/^_ga_/unblocks every cookie that matches the regular expression
$cookie modifier limitations
In AdGuard for Chrome MV3 we delete cookies in 2 ways: from content-script side (to which we have access) and from onBeforeSendHeaders listener. Since onBeforeSendHeaders and other listeners are no longer blocking, we are not able to delete them in all cases. You can check if a rule works with this test.
$cookie rules support these types of modifiers: $domain, $~domain, $important, $third-party, $~third-party, strict-third-party, and strict-first-party.
Rules with $cookie modifier are not supported by AdGuard Content Blocker, AdGuard for iOS, and AdGuard for Safari.
$csp
This modifier completely changes the rule behavior. If it is applied to a rule, the rule will not block the matching request. Response headers will be modified instead.
In order to use this type of rules, it is required to have the basic understanding of the Content Security Policy security layer.
For the requests matching a $csp rule, we will strengthen response security policy by enhancing the content security policy, similar to the content security policy of the $csp modifier contents. $csp rules are applied independently from any other rule type. Only document-level exceptions can influence it (see the examples section), but no other basic rules.
Multiple rules matching a single request
In case if multiple $csp rules match a single request, we will apply each of them.
Syntax
$csp value syntax is similar to the Content Security Policy header syntax.
$csp value can be empty in the case of exception rules. See examples section below.
Examples
||example.org^$csp=frame-src 'none'blocks all frames on example.org and its subdomains.@@||example.org/page/*$csp=frame-src 'none'disables all rules with the$cspmodifier exactly matchingframe-src 'none'on all the pages matching the rule pattern. For instance, the rule above.@@||example.org/page/*$cspdisables all the$csprules on all the pages matching the rule pattern.||example.org^$csp=script-src 'self' 'unsafe-eval' http: https:disables inline scripts on all the pages matching the rule pattern.@@||example.org^$documentor@@||example.org^$urlblockdisables all the$csprules on all the pages matching the rule pattern.
- There are a few characters forbidden in the
$cspvalue:,,$. $csprules support three types of modifiers:$domain,$important,$subdocument.- Rules with
report-*directives are considered invalid.
Rules with $csp modifier are not supported by AdGuard Content Blocker, AdGuard for iOS and AdGuard for Safari.
$hls
$hls rules modify the response of a matching request. They are intended as a convenient way to remove segments from HLS playlists (RFC 8216).
The word "segment" in this document means either a "Media Segment" or a "playlist" as part of a "Master Playlist": $hls rules do not distinguish between a "Master Playlist" and a "Media Playlist".
Syntax
||example.org^$hls=urlpatternremoves segments whose URL matches the URL patternurlpattern. The pattern works just like the one in basic URL rules, however, the characters/,$and,must be escaped with\insideurlpattern.||example.org^$hls=/regexp/optionsremoves segments where the URL or one of the tags (for certain options, if present) is matched by the regular expressionregexp. Availableoptionsare:t— instead of testing the segment's URL, test each of the segment's tags against the regular expression. A segment with a matching tag is removed;i— make the regular expression case-insensitive.
The characters /, $ and , must be escaped with \ inside regexp.
Exceptions
Basic URL exceptions shall not disable rules with the $hls modifier. They can be disabled as described below:
@@||example.org^$hlsdisables all$hlsrules for responses from URLs matching||example.org^.@@||example.org^$hls=textdisables all$hlsrules with the value of the$hlsmodifier equal totextfor responses from URLs matching||example.org^.
$hls rules can also be disabled by $document, $content and $urlblock exception rules.
When multiple $hls rules match the same request, their effect is cumulative.
Examples
||example.org^$hls=\/videoplayback^?*&source=dclk_video_adsremoves all segments with the matching URL.||example.org^$hls=/\/videoplayback\/?\?.*\&source=dclk_video_ads/iachieves more or less the same with a regular expression instead of a URL pattern.||example.org^$hls=/#UPLYNK-SEGMENT:.*\,ad/tremoves all segments which have the matching tag.
Anatomy of an HLS playlist
A quick summary of the specification:
- An HLS playlist is a collection of text lines
- A line may be empty, a comment (starts with
#), a tag (also starts with#, can only be recognized by name) or a URL - A URL line is called a "segment"
- Tags may apply to a single segment, i.e. the first URL line after the tag, to all segments following the tag and until the tag with the same name, or to the whole playlist
Some points specific to the operation of $hls rules:
- When a segment is removed, all of the tags that apply only to that segment are also removed
- When there is a tag that applies to multiple segments, and all of those segments are removed, the tag is also removed
- Since there is no way to recognize different kinds of tags by syntax, we recognize all of the tags specified by the RFC, plus some non-standard tags that we have seen in the field. Any lines starting with
#and not recognized as a tag are passed through without modification, and are not matched against the rules - Tags will not be matched if they apply to the entire playlist, and
$hlsrules cannot be used to remove them, as these rule types are intended for segment removals. If you know what you are doing, you can use$replacerules to remove or rewrite just a single tag from the playlist
An example of a transformation done by the rules:
Original response
#EXTM3U
#EXT-X-TARGETDURATION:10
#EXTINF,5
preroll.ts
#UPLYNK-SEGMENT:abc123,ad
#UPLYNK-KEY:aabb1122
#EXT-X-DISCONTINUITY
#EXTINF,10
01.ts
#EXTINF,10
02.ts
#UPLYNK-SEGMENT:abc123,segment
#UPLYNK-KEY:ccdd2233
#EXT-X-DISCONTINUITY
#EXTINF,10
01.ts
#EXTINF,10
02.ts
#EXT-X-ENDLIST
Applied rules
||example.org^$hls=preroll
||example.org^$hls=/#UPLYNK-SEGMENT:.*\,ad/t
Modified response
#EXTM3U
#EXT-X-TARGETDURATION:10
#UPLYNK-SEGMENT:abc123,segment
#UPLYNK-KEY:ccdd2233
#EXT-X-DISCONTINUITY
#EXTINF,10
01.ts
#EXTINF,10
02.ts
#EXT-X-ENDLIST
- Rules with the
$hlsmodifier can only be used in trusted filters. $hlsrules are compatible with the modifiers$domain,$third-party,$strict-third-party,$strict-first-party,$app,$important,$match-case, and$xmlhttprequestonly.$hlsrules only apply to HLS playlists, which are UTF-8 encoded text starting with the line#EXTM3U. Any other response will not be modified by these rules.$hlsrules do not apply if the size of the original response is more than 10 MB.
Rules with the $hls modifier are supported by AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for Linux with CoreLibs v1.10 or later.
$inline-script
The $inline-script modifier is designed to block inline JavaScript embedded into the web page, using Content Security Policy (CSP). It improves security and privacy by preventing application of inline ads or potentially malicious scripts. The rule ||example.org^$inline-script is converting into the CSP-syntax rule:
||example.org^$csp=script-src 'self' 'unsafe-eval' http: https: data: blob: mediastream: filesystem:
$inline-font
The $inline-font modifier is designed to block inline fonts embedded into the web page, using Content Security Policy (CSP). It improves security and privacy by preventing application of inline fonts that could be used for data collection and fingerprinting. The rule ||example.org^$inline-font is converting into the CSP-syntax rule:
||example.org^$csp=font-src 'self' 'unsafe-eval' http: https: data: blob: mediastream: filesystem:
$jsonprune
$jsonprune rules modify the response to a matching request by removing JSON items that match a modified JSONPath expression. They do not modify responses which are not valid JSON documents.
In AdGuard for Windows, Mac, and Android with CoreLibs v1.11 or later, $jsonprune also supports modifying JSONP (padded JSON) documents.
Syntax
||example.org^$jsonprune=expressionremoves items that match the modified JSONPath expressionexpressionfrom the response.
Due to the way rule parsing works, the characters $ and , must be escaped with \ inside expression.
The modified JSONPath syntax has the following differences from the original:
- Script expressions are not supported
- The supported filter expressions are:
?(has <key>)— true if the current object has the specified key?(key-eq <key> <value>)— true if the current object has the specified key, and its value is equal to the specified value?(key-substr <key> <value>)— true if the specified value is a substring of the value of the specified key of the current object
- Whitespace outside of double- or single-quoted strings has no meaning
- Both double- and single-quoted strings can be used
- Expressions ending with
..are not supported - Multiple array slices can be specified in square brackets
There are various online tools that make working with JSONPath expressions more convenient:
https://www.site24x7.com/tools/jsonpath-finder-validator.html https://jsonpathfinder.com/ https://jsonpath.com/
Keep in mind, though, that all JSONPath implementations have unique features/quirks and are subtly incompatible with each other.
Exceptions
Basic URL exceptions shall not disable rules with the $jsonprune modifier. They can be disabled as described below:
@@||example.org^$jsonprunedisables all$jsonprunerules for responses from URLs matching||example.org^.@@||example.org^$jsonprune=textdisables all$jsonprunerules with the value of the$jsonprunemodifier equal totextfor responses from URLs matching||example.org^.
$jsonprune rules can also be disabled by $document, $content and $urlblock exception rules.
When multiple $jsonprune rules match the same request, they are sorted in lexicographical order, the first rule is applied to the original response, and each of the remaining rules is applied to the result of applying the previous one.
Examples
||example.org^$jsonprune=\$..[one\, "two three"]removes all occurrences of the keys "one" and "two three" anywhere in the JSON document.
Input
{
"one": 1,
"two": {
"two three": 23,
"four five": 45
}
}
Output
{
"two": {
"four five": 45
}
}
||example.org^$jsonprune=\$.a[?(has ad_origin)]removes all children ofathat have anad_originkey.
Input
{
"a": [
{
"ad_origin": "https://example.org",
"b": 42
},
{
"b": 1234
}
]
}
Output
{
"a": [
{
"b": 1234
}
]
}
||example.org^$jsonprune=\$.*.*[?(key-eq 'Some key' 'Some value')]removes all items that are at nesting level 3 and have a property "Some key" equal to "Some value".
Input
{
"a": {"b": {"c": {"Some key": "Some value"}, "d": {"Some key": "Other value"}}},
"e": {"f": [{"Some key": "Some value"}, {"Some key": "Other value"}]}
}
Output
{
"a": {"b": {"d": {"Some key": "Other value"}}},
"e": {"f": [{"Some key": "Other value"}]}
}
Nested JSONPath expressions
In AdGuard for Windows, Mac and Android with CoreLibs v1.11 or later, JSONPath expressions may be used as keys in filter expressions.
||example.org^$jsonprune=\$.elems[?(has "\$.a.b.c")]removes all children ofelemswhich have a property selectable by the JSONPath expression$.a.b.c.
Input
{
"elems": [
{
"a": {"b": {"c": 123}},
"k": "v"
},
{
"d": {"e": {"f": 123}},
"k1": "v1"
}
]
}
Output
{
"elems": [
{
"d": {"e": {"f": 123}},
"k1": "v1"
}
]
}
||example.org^$jsonprune=\$.elems[?(key-eq "\$.a.b.c" "abc")]removes all children ofelemswhich have a property selectable by the JSONPath expression$.a.b.cwith a value equal to"abc".
Input
{
"elems": [
{
"a": {"b": {"c": 123}}
},
{
"a": {"b": {"c": "abc"}}
}
]
}
Output
{
"elems": [
{
"a": {"b": {"c": 123}}
}
]
}
$jsonprunerules are only compatible with these modifiers:$domain,$third-party,$strict-third-party,$strict-first-party,$app,$important,$match-case, and$xmlhttprequest.$jsonprunerules do not apply if the size of the original response is greater than 10 MB.
Rules with the $jsonprune modifier are supported by AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for Linux with CoreLibs v1.10 or later.
$xmlprune
$xmlprune rules modify the response to a matching request by removing XML items that match an XPath 1.0 expression. The expression must return a node-set. $xmlprune rules do not modify responses which are not well-formed XML documents.
Syntax
||example.org^$xmlprune=expressionremoves items that match the XPath expressionexpressionfrom the response.
Due to the way rule parsing works, the characters $ and , must be escaped with \ inside expression.
Exceptions
Basic URL exceptions shall not disable rules with the $xmlprune modifier. They can be disabled as described below:
@@||example.org^$xmlprunedisables all$xmlprunerules for responses from URLs matching||example.org^.@@||example.org^$xmlprune=textdisables all$xmlprunerules with the value of the$xmlprunemodifier equal totextfor responses from URLs matching||example.org^.
$xmlprune rules can also be disabled by $document, $content and $urlblock exception rules.
When multiple $xmlprune rules match the same request, they are applied in lexicographical order.
Examples
||example.org^$xmlprune=/bookstore/book[position() mod 2 = 1]removes odd-numbered books from the bookstore.
Input
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="children">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="web">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book>
<book category="web">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
Output
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book category="children">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="web">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
||example.org^$xmlprune=/bookstore/book[year = 2003]removes books from the year 2003 from the bookstore.
Input
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="children">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="web">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book>
<book category="web">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
Output
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="children">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
||example.org^$xmlprune=//*/@*removes all attributes from all elements.
Input
<?xml version="1.0" encoding="UTF-8"?>
<bookstore location="cy">
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
</bookstore>
Output
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title>Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
</bookstore>
$xmlprunerules are only compatible with these modifiers:$domain,$third-party,$strict-third-party,$strict-first-party,$app,$important,$match-case, and$xmlhttprequest.$xmlprunerules do not apply if the size of the original response is greater than 10 MB.
Rules with the $xmlprune modifier are supported by AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for Linux with CoreLibs v1.15 or later.
$network
This is basically a Firewall-like rule allowing to fully block or unblock access to a specified remote address.
$networkrules match IP addresses only! You cannot use them to block or unblock access to a domain.- To match an IPv6 address, you have to use the collapsed syntax, e.g. use
[2001:4860:4860::8888]$networkinstead of[2001:4860:4860:0:0:0:0:8888]$network. - An allowlist
$networkrule makes AdGuard bypass data to the matching endpoint, hence there will be no further filtering at all. - If the IP part starts and ends with
/character, it is treated as a regular expression.
We recommend to get acquainted with this article for better understanding of regular expressions.
The $network modifier can only be used in rules together with the $app and $important modifiers, and not with any other modifiers.
Examples
174.129.166.49:3478^$networkblocks access to174.129.166.49:3478(but not to174.129.166.49:34788).[2001:4860:4860::8888]:443^$networkblocks access to[2001:4860:4860::8888]:443.174.129.166.49$networkblocks access to174.129.166.49:*.@@174.129.166.49$networkmakes AdGuard bypass data to the endpoint. No other rules will be applied./.+:3[0-9]{4}/$networkblocks access to any port from 30000 to 39999./8.8.8.(:?8|4)/$networkblocks access to both8.8.8.8and8.8.8.4.
Only AdGuard for Windows, Mac, and Android are technically capable of using rules with $network modifier.
$permissions
This modifier completely changes the rule behavior. If it is applied to a rule, the rule will not block the matching request. Response headers will be modified instead.
In order to use this type of rules, it is required to have a basic understanding of the Permissions Policy security layer.
For the requests matching a $permissions rule, AdGuard strengthens response's permissions policy by adding an additional permission policy equal to the $permissions modifier contents. $permissions rules are applied independently from any other rule type. Only document-level exceptions can influence it (see the examples section), but no other basic rules.
Syntax
$permissions value syntax is identical to that of the Permissions-Policy header syntax with the following exceptions:
- A comma that separates multiple features MUST be escaped — see examples below.
- A pipe character (
|) can be used instead of a comma to separate features.
Available directives are listed in the Permissions Policy article.
$permissions value can be empty in the case of exception rules — see examples below.
Examples
||example.org^$permissions=autoplay=()disallows autoplay media requested through theHTMLMediaElementinterface acrossexample.org.@@||example.org/page/*$permissions=autoplay=()disables all rules with the$permissionsmodifier exactly matchingautoplay=()on all the pages matching the rule pattern. For instance, the rule above. It is important to note that the exception rule only takes effect in the case of an exact value match. For example, if you want to disable the rule$permissions=a=()\,b=(), you need exception rule@@$permissions=a=()\,b=(), and not@@$permissions=b=()\,a=(), nor@@$permissions=b=()becauseb=()\,a=()orb=()does not match witha=()\,b=().@@||example.org/page/*$permissionsdisables all the$permissionsrules on all the pages matching the rule pattern.$domain=example.org|example.com,permissions=storage-access=()\, camera=()disallows using the Storage Access API to request access to unpartitioned cookies and using video input devices acrossexample.organdexample.com.$domain=example.org|example.com,permissions=storage-access=()|camera=()does the same — a|can be used to separate the features instead of an escaped comma.@@||example.org^$documentor@@||example.org^$urlblockdisables all the$permissionrules on all the pages matching the rule pattern.
$permissions rules only take effect for main frame and sub frame requests. This means they are applied when a page is loaded or when an iframe is loaded.
If there are multiple $permissions rules that match the same request, multiple Permissions-Policy headers will be added to the response for each rule with their $permissions value. So if you have two rules: ||example.org^$permissions=autoplay=() and ||example.org^$permissions=geolocation=()\,camera=() that match the same request, the response will contain two Permissions-Policy headers: autoplay=() and geolocation=()\,camera=().
$permissions modifier limitations
Firefox ignores the Permissions-Policy header. For more information, see this issue.
- Characters forbidden in the
$permissionsvalue:$. $permissionsis compatible with a limited set of modifiers:$domain,$important,$subdocument, and content-type modifiers.$permissionsrules that do not have any content-type modifiers will match only requests where content type isdocument.
- Rules with the
$permissionsmodifier are supported by AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for Linux with CoreLibs v1.11 or later, and AdGuard Browser Extension with TSUrlFilter v3.0.0 or later. - Pipe separator
|instead of escaped comma is supported by AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for Linux with CoreLibs v1.14 or later, and AdGuard Browser Extension with TSUrlFilter v3.0.0 or later.
$redirect
AdGuard is able to redirect web requests to a local "resource".
Syntax
AdGuard uses the same filtering rule syntax as uBlock Origin. Also, it is compatible with ABP $rewrite=abp-resource modifier.
$redirect is a modifier for the basic filtering rules so rules with this modifier support all other basic modifiers like $domain, $third-party, $script, etc.
The value of the $redirect modifier must be the name of the resource that will be used for redirection.
Disabling $redirect rules
||example.org/script.js$script,redirect=noopjs— this rule redirects all requests toexample.org/script.jsto the resource namednoopjs.||example.org/test.mp4$media,redirect=noopmp4-1s— this rule redirects all requests toexample.org/test.mp4to the resource namednoopmp4-1s.@@||example.org^$redirectwill disable all$redirectrules for URLs that match||example.org^.@@||example.org^$redirect=nooptextwill disable all rules with$redirect=nooptextfor any request that matches||example.org^.
More information on redirects and their usage is available on GitHub.
Priorities of $redirect rules
$redirect rules have higher priority than regular basic blocking rules. This means that if there is a basic blocking rule, the $redirect rule will override it. Allowlist rules with @@ mark have higher priority than $redirect rules. If a basic rule with the $important modifier and the $redirect rule matches the same URL, the latter is overridden unless it's also marked as $important.
In short: $important > @@ > $redirect > basic rules.
Go to rules priorities for more details.
$redirect modifier limitations
In AdGuard for Chrome MV3 allowlist rules with $redirect are not supported.
- Rules with
$redirectmodifier are not supported by AdGuard Content Blocker, AdGuard for iOS, and AdGuard for Safari . $redirectin uBlock Origin supports specifying priority, e.g.$redirect=noopjs:42. AdGuard does not support it and instead just discards the priority postfix.
$redirect-rule
This is basically an alias to $redirect since it has the same "redirection" values and the logic is almost similar. The difference is that $redirect-rule is applied only in the case when the target request is blocked by a different basic rule.
Go to rules priorities for more details.
Negating $redirect-rule works exactly the same way as for regular $redirect rules. Even more than that, @@||example.org^$redirect will negate both $redirect and $redirect-rule rules.
Examples
||example.org/script.js
||example.org^$redirect-rule=noopjs
In this case, only requests to example.org/script.js will be "redirected" to noopjs. All other requests to example.org will be kept intact.
Rules with $redirect-rule modifier are not supported by AdGuard Content Blocker, AdGuard for iOS, AdGuard for Safari, and AdGuard for Chrome MV3. The discussion about adding support for $redirect-rule rules in Chrome MV3 extensions is currently open.
$referrerpolicy
These rules allow overriding of a page's referrer policy. Responses to matching requests will have all of their Referrer-Policy headers replaced with a single header with the value equal to the matching rule's modifier value. If the response carries an HTML document with a <meta name="referrer"... tag, the content attribute of the tag will also be replaced with the modifier value.
An exception rule with a modifier value disables the blocking rule with the same modifier value. An exception rule without a modifier value disables all matched referrer-policy rules.
If a request matches multiple $referrerpolicy rules not disabled by exceptions, only one of them (it is not specified which one) is applied. $referrerpolicy rules without specified content-type modifiers apply to $document and $subdocument content types.
Examples
||example.com^$referrerpolicy=unsafe-urloverrides the referrer policy forexample.comwithunsafe-url.@@||example.com^$referrerpolicy=unsafe-urldisables the previous rule.@@||example.com/abcd.html^$referrerpolicydisables all$referrerpolicyrules onexample.com/abcd.html.
Rules with the $referrerpolicy modifier are supported by AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for Linux with CoreLibs v1.12 or later.
$removeheader
Rules with $removeheader modifier are intended to remove headers from HTTP requests and responses. The initial motivation for this rule type is to be able to get rid of the Refresh header which is often used to redirect users to an undesirable location. However, this is not the only case where this modifier can be useful.
Just like $csp, $redirect, $removeparam, and $cookie, this modifier exists independently, rules with it do not depend on the regular basic rules, i.e. regular exception or blocking rules will not affect it. By default, it only affects response headers. However, you can also change it to remove headers from HTTP requests as well.
Syntax
Basic syntax
||example.org^$removeheader=header-nameremoves a response header calledheader-name||example.org^$removeheader=request:header-nameremoves a request header calledheader-name
$removeheader is case-insensitive, but we suggest always using lower case.
Negating $removeheader
This type of rules works pretty much the same way it works with $csp and $redirect modifiers.
Use @@ to negate $removeheader:
@@||example.org^$removeheadernegates all$removeheaderrules for URLs that match||example.org^.@@||example.org^$removeheader=headernegates the rule with$removeheader=headerfor any request matching||example.org^.
$removeheader rules can also be disabled by $document and $urlblock exception rules. But basic exception rules without modifiers will not do that. For example, @@||example.com^ will not disable $removeheader=p for requests to example.com, but @@||example.com^$urlblock will.
In case of multiple $removeheader rules matching a single request, we will apply each of them one by one.
Examples
-
||example.org^$removeheader=refreshremovesRefreshheader from all HTTP responses returned byexample.organd its subdomains. -
||example.org^$removeheader=request:x-client-dataremovesX-Client-Dataheader from all HTTP requests. -
Next block of rules removes
RefreshandLocationheaders from all HTTP responses returned byexample.orgsave for requests toexample.org/path/*, for which no headers will be removed:||example.org^$removeheader=refresh||example.org^$removeheader=location@@||example.org/path/$removeheader
$removeheader modifier limitations
AdGuard for Chrome MV3 has some limitations:
-
Negation and allowlist rules are not supported.
-
Group of similar
$removeheaderrules will be combined into one declarative rule. For example:||testcases.adguard.com$xmlhttprequest,removeheader=p1case1||testcases.adguard.com$xmlhttprequest,removeheader=P2Case1$xmlhttprequest,removeheader=p1case2$xmlhttprequest,removeheader=P2case2se convierte a
[{"id": 1,"action": {"type": "modifyHeaders","responseHeaders": [{"header": "p1case1","operation": "remove"},{"header": "P2Case1","operation": "remove"},]},"condition": {"urlFilter": "||testcases.adguard.com","resourceTypes": ["xmlhttprequest"]}},{"id": 2,"action": {"type": "modifyHeaders","responseHeaders": [{"header": "p1case2","operation": "remove"},{"header": "P2case2","operation": "remove"}]},"condition": {"resourceTypes": ["xmlhttprequest"]}}]
This type of rules can only be used in trusted filters.
-
In order to avoid compromising the security
$removeheadercannot remove headers from the list below:access-control-allow-originaccess-control-allow-credentialsaccess-control-allow-headersaccess-control-allow-methodsaccess-control-expose-headersaccess-control-max-ageaccess-control-request-headersaccess-control-request-methodorigintiming-allow-originallowcross-origin-embedder-policycross-origin-opener-policycross-origin-resource-policycontent-security-policycontent-security-policy-report-onlyexpect-ctfeature-policyorigin-isolationstrict-transport-securityupgrade-insecure-requestsx-content-type-optionsx-download-optionsx-frame-optionsx-permitted-cross-domain-policiesx-powered-byx-xss-protectionpublic-key-pinspublic-key-pins-report-onlysec-websocket-keysec-websocket-extensionssec-websocket-acceptsec-websocket-protocolsec-websocket-versionp3psec-fetch-modesec-fetch-destsec-fetch-sitesec-fetch-userreferrer-policycontent-typecontent-lengthacceptaccept-encodinghostconnectiontransfer-encodingupgrade
-
$removeheaderrules are only compatible with$domain,$third-party,$strict-third-party,$strict-first-party,$app,$important,$match-case, and content-type modifiers such as$scriptand$stylesheet. The rules which have any other modifiers are considered invalid and will be discarded.
Rules with $removeheader modifier are supported by AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard Browser Extension for Chrome, Firefox, and Edge.
$removeparam
$queryprune is an alias of $removeparam. Since $queryprune is deprecated, avoid using it and use $removeparam instead.
Rules with $removeparam modifier are intended to strip query parameters from requests' URLs. Please note that such rules are only applied to GET, HEAD, OPTIONS, and sometimes POST requests.
Syntax
Basic syntax
$removeparam=paramremoves query parameter with the nameparamfrom URLs of any request, e.g. a request tohttps://example.com/page?param=1&another=2will be transformed intohttps://example.com/page?another=2.
Regular expressions
You can also use regular expressions to match query parameters and/or their values:
$removeparam=/regexp/[options]— removes query parameters that matches theregexpregular expression from URLs of any request. Unlike basic syntax, it means "remove query parameters normalized to aname=valuestring which match theregexpregular expression".[options]here is the list of regular expression options. At the moment, the only supported option isiwhich makes matching case-insensitive.
Escaping special characters
Special characters should be URL-encoded in a rule to correctly match the URL text.
For example, to remove ?$param=true, you should use the $removeparam=%24param rule.
Spaces and commas should also be URL-encoded, otherwise the rule won't match the URL. However, ., -, _, and ~ should be used as they are, since they are not marked as reserved characters in URL encoding.
Remember to escape special characters like . in the regular expressions. Use the \ character to do this. For example, an escaped dot should look like this: \..
Regexp-type rules apply to both the name and value of the parameter. To minimize errors, it is safer to start each regexp with /^, unless you are specifically targeting parameter values.
Remove all query parameters
Specify naked $removeparam to remove all query parameters:
||example.org^$removeparam— removes all query parameters from URLs matching||example.org^.
Inversion
Use ~ to apply inversion:
$removeparam=~param— removes all query parameters with the name different fromparam.$removeparam=~/regexp/— removes all query parameters that do not match theregexpregular expression.
If ~ does not appear at the beginning of the rule, it is treated as a symbol in the text.
Negating $removeparam
This sort of rules work pretty much the same way it works with $csp and $redirect modifiers.
Use @@ to negate $removeparam:
@@||example.org^$removeparamnegates all$removeparamrules for URLs that match||example.org^.@@||example.org^$removeparam=paramnegates the rule with$removeparam=paramfor any request matching||example.org^.@@||example.org^$removeparam=/regexp/negates the rule with$removeparam=/regexp/for any request matching||example.org^.
Multiple rules matching a single request
In the case when multiple $removeparam rules match a single request, each of them will be applied one by one.
Examples
$removeparam=/^(utm_source|utm_medium|utm_term)=/
$removeparam=/^(utm_content|utm_campaign|utm_referrer)=/
@@||example.com^$removeparam
With these rules some UTM parameters will be stripped out from any request, except that requests to example.com will not be stripped at all, e.g. https://google.com/page?utm_source=s&utm_referrer=fb.com&utm_content=img will be transformed to https://google.com/page, but https://example.com/page?utm_source=s&utm_referrer=fb.com&utm_content=img will not be affected by the blocking rule.
-
$removeparam=utm_sourceremovesutm_sourcequery parameter from all requests. -
$removeparam=/utm_.*/removes allutm_* queryparameters from URL queries of any request, e.g. a request tohttps://example.com/page?utm_source=testwill be transformed tohttps://example.com/page. -
$removeparam=/^utm_source=campaign$/removesutm_sourcequery parameter with the value equal tocampaign. It does not touch otherutm_sourceparameters.
Negating one $removeparam rule and replacing it with a different rule
$removeparam=/^(gclid|yclid|fbclid)=/
@@||example.com^$removeparam=/^(gclid|yclid|fbclid)=/
||example.com^$removeparam=/^(yclid|fbclid)=/
With these rules, Google, Yandex, and Facebook Click IDs will be removed from all requests. There is one exception: Google Click ID (gclid) will not be removed from requests to example.com.
Negating $removeparam for all parameters
$removeparam=/^(utm_source|utm_medium|utm_term)=/
$removeparam=/^(utm_content|utm_campaign|utm_referrer)=/
@@||example.com^$removeparam
With these rules, specified UTM parameters will be removed from any request save for requests to example.org.
$removeparam rules can also be disabled by $document and $urlblock exception rules. But basic exception rules without modifiers do not do that. For example, @@||example.com^ will not disable $removeparam=p for requests to example.com, but @@||example.com^$urlblock will.
$removeparam modifier limitations
AdGuard for Chrome MV3 has some limitations:
-
Regular expressions, negation and allowlist rules are not supported.
-
Each
$removeparamrule with a named parameter gets its own declarative rule with a param-awareurlFilter(e.g.^utm_source=). Chrome DNR applies a redirect only once per navigation, so without this, only the highest-priority rule would fire and the rest would be skipped. The param-awareurlFiltermakes each rule fire only when its target parameter is present, forming a redirect chain — one parameter stripped per hop — until all are removed. Chrome allows up to 20 hops per navigation, which is enough for real-world tracking URLs. These hops are invisible to users. Example:||testcases.adguard.com$xmlhttprequest,removeparam=p1case1||testcases.adguard.com$xmlhttprequest,removeparam=p2case1||testcases.adguard.com$xmlhttprequest,removeparam=P3Case1$xmlhttprequest,removeparam=p1case2se convierte a
[{"id": 1,"action": {"type": "redirect","redirect": {"transform": {"queryTransform": {"removeParams": ["p1case1"]}}}},"condition": {"urlFilter": "||testcases.adguard.com*^p1case1=","resourceTypes": ["xmlhttprequest"]}},{"id": 2,"action": {"type": "redirect","redirect": {"transform": {"queryTransform": {"removeParams": ["p2case1"]}}}},"condition": {"urlFilter": "||testcases.adguard.com*^p2case1=","resourceTypes": ["xmlhttprequest"]}},{"id": 3,"action": {"type": "redirect","redirect": {"transform": {"queryTransform": {"removeParams": ["P3Case1"]}}}},"condition": {"urlFilter": "||testcases.adguard.com*^P3Case1=","resourceTypes": ["xmlhttprequest"]}},{"id": 4,"action": {"type": "redirect","redirect": {"transform": {"queryTransform": {"removeParams": ["p1case2"]}}}},"condition": {"urlFilter": "^p1case2=","resourceTypes": ["xmlhttprequest"]}}]
- Rules with the
$removeparammodifier can only be used in trusted filters. $removeparamrules are compatible with basic modifiers, content-type modifiers, and with the$importantand$appmodifiers. Rules with any other modifiers are considered invalid and will be discarded.- Although
$domainis classified as a basic modifier, it's not compatible with$removeparamrules in the Manifest V3 extension. $removeparamrules without content type modifiers will only match requests where the content type isdocument.
- Rules with
$removeparammodifier are supported by AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for Linux with CoreLibs v1.7 or later, and AdGuard Browser Extension v3.6 or later. $removeparamsyntax for regular expressions is supported AdGuard for Windows, AdGuard for Mac, and AdGuard for Android with CoreLibs v1.8 or later, and AdGuard Browser Extension v4.0 or later.POSTrequest types are supported only by AdGuard for Windows, Mac, and Android with CoreLibs v1.10 or later, and AdGuard Browser Extension with TSWebExtension v0.4.6 or later.
$replace
This modifier completely changes the rule behavior. If it is applied, the rule will not block the request. The response is going to be modified instead.
You will need some knowledge of regular expressions to use $replace modifier.
Features
$replacerules apply to any text response, but will not apply to binary (media,image,object, etc.).$replacerules do not apply if the size of the original response is more than 10 MB.$replacerules have a higher priority than other basic rules, including exception rules. So if a request matches two different rules, one of which has the$replacemodifier, this rule will be applied.- Document-level exception rules with
$contentor$documentmodifiers do disable$replacerules for requests matching them. - Other document-level exception rules (
$generichide,$elemhideor$jsinjectmodifiers) are applied alongside$replacerules. It means that you can modify the page content with a$replacerule and disable cosmetic rules there at the same time.
$replace value can be empty in the case of exception rules. See examples section for further information.
Multiple rules matching a single request
In case if multiple $replace rules match a single request, we will apply each of them. The order is defined alphabetically.
Syntax
In general, $replace syntax is similar to replacement with regular expressions in Perl.
replace = "/" regexp "/" replacement "/" modifiers
regexp— a regular expression.replacement— a string that will be used to replace the string corresponding toregexp.modifiers— a regular expression flags. For example,i— insensitive search, ors— single-line mode.
In the $replace value, two characters must be escaped: comma , and dollar sign $. Use backslash \ for it. For example, an escaped comma looks like this: \,.
Examples
||example.org^$replace=/(<VAST[\s\S]*?>)[\s\S]*<\/VAST>/\$1<\/VAST>/i
There are three parts in this rule:
regexp—(<VAST(.|\s)*?>)(.|\s)*<\/VAST>;replacement—\$1<\/VAST>where$is escaped;modifiers—ifor insensitive search.
You can see how this rule works here: https://regexr.com/3cesk
Multiple $replace rules
||example.org^$replace=/X/Y/||example.org^$replace=/Z/Y/@@||example.org/page/*$replace=/Z/Y/
- Both rule 1 and 2 will be applied to all requests sent to
example.org. - Rule 2 is disabled for requests matching
||example.org/page/, but rule 1 still works!
Disabling $replace rules
@@||example.org^$replacewill disable all$replacerules matching||example.org^.@@||example.org^$documentor@@||example.org^$contentwill disable all$replacerules originated from pages ofexample.orgincluding the page itself.
- Rules with the
$replacemodifier can only be used in trusted filters. $replacerules do not apply if the size of the original response is more than 10 MB. For AdGuard Browser Extension, this limit applies starting from v5.2 or later.
Rules with $replace modifier are supported by AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard Browser Extension for Firefox. Such rules do not work in extensions for other browsers because they are unable to modify content on the network level.
$urltransform
The $urltransform rules allow you to modify the request URL by replacing text matched by a regular expression.
Features
$urltransformrules normally only apply to the path and query parts of the URL, see below for one exception.$urltransformwill not be applied if the original URL is blocked by other rules.$urltransformwill be applied before$removeparamrules.
The $urltransform value can be empty for exception rules.
Multiple rules matching a single request
If multiple $urltransform rules match a single request, we will apply each of them. The order is defined alphabetically.
Syntax
$urltransform value is a series of one or more transformations separated by |. The first transformation is applied to the input URL. Each of the following transformations is applied to the output of the previous one. The output of a failed transformation (for example, if Base64 decoding failed or if substitution found no matches) is its input, unchanged. Formally:
urltransform = transforms
transforms = transform | transform "|" transforms
transform = substitute | decode
substitute = "/" regexp "/" replacement "/" modifiers
decode = "b64" | "pct"
substituteis similar to replacement with regular expressions in Perl.regexp— a regular expression.replacement— a string that replaces whatever is matched byregexp.$1,$2, etc. in the replacement string are replaced with the contents of the corresponding capture group.modifiers— regular expression flags, e.g.,ifor case-insensitive search.
b64— decodes a Base64-encoded string, both the default and the URL-safe alphabets are supported.pct— decodes a percent-encoded string.
In the $urltransform value, two characters must be escaped: the comma , and the dollar sign $. Use the backslash character \ for this. For example, an escaped comma looks like this: \,.
AdGuard products that use a CoreLibs version older than 1.20 only support a single substitute transformation for the value of the $urltransform modifier.
Changing the origin
This section only applies to AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for Linux with CoreLibs v1.17 or later.
As stated above, normally $urltransform rules are only allowed to change the path and query parts of the URL. However, if the rule's regexp begins with the string ^http, then the full URL is searched and can be modified by the rule. Such a rule will not be applied if the URL transformation can not be achieved via an HTTP redirect (for example, if the request's method is POST).
Examples
||example.org^$urltransform=/(pref\/).*\/(suf)/\$1\$2/i
There are three parts in this rule:
regexp—(pref\/).*\/(suf);replacement—\$1\$2where$is escaped;modifiers—ifor insensitive search.
Multiple $urltransform rules
||example.org^$urltransform=/X/Y/||example.org^$urltransform=/Z/Y/@@||example.org/page/*$urltransform=/Z/Y/
- Both rule 1 and 2 will be applied to all requests sent to
example.org. - Rule 2 is disabled for requests matching
||example.org/page/, but rule 1 still works!
Re-matching rules after transforming the URL
After applying all matching $urltransform rules, the transformed request will be matched against all other rules:
E.g., with the following rules:
||example.com^$urltransform=/firstpath/secondpath/
||example.com/secondpath^
the request to https://example.com/firstpath will be blocked.
Disabling $urltransform rules
@@||example.org^$urltransformwill disable all$urltransformrules matching||example.org^.@@||example.org^$urltransform=/Z/Y/will disable the rule with$urltransform=/Z/Y/for any request matching||example.org^.
$urltransform rules can also be disabled by $document and $urlblock exception rules. But basic exception rules without modifiers do not do that. For example, @@||example.com^ will not disable $urltransform=/X/Y/ for requests to example.com, but @@||example.com^$urlblock will.
The rule example for cleaning affiliate links
Many websites use tracking URLs to monitor clicks before redirecting to the actual destination. These URLs contain marketing parameters and analytics tokens that can be removed to improve privacy.
Below is an example of how to obtain the clean destination link to bypass tracking websites and go directly to the destination.
In our example:
- The initial URL (with click tracking):
https://www.aff.example.com/visit?url=https%3A%2F%2Fwww.somestore.com%2F%26referrer%3Dhttps%3A%2F%2Fwww.aff.example.com%2F%26ref%3Dref-123 - Tracking URL after decoding special characters:
https://www.aff.example.com/visit?url=https://www.somestore.com/ - The website you want to visit:
https://www.somestore.com
To clean the URL, we first need to decode special characters (like %3A → :, %2F → /, etc.) and extract the real URL from the tracking parameters. We will use the $urltransform modifier to do this. The following 4 rules replace URL-encoded symbols with their real characters:
/^https?:\/\/(?:[a-z0-9-]+\.)*?aff\.example\.com\/visit\?url=/$urltransform=/%3A/:/ /^https?:\/\/(?:[a-z0-9-]+\.)*?aff\.example\.com\/visit\?url=/$urltransform=/%2F/\// /^https?:\/\/(?:[a-z0-9-]+\.)*?aff\.example\.com\/visit\?url=/$urltransform=/%3F/?/ /^https?:\/\/(?:[a-z0-9-]+\.)*?aff\.example\.com\/visit\?url=/$urltransform=/%3D/=/ /^https?:\/\/(?:[a-z0-9-]+\.)*?aff\.example\.com\/visit\?url=/$urltransform=/%26/&/
After that, we need to write the rule that will block the tracking website and redirect you directly to the target address (somestore.com):
/^https?:\/\/(?:[a-z0-9-]+\.)*?aff\.example\.com\/visit\?url=/$urltransform=/^https?:\/\/(?:[a-z0-9-]+\.)*?aff\.example\.com.*url=([^&]*).*/\$1/
Tracking links will now be automatically cleaned up, allowing direct navigation to the destination website without tracking.
Rules with the $urltransform modifier can only be used in trusted filters.
$urltransform rules without content-type modifiers will only match requests where the content type is document.
Rules with the $urltransform modifier are supported by AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for Linux with CoreLibs v1.15 or later.
$urltransform rules with content-type modifiers are supported starting from CoreLibs v1.19 or later. In earlier versions, content-type modifiers were not allowed with $urltransform.
$reason
The $reason modifier allows you to add a custom explanation message that will be displayed on the blocking page when a request is blocked by this rule. This modifier only works with the $document content-type modifier.
Character limitations and escaping requirements:
- There is no maximum length limit for the reason text
- All characters are allowed in the reason text
- Special characters (such as quotes, commas, and backslashes) must be properly escaped using the backslash (
\)
Predefined localizable tokens:
Instead of custom text, you can use predefined tokens that will be automatically localized:
malicious— for malicious contenttracker— for tracking contentdisreputable— for disreputable content
Examples
||example.com^$document,reason="Tracker"
||example.com^$document,reason="Malicious site blocked by security filter"
||ads.example.com^$document,reason="This site contains tracking scripts"
||malware.example.com^$document,reason="Site blocked: \"Known malware distributor\""
||tracking.example.com^$document,reason=disreputable
||analytics.example.com^$document,reason=tracker
AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for Linux with CoreLibs v1.20 or later support rules with the $reason modifier. AdGuard Content Blocker does not support these rules.
noop
noop modifier does nothing and can be used solely to increase rules' readability. It consists of a sequence of underscore characters (_) of arbitrary length and can appear in a rule as often as needed.
Examples
||example.com$_,removeparam=/^ss\\$/,_,image
||example.com$replace=/bad/good/,___,~third-party
Rules with noop modifier are not supported by AdGuard Content Blocker.
$empty (deprecated)
This modifier is deprecated in favor of the $redirect modifier. Rules with $empty are still supported and being converted into $redirect=nooptext now but the support shall be removed in the future.
Usually, blocked requests look like a server error to browser. If you use $empty modifier, AdGuard will emulate a blank response from the server with200 OK status.
Examples
||example.org^$emptyreturns an empty response to all requests toexample.organd all subdomains.
Rules with $empty modifier are not supported by AdGuard Content Blocker, AdGuard for iOS, and AdGuard for Safari.
$mp4 (deprecated)
This modifier is deprecated in favor of the $redirect modifier. Rules with $mp4 are still supported and being converted into $redirect=noopmp4-1s,media now but the support shall be removed in the future.
As a response to blocked request AdGuard returns a short video placeholder.
Examples
||example.com/videos/$mp4blocks all video downloads from||example.com/videos/*and changes the response to a video placeholder.
Rules with $mp4 modifier are not supported by AdGuard Content Blocker, AdGuard for iOS, and AdGuard for Safari.
Rule priorities
Each rule has its own priority, which is necessary when several rules match the request and the filtering engine needs to select one of them. Priority is measured by a positive integer.
When two rules with the same priority match the same request, the filter engine implementation determines which one is chosen.
The concept of rule priorities becomes increasingly important in light of Manifest V3, as the existing rules need to be converted to declarativeNetRequest rules.
Priority calculation
To calculate priority, we've categorized modifiers into different groups. These groups are ranked based on their priority, from lowest to highest. A modifier that significantly narrows the scope of a rule adds more weight to its total priority. Conversely, if a rule applies to a broader range of requests, its priority decreases.
It's worth noting that there are cases where a single-parameter modifier has a higher priority than multi-parameter ones. For instance, in the case of $domain=example.com|example.org, a rule that includes two domains has a slightly broader effective area than a rule with one specified domain, therefore its priority is lower.
The base priority of any rule is 1. If the calculated priority is a floating-point number, it will be rounded up to the smallest integer greater than or equal to the calculated priority.
- The concept of priority has been introduced in TSUrlFilter v2.1.0 and CoreLibs v1.13. Before that AdGuard didn't have any special priority computation algorithm and collisions handling could be different depending on AdGuard product and version.
- AdGuard for iOS, Safari, and AdGuard Content Blocker rely on the browsers implementation and they cannot follow the rules specified here.
Modifier aliases (1p, 3p, etc.) are not included in these categories, however, they are utilized within the engine to compute the rule priority.
Basic modifiers, the presence of each adds 1 to the priority
$appwith negated applications using~,$denyallow,$domainwith negated domains using~,$match-case,$methodwith negated methods using~,$strict-first-party,$strict-third-party,$third-party,$to,- restricted content-types with
~.
When dealing with a negated domain, app, method, or content-type, we add 1 point for the existence of the modifier itself, regardless of the quantity of negated domains or content-types. This is because the rule's scope is already infinitely broad. Put simply, by prohibiting multiple domains, content-types, methods or apps, the scope of the rule becomes only minimally smaller.
Defined content-type modifiers, defined methods, defined headers, $all, $popup, specific exceptions
All valid content types:
$document,$font,$image,$media,$object,$other,$ping,$script,$stylesheet,$subdocument,$websocket,$xmlhttprequest;
This also includes rules that implicitly add all content types:
$all;
Or rules that implicitly add the modifier $document:
Or some specific exceptions that implicitly add $document,subdocument:
Or allowed methods via $method.
Or rules with $header.
The presence of any content-type modifiers adds (50 + 50 / N), where N is the number of modifiers present, for example: ||example.com^$image,script will add 50 + 50 / 2 = 50 + 25 = 75 to the total weight of the rule.
The $all also belongs to this category, because it implicitly adds all content-type modifiers, e.g., $document,subdocument,image,script,media,<etc> + $popup.
The $popup also belongs to this category, because it implicitly adds the modifier $document. Similarly, specific exceptions add $document,subdocument.
If there is a $method modifier in the rule with allowed methods it adds (50 + 50 / N), where N is the number of methods allowed, for example: ||example.com^$method=GET|POST|PUT will add 50 + 50 / 3 = 50 + 16.6 = 67 to the total weight of the rule.
If there is a $header modifier in the rule, it adds 50.
$domain or $app with allowed domains or applications
Specified domains through $domain or specified applications through $app add 100 + 100 / N, where N is the number of modifier values for example: ||example.com^$domain=example.com|example.org|example.net will add 100 + 100 / 3 = 134.3 = 135 or ||example.com^$app=org.example.app1|org.example.app2 will add 100 + 100 / 2 = 151 or ||example.com^$domain=example.com,app=org.example.app1|org.example.app2 will add 100 + 100/1 ($domain part) and 100 + 100/2 ($app part), totaling 350.
Modifier values that are regexps or tld will be interpreted as normal entries of the form example.com and counted one by one, for example: ||example.com^$domain=example.* will add 100 + 100 / 1 = 200 or ||example.com^$domain=example.*|adguard.* will add 100 + 100 / 2 = 150.
$redirect rules
Each of which adds 10^3 to rule priority.
Specific exceptions
Each of which adds 10^4 to the priority.
As well as exception with $document modifier: because it's an alias for $elemhide,content,jsinject,urlblock,extension. It will add 10^4 for each modifier from the top list, 10^4 * 5 in total.
In addition, each of these exceptions implicitly adds the two allowed content-type modifiers $document,subdocument.
Allowlist rules
Modifier @@ adds 10^5 to rule priority.
$important rules
Modifier $important adds 10^6 to rule priority.
Rules for which there is no priority weight
Other modifiers, which are supposed to perform additional post- or pre-processing of requests, do not add anything to the rule priority.
Examples
-
||example.com^Weight of the rule without modifiers:
1. -
||example.com^$match-caseRule weight: base weight + weight of the modifier from category 1:
1 + 1 = 2. -
||example.org^$removeparam=pRule weight: base weight + 0, since $removeparam is not involved in the priority calculation:
1 + 0 = 1. -
||example.org^$document,redirect=nooptextRule weight: base weight + allowed content type, category 3 + $redirect from category 6:
1 + (100 + 100 / 1) + 1000 = 1201. -
@@||example.org^$removeparam=p,documentRule weight: base weight + allowlist rule, category 5 + 0 because $removeparam is not involved in the priority calculation + allowed content type, category 2:
1 + 10000 + 0 + (50 + 50 / 1) = 10101. -
@@||example.com/ad/*$domain=example.org|example.net,importantRule weight: base weight + allowlist rule, category 5 + important rule, category 7 + allowed domains, category 3:
1 + 10000 + 1000000 + (100 + 100 / 2) = 1010152. -
@@||example.org^$documentwithout additional modifiers is an alias for@@||example.com^$elemhide,content,jsinject,urlblock,extensionRule weight: base weight + specific exceptions, category 4 + two allowed content types (document and subdocument), category 2:
1 + 10000 * 4 + (50 + 50 / 2) = 40076. -
*$script,domain=a.com,denyallow=x.com|y.comRule weight: base weight + allowed content type, category 2 + allowed domain, category 3 + denyallow, category 1:
1 + (50 + 50/1) + (100 + 100 / 1) + 1 = 303. -
||example.com^$all— alias to||example.com^$document,subdocument,image,script,media,etc. + $popupRule weight: base weight + popup (category 1) + allowed content types (category 2):
1 + 1 + (50 + 50/12) = 55.
Non-basic rules
However, basic rules may not be enough to block ads. Sometimes you need to hide an element or change part of the HTML code of a web page without breaking anything. The rules described in this section are created specifically for this purpose.
| Categories \ Products | CoreLibs apps | AdGuard para Chromium | AdGuard para Chrome MV3 | AdGuard para Firefox | AdGuard para iOS | AdGuard para Safari | Bloqueador de contenido AdGuard |
|---|---|---|---|---|---|---|---|
| Element hiding | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| CSS rules | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| Extended CSS | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| HTML filtering | ✅ | ❌ | ❌ | ✅ | ❌ | ❌ | ❌ |
| JavaScript | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| Scriptlets | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
- ✅ — totalmente compatible
- ❌ — not supported
Cosmetic rules
Work with non-basic rules requires the basic knowledge of HTML and CSS. So, if you want to learn how to make such rules, we recommend to get acquainted with this documentation.
Element hiding rules
Element hiding rules are used to hide the elements of web pages. It is similar to applying { display: none; } style to selected element.
Element hiding rules may operate differently depending on the platform.
Syntax
rule = [domains] "##" selector
domains = [domain0, domain1[, ...[, domainN]]]
selector— CSS selector, defines the elements to be hidden.domains— domain restriction for the rule.
If you want to limit the rule application area to certain domains, just enter them separated with commas. For example: example.org,example.com##selector.
This rule will be also applied to all subdomains of example.org and example.com.
If you want the rule not to be applied to certain domains, start a domain name with ~ sign. For example: ~example.org##selector.
You can use both approaches in a single rule. For example, example.org,~subdomain.example.org##domain will work for example.org and all subdomains, except subdomain.example.org.
Element hiding rules are not dependent on each other. If there is a rule example.org##selector in the filter and you add ~example.org##selector both rules will be applied independently.
Examples
example.com##div.textad— hides adivwith the classtextadatexample.comand all subdomains.example.com,example.org###adblock— hides an element with attributeidequalsadblockatexample.com,example.organd all subdomains.~example.com##.textad— hides an element with the classtextadat all domains, exceptexample.comand its subdomains.
Limitaciones
Safari does not support both allowed and disallowed domains. So the rules like example.org,~foo.example.org##.textad are invalid in AdGuard for Safari.
Exceptions
Exceptions can disable some rules on particular domains. They are very similar to usual exception rules, but instead of ## you have to use #@#.
For example, there is a rule in filter:
##.textad
If you want to disable it for example.com, you can create an exception rule:
example.com#@#.textad
Sometimes, it may be necessary to disable all restriction rules. For example, to conduct tests. To do this, use the exclusion rule without specifying a domain. It will completely disable matching CSS elemhide rule on ALL domains:
#@#.textad
The same can be achieved by adding this rule:
*#@#.textad
We recommend to use this kind of exceptions only if it is not possible to change the hiding rule itself. In other cases it is better to change the original rule, using domain restrictions.
CSS rules
Sometimes, simple hiding of an element is not enough to deal with advertising. For example, blocking an advertising element can just break the page layout. In this case AdGuard can use rules that are much more flexible than hiding rules. With these rules you can basically add any CSS styles to the page.
Syntax
rule = [domains] "#$#" selector "{" style "}"
domains = [domain0, domain1[, ...[, domainN]]]
selector— CSS selector, that defines the elements we want to apply the style to.domains— domain restriction for the rule. Same principles as in element hiding rules.style— CSS style, that we want to apply to selected elements.
Examples
example.com#$#body { background-color: #333!important; }
This rule will apply a style background-color: #333!important; to the body element at example.com and all subdomains.
Exceptions
Just like with element hiding, there is a type of rules that disable the selected CSS style rule for particular domains. Exception rule syntax is almost the same, you just have to change #$# to #@$#.
For example, there is a rule in filter:
#$#.textad { visibility: hidden; }
If you want to disable it for example.com, you can create an exception rule:
example.com#@$#.textad { visibility: hidden; }
We recommend to use this kind of exceptions only if it is not possible to change the CSS rule itself. In other cases it is better to change the original rule, using domain restrictions.
Styles that lead to loading any resource are forbidden. Basically, it means that you cannot use any <url> type of value in the style.
CSS rules are not supported by AdGuard Content Blocker.
CSS rules may operate differently depending on the platform.
In AdGuard products that use CoreLibs version 1.18 or later, you can also use element hiding rules to inject a remove: true declaration:
example.org##body { remove: true; }
This usage is discouraged in favor of using CSS rules and is only supported for compatibility with filter lists written for Adblock Plus.
Element hiding exceptions (#@#) are matched by the selector part only, ignoring the declarations block part. For example, the above rule can be disabled by any of the following exception rules:
example.org#@#body
example.org#@#body { remove: true; }
example.org#@#body{remove:true;}
Extended CSS selectors
- Limitaciones
- Pseudo-class
:has() - Pseudo-class
:contains() - Pseudo-class
:matches-css() - Pseudo-class
:matches-attr() - Pseudo-class
:matches-property() - Pseudo-class
:xpath() - Pseudo-class
:nth-ancestor() - Pseudo-class
:upward() - Pseudo-class
:remove()and pseudo-propertyremove - Pseudo-class
:is() - Pseudo-class
:not() - Pseudo-class
:empty-trimmed - Pseudo-class
:if-not()(removed)
CSS 3.0 is not always enough to block ads. To solve this problem AdGuard extends CSS capabilities by adding support for the new pseudo-elements. We have developed a separate open-source library for non-standard element selecting and applying CSS styles with extended properties.
The idea of extended capabilities is an opportunity to match DOM elements with selectors based on their own representation (style, text content, etc.) or relations with other elements. There is also an opportunity to apply styles with non-standard CSS properties.
Application area
Extended selectors can be used in any cosmetic rule, whether they are element hiding rules or CSS rules.
Rules with extended CSS selectors are not supported by AdGuard Content Blocker.
Syntax
Regardless of the CSS pseudo-classes you are using in the rule, you can use special markers to force applying these rules by ExtendedCss. It is recommended to use these markers for all extended CSS cosmetic rules so that it was easier to find them.
The syntax for extended CSS rules:
#?#— for element hiding,#@?#— for exceptions#$?#— for CSS rules,#@$?#— for exceptions
We strongly recommend using these markers any time when you use an extended CSS selector.
Examples
example.org#?#div:has(> a[target="_blank"][rel="nofollow"])— this rule blocks alldivelements containing a child node that has a link with the attributes[target="_blank"][rel="nofollow"]. The rule applies only toexample.organd its subdomains.example.com#$?#h3:contains(cookies) { display: none!important; }— this rule sets the styledisplay: none!importantto allh3elements that contain the wordcookies. The rule applies only toexample.comand all its subdomains.example.net#?#.banner:matches-css(width: 360px)— this rule blocks all.bannerelements with the style propertywidth: 360px. The rule applies only toexample.netand its subdomains.example.net#@?#.banner:matches-css(width: 360px)— this rule will disable the previous rule.
You can apply standard CSS selectors using the ExtendedCss library by using the rule marker #?#, e.g. #?#div.banner.
Learn more about how to debug extended selectors.
Some pseudo-classes do not require selector before it. Still adding the universal selector * makes an extended selector easier to read, even though it has no effect on the matching behavior. So selector #block :has(> .inner) works exactly like #block *:has(> .inner), but the second one is more obvious.
Pseudo-class names are case-insensitive, e.g. :HAS() works as :has(). Still the lower-case names are used commonly.
ExtendedCss Limitations
-
Specific pseudo-class may have its own limitations:
:has(),:xpath(),:nth-ancestor(),:upward(),:is(),:not(), and:remove().
Pseudo-class :has()
Draft CSS 4.0 specification describes the :has() pseudo-class. Unfortunately, it is not yet supported by all popular browsers.
Rules with the :has() pseudo-class must use the native implementation of :has() if they use the ## rule marker and if it is possible, i.e., there are no other extended CSS selectors inside. If it is not supported by the product (or by the browser in case of AdGuard Browser Extension), ExtendedCss implementation will be used automatically as a fallback, even for rules with the ## marker.
AdGuard products support the native implementation of :has():
- AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for Linux support it with CoreLibs v1.12 or later.
- AdGuard for iOS and AdGuard for Safari support it with SafariConverterLib v2.0.39 and Safari browser v16.4 or later.
- AdGuard Browser Extension supports it in v5.3 or later:
- Manifest V3 (Chromium-based): always uses native
:has()by default. - Manifest V2: Detects native
:has()support usingCSS.supports()and falls back to ExtendedCss if the browser doesn’t support it natively.
- Manifest V3 (Chromium-based): always uses native
- All other AdGuard products do not support it.
To force the ExtendedCss implementation of :has() to be used (regardless of native support), use the #?# or #$?# rule markers explicitly, e.g., example.com#?#p:has(> a) or example.com#$?#div:has(> span) { display: none !important; }.
And since the :has() pseudo-class cannot be nested within another :has() in native implementation, e.g. div:has(p:has(a)), it is always treated as extended in AdGuard Browser Extension.
Compatibility with other pseudo-classes
Synonyms :-abp-has() is supported by ExtendedCss for better compatibility.
:if() is no longer supported as a synonym for :has().
Syntax
[target]:has(selector)
target— optional, standard or extended CSS selector, can be skipped for checking any elementselector— required, standard or extended CSS selector
The pseudo-class :has() selects the target elements that fit to the selector. Also the selector can start with a combinator.
A selector list can be set in selector as well. In this case all selectors in the list are being matched for now. In the future it will be fixed for <forgiving-relative-selector-list> as argument.
:has() limitations
Usage of the :has() pseudo-class is restricted for some cases (2, 3):
- disallow
:has()inside the pseudos accepting only compound selectors; - disallow
:has()after regular pseudo-elements.
Native :has() pseudo-class does not allow :has(), :is(), :where() inside :has() argument to avoid increasing the :has() invalidation complexity (case 1). But ExtendedCss did not have such limitation earlier and filter lists already contain such rules, so we have not added this limitation to ExtendedCss and allow to use :has() inside :has() as it was possible before. To use it, just force ExtendedCss usage by setting #?#/#$?# rule marker.
Native implementation does not allow any usage of :scope inside the :has() argument ([1], [2]). Still, there are some such rules in filter lists: div:has(:scope a) which we continue to support by simply converting them to div:has(> a), as it used to be done previously.
Examples
div:has(.banner) selects all div elements which include an element with the banner class:
<!-- HTML code -->
<div>Not selected</div>
<div>Selected
<span class="banner">inner element</span>
</div>
div:has(> .banner) selects all div elements which include an banner class element as a direct child of div:
<!-- HTML code -->
<div>Not selected</div>
<div>Selected
<p class="banner">child element</p>
</div>
div:has(+ .banner) selects all div elements preceding banner class element which immediately follows the div and both are children of the same parent:
<!-- HTML code -->
<div>Not selected</div>
<div>Selected</div>
<p class="banner">adjacent sibling</p>
<span>Not selected</span>
div:has(~ .banner) selects all div elements preceding banner class element which follows the div but not necessarily immediately and both are children of the same parent:
<!-- HTML code -->
<div>Not selected</div>
<div>Selected</div>
<span>Not selected</span>
<p class="banner">general sibling</p>
div:has(span, .banner) selects all div elements which include both span element and banner class element:
<!-- HTML code -->
<div>Not selected</div>
<div>Selected
<span>child span</span>
<p class="banner">child .banner</p>
</div>
Backward compatible syntax for :has() is supported but not recommended.
Pseudo-class :contains()
The :contains() pseudo-class principle is very simple: it allows to select the elements that contain specified text or which content matches a specified regular expression. Regexp flags are supported.
The :contains() pseudo-class uses the textContent element property for matching, not the innerHTML.
Compatibility with other pseudo-classes
Synonyms :-abp-contains() and :has-text() are supported for better compatibility.
Syntax
[target]:contains(match)
target— optional, standard or extended CSS selector, can be skipped for checking any elementmatch— required, string or regular expression for matching elementtextContent. Regular expression flags are supported.
Examples
For such DOM:
<!-- HTML code -->
<div>Not selected</div>
<div id="match">Selected as IT contains "banner"</div>
<div>Not selected <div class="banner"></div></div>
the element div#match can be selected by any of these extended selectors:
! plain text
div:contains(banner)
! regular expression
div:contains(/as .*banner/)
! regular expression with flags
div:contains(/it .*banner/gi)
Only the div with id=match is selected because the next element does not contain any text, and banner is a part of code, not a text.
Backward compatible syntax for :contains() is supported but not recommended.
Pseudo-class :matches-css()
The :matches-css() pseudo-class allows to match the element by its current style properties. The work of the pseudo-class is based on using the Window.getComputedStyle() method.
Syntax
[target]:matches-css([pseudo-element, ] property: pattern)
target— optional, standard or extended CSS selector, can be skipped for checking any elementpseudo-element— optional, valid standard pseudo-element, e.g.before,after,first-line, etc.property— required, a name of CSS property to check the element forpattern— required, a value pattern that is using the same simple wildcard matching as in the basic URL filtering rules or a regular expression. For this type of matching, AdGuard always does matching in a case-insensitive manner. In the case of a regular expression, the pattern looks like/regexp/.
Special characters escaping and unescaping
For non-regexp patterns (,),[,] must be unescaped, e.g. :matches-css(background-image:url(data:*)).
For regexp patterns \ should be escaped, e.g. :matches-css(background-image: /^url\\("data:image\\/gif;base64.+/).
Examples
For such DOM:
<!-- HTML code -->
<style type="text/css">
#matched::before {
content: "Block me"
}
</style>
<div id="matched"></div>
<div id="not-matched"></div>
the div elements with pseudo-element ::before and with specified content property can be selected by any of these extended selectors:
! string pattern
div:matches-css(before, content: block me)
! string pattern with wildcard
div:matches-css(before, content: block*)
! regular expression pattern
div:matches-css(before, content: /block me/)
Regexp patterns do not support flags.
Obsolete pseudo-classes :matches-css-before() and :matches-css-after() are no longer recommended but still are supported for better compatibility.
Backward compatible syntax for :matches-css() is supported but not recommended.
Pseudo-class :matches-attr()
The :matches-attr() pseudo-class allows selecting an element by its attributes, especially if they are randomized.
Syntax
[target]:matches-attr("name"[="value"])
target— optional, standard or extended CSS selector, can be skipped for checking any elementname— required, simple string or string with wildcard or regular expression for attribute name matchingvalue— optional, simple string or string with wildcard or regular expression for attribute value matching
Escaping special characters
For regexp patterns " and \ should be escaped, e.g. div:matches-attr(class=/[\\w]{5}/).
Examples
div:matches-attr("ad-link") selects the element div#target1:
<!-- HTML code -->
<div id="target1" ad-link="1random23-banner_240x400"></div>
div:matches-attr("data-*"="adBanner") selects the element div#target2:
<!-- HTML code -->
<div id="target2" data-1random23="adBanner"></div>
div:matches-attr(*unit*=/^click$/) selects the element div#target3:
<!-- HTML code -->
<div id="target3" random123-unit094="click"></div>
*:matches-attr("/.{5,}delay$/"="/^[0-9]*$/") selects the element #target4:
<!-- HTML code -->
<div>
<inner-random23 id="target4" nt4f5be90delay="1000"></inner-random23>
</div>
Regexp patterns do not support flags.
Pseudo-class :matches-property()
The :matches-property() pseudo-class allows selecting an element by matching its properties.
Syntax
[target]:matches-property("name"[="value"])
target— optional, standard or extended CSS selector, can be skipped for checking any elementname— required, simple string or string with wildcard or regular expression for element property name matchingvalue— optional, simple string or string with wildcard or regular expression for element property value matching
Escaping special characters
For regexp patterns " and \ must be escaped, e.g. div:matches-property(prop=/[\\w]{4}/).
Regexp patterns are supported in name for any property in chain, e.g. prop./^unit[\\d]{4}$/.type.
Examples
An element with such properties:
divProperties = {
id: 1,
check: {
track: true,
unit_2random1: true,
},
memoizedProps: {
key: null,
tag: 12,
_owner: {
effectTag: 1,
src: 'ad.com',
},
},
};
can be selected by any of these extended selectors:
div:matches-property(check.track)
div:matches-property("check./^unit_.{4,8}$/")
div:matches-property("check.unit_*"=true)
div:matches-property(memoizedProps.key="null")
div:matches-property(memoizedProps._owner.src=/ad/)
To check properties of a specific element, do the following:
- Inspect the page element or select it in
Elementstab of browser DevTools - Run
console.dir($0)inConsoletab
Regexp patterns do not support flags.
Pseudo-class :xpath()
The :xpath() pseudo-class allows selecting an element by evaluating an XPath expression.
Syntax
[target]:xpath(expression)
target- optional, standard or extended CSS selectorexpression— required, valid XPath expression
:xpath() limitations
target can be omitted so it is optional. For any other pseudo-class that would mean "apply to all DOM nodes", but in case of :xpath() it just means "apply to the whole document", and such applying slows elements selecting significantly. That's why rules like #?#:xpath(expression) are limited to looking inside the body tag. For example, rule #?#:xpath(//div[@data-st-area=\'Advert\']) is parsed as #?#body:xpath(//div[@data-st-area=\'Advert\']).
Extended selectors with defined target as any selector — *:xpath(expression) — can still be used but it is not recommended, so target should be specified instead.
Works properly only at the end of selector, except for pseudo-class :remove().
Examples
:xpath(//*[@class="banner"]) selects the element div#target1:
<!-- HTML code -->
<div id="target1" class="banner"></div>
:xpath(//*[@class="inner"]/..) selects the element div#target2:
<!-- HTML code -->
<div id="target2">
<div class="inner"></div>
</div>
Pseudo-class :nth-ancestor()
The :nth-ancestor() pseudo-class allows to lookup the nth ancestor relative to the previously selected element.
subject:nth-ancestor(n)
subject— required, standard or extended CSS selectorn— required, number >= 1 and < 256, distance to the needed ancestor from the element selected bysubject
Syntax
subject:nth-ancestor(n)
subject— required, standard or extended CSS selectorn— required, number >= 1 and < 256, distance to the needed ancestor from the element selected bysubject
:nth-ancestor() limitations
The :nth-ancestor() pseudo-class is not supported inside the argument of the :not() pseudo-class.
Examples
For such DOM:
<!-- HTML code -->
<div id="target1">
<div class="child"></div>
<div id="target2">
<div>
<div>
<div class="inner"></div>
</div>
</div>
</div>
</div>
.child:nth-ancestor(1) selects the element div#target1, div[class="inner"]:nth-ancestor(3) selects the element div#target2.
Pseudo-class :upward()
The :upward() pseudo-class allows to lookup the ancestor relative to the previously selected element.
Syntax
subject:upward(ancestor)
subject— required, standard or extended CSS selectorancestor— required, specification for the ancestor of the element selected bysubject, can be set as:- number >= 1 and < 256 for distance to the needed ancestor, same as
:nth-ancestor() - standard CSS selector for matching closest ancestor
- number >= 1 and < 256 for distance to the needed ancestor, same as
:upward() limitations
The :upward() pseudo-class is not supported inside the argument of the :not() pseudo-class.
Examples
For such DOM:
<!-- HTML code -->
<div id="target1" data="true">
<div class="child"></div>
<div id="target2">
<div>
<div>
<div class="inner"></div>
</div>
</div>
</div>
</div>
.inner:upward(div[data]) selects the element div#target1, .inner:upward(div[id]) selects the element div#target2, .child:upward(1) selects the element div#target1, .inner:upward(3) selects the element div#target2.
Pseudo-class :remove() and pseudo-property remove
Sometimes, it is necessary to remove a matching element instead of hiding it or applying custom styles. In order to do it, you can use the :remove() pseudo-class as well as the remove pseudo-property.
Pseudo-class :remove() can be placed only at the end of a selector.
Syntax
! pseudo-class
selector:remove()
! pseudo-property
selector { remove: true; }
selector— required, standard or extended CSS selector
:remove() and remove limitations
The :remove() pseudo-class is limited to work properly only at the end of selector.
For applying the :remove() pseudo-class to any element, the universal selector * should be used. Otherwise such extended selector may be considered as invalid, e.g. .banner > :remove() is not valid for removing any child element of banner class element, so it should look like .banner > *:remove().
If the :remove() pseudo-class or the remove pseudo-property is used, all style properties are ignored except for the debug pseudo-property.
Examples
div.banner:remove()
div:has(> div[ad-attr]):remove()
div:contains(advertisement) { remove: true; }
div[class]:has(> a > img) { remove: true; }
Rules with the remove pseudo-property must use #$?# marker: $ for CSS-style rule syntax, ? for ExtendedCss syntax.
Pseudo-class :is()
The :is() pseudo-class allows to match any element that can be selected by any of selectors passed to it. Invalid selectors are skipped and the pseudo-class deals with valid ones with no error thrown. Our implementation of the native :is() pseudo-class.
Syntax
[target]:is(selectors)
target— optional, standard or extended CSS selector, can be skipped for checking any elementselectors— forgiving selector list of standard or extended selectors. For extended selectors, only compound selectors are supported, not complex.
:is() limitations
Rules with the :is() pseudo-class must use the native implementation of :is() if rules use ## marker and it is possible, i.e. with no other extended selectors inside. To force applying ExtendedCss rules with :is(), use #?#/#$?# marker explicitly.
If the :is() pseudo-class argument selectors is an extended selector, due to the way how the :is() pseudo-class is implemented in ExtendedCss v2.0, it is impossible to apply it to the top DOM node which is html, i.e. #?#html:is(<extended-selectors>) does not work. So if target is not defined or defined as the universal selector *, the extended pseudo-class applying is limited to html's children, e.g. rules #?#:is(...) and #?#*:is(...) are parsed as #?#html *:is(...). Please note that there is no such limitation for a standard selector argument, i.e. #?#html:is(.locked) works fine.
Complex selectors with extended pseudo-classes are not supported as selectors argument for :is() pseudo-class, only compound ones are allowed. Check examples below for more details.
Examples
#container *:is(.inner, .footer) selects only the element div#target1:
<!-- HTML code -->
<div id="container">
<div data="true">
<div>
<div id="target1" class="inner"></div>
</div>
</div>
</div>
Due to limitations :is(*:not([class]) > .banner)' does not work but :is(*:not([class]):has(> .banner)) can be used instead of it to select the element div#target2:
<!-- HTML code -->
<span class="span">text</span>
<div id="target2">
<p class="banner">inner paragraph</p>
</div>
Pseudo-class :not()
The :not() pseudo-class allows to select elements which are not matched by selectors passed as argument. Invalid argument selectors are not allowed and error is to be thrown. Our implementation of the :not() pseudo-class.
Syntax
[target]:not(selectors)
target— optional, standard or extended CSS selector, can be skipped for checking any elementselectors— list of standard or extended selectors
:not() limitations
Rules with the :not() pseudo-class must use the native implementation of :not() if rules use ## marker and it is possible, i.e. with no other extended selectors inside. To force applying ExtendedCss rules with :not(), use #?#/#$?# marker explicitly.
If the :not() pseudo-class argument selectors is an extended selector, due to the way how the :not() pseudo-class is implemented in ExtendedCss v2.0, it is impossible to apply it to the top DOM node which is html, i.e. #?#html:not(<extended-selectors>) does not work. So if target is not defined or defined as the universal selector *, the extended pseudo-class applying is limited to html's children, e.g. rules #?#:not(...) and #?#*:not(...) are parsed as #?#html *:not(...). Please note that there is no such limitation for a standard selector argument, i.e. #?#html:not(.locked) works fine.
The :not() is considered as a standard CSS pseudo-class inside the argument of the :upward() pseudo-class because :upward() supports only standard selectors.
"Up-looking" pseudo-classes which are :nth-ancestor() and :upward() are not supported inside selectors argument for :not() pseudo-class.
Examples
#container > *:not(h2, .text) selects only the element div#target1:
<!-- HTML code -->
<div id="container">
<h2>Header</h2>
<div id="target1"></div>
<span class="text">text</span>
</div>
Pseudo-class :empty-trimmed
The :empty-trimmed pseudo-class allows selecting elements without text content. Unlike the native CSS :empty pseudo-class, which matches elements that have no child nodes at all (no elements, no text nodes), :empty-trimmed checks textContent of the element and its descendants. It also matches elements whose text content consists only of whitespace, including non-breaking spaces such as .
Syntax
[target]:empty-trimmed
target— optional, standard or extended CSS selector, can be skipped for checking any element
This pseudo-class has no arguments.
Added in ExtendedCSS v2.0.0.
Rules with the :empty-trimmed pseudo-class are supported by AdGuard Browser Extension v5.5 or later. Such rules do not work in AdGuard Content Blocker.
Examples
div > p:empty-trimmed selects p#empty, p#spaces, p#nbsp, p#child-empty, and p#comment:
<!-- HTML code -->
<div>
<p id="empty"></p>
<p id="spaces"> </p>
<p id="nbsp"> </p>
<p id="text">hello</p>
<p id="child-empty"><span></span></p>
<p id="child-text"><span>world</span></p>
<p id="comment"><!-- hidden --></p>
<p id="zwsp">​</p>
</div>
div > p:not(:empty-trimmed) selects p#text, p#child-text, and p#zwsp.
An element like <p><span></span></p> matches :empty-trimmed (its text content is empty) but does not match native :empty (it has a child <span> node).
Elements containing only HTML comments (e.g. <!-- hidden -->) also match :empty-trimmed, because comment nodes are not reflected in textContent.
Zero-width characters such as zero-width space (\u200B) are not treated as whitespace. An element containing only zero-width characters does not match :empty-trimmed.
Pseudo-class :if-not() (removed)
The :if-not() pseudo-class is removed and is no longer supported. Rules with it are considered as invalid.
This pseudo-class was basically a shortcut for :not(:has()). It was supported by ExtendedCss for better compatibility with some filters subscriptions.
Cosmetic rules priority
The way element hiding and CSS rules are applied is platform-specific.
In AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for Linux, we use a stylesheet injected into the page. The priority of cosmetic rules is the same as any other websites' CSS stylesheet. But there is a limitation: element hiding and CSS rules cannot override inline styles. In such cases, it is recommended to use extended selectors or HTML filtering.
In AdGuard Browser Extension, the so-called "user stylesheets" are used. They have higher priority than even the inline styles.
Extended CSS selectors use JavaScript to work and basically add an inline style themselves, therefore they can override any style.
HTML filtering rules
In most cases, the basis and cosmetic rules are enough to filter ads. But sometimes it is necessary to change the HTML-code of the page itself before it is loaded. This is when you need filtering rules for HTML content. They allow to indicate the HTML elements to be cut out before the browser loads the page.
HTML filtering rules are supported by AdGuard for Windows, AdGuard for Mac, AdGuard for Android, AdGuard for Linux, and AdGuard Browser Extension for Firefox. Such rules do not work in extensions for other browsers because they are unable to modify content on network level.
The syntax with an optional value in the attributes is supported by AdGuard for Windows, AdGuard for Mac, and AdGuard for Android with CoreLibs v1.18 or later. It is also supported by AdGuard Browser Extension v5.2 or later. For the other products and previous versions value must always be specified. Otherwise, the rule will be treated as incorrect and ignored.
Syntax
Syntax supported by AdGuard for Windows, AdGuard for Mac, AdGuard for Android, AdGuard for Linux with CoreLibs, and AdGuard Browser Extension prior to v5.2:
selector = [tagName] [attributes] [pseudoClasses]
combinator = ">"
rule = [domains] "$$" selector *(combinator selector)
domains = [domain0, domain1[, ...[, domainN]]]
attributes = "[" name0[ = value0] "]" "[" name1[ = value2] "]" ... "[" nameN[ = valueN] "]"
pseudoClasses = pseudoClass *pseudoClass
pseudoClass = ":" pseudoName [ "(" pseudoArgs ")" ]
tagName— name of the element in lower case, for example,divorscript.domains— domain restriction for the rule. Same principles as in element hiding rule syntax.attributes— a list of attributes that limit the selection of elements.name— required, attribute name;value— optional (may not be specified), substring that is contained in attribute value.pseudoName— the name of a pseudo-class.pseudoArgs— the arguments of a function-style pseudo-class.combinator— an operator that works similarly to the CSS child combinator: that is, theselectoron the right of thecombinatorwill only match an element whose direct parent matches theselectoron the left of thecombinator.
Syntax supported by AdGuard Browser Extension v5.3 or later:
rule = [domains] "$$" selector
domains = [domain0, domain1[, ...[, domainN]]]
selector— CSS selector, defines the element(s) to be removed from the HTML code before the page is loaded.domains— domain restriction for the rule. Same principles as in element hiding rule syntax.
The following limitations apply to AdGuard Browser Extension v5.3 and later:
- Pseudo-elements (e.g.,
::before,::after) are not supported, as they are not applicable in the context of HTML filtering.
Examples
HTML code:
<script data-src="/banner.js"></script>
Rule:
example.org$$script[data-src="banner"]
This rule removes all script elements with the attribute data-src containing the substring banner. The rule applies only to example.org and all its subdomains.
If the value of the attribute is omitted in the rule, then the element will be removed if it contains the specified attribute, regardless of its value. This is also the way to remove the elements whose attributes don't have any value at all.
<div some_attribute="some_value"></div>
<div some_attribute></div>
example.org$$div[some_attribute]
This rule removes all div elements with the attribute some_attribute on example.org and all its subdomains. So, the both div elements from the example above will be removed.
Special attributes
In addition to checking standard HTML attributes, you can filter elements based on their inner text or script content.
:contains()
The recommended way to filter elements by their content is using the :contains() pseudo-class. It allows you to target elements based on the actual text or script variables they contain, supporting both plain text strings and regular expressions.
Examples:
example.com$$div:contains("Sponsored by")
example.com$$script:contains(/ad_system_\d+/)
The first rule removes any <script> tag containing the word Adverts. The second targets any <div> containing the phrase Sponsored by. The third rule utilizes a regular expression to match dynamic script patterns.
The attributes listed below are legacy features kept only for backward compatibility. They may become unsupported in future updates. Prefer using the :contains() pseudo-class where it is available.
tag-content
This is the most frequently used special attribute. It limits selection with those elements whose innerHTML code contains the specified substring.
You must use "" to escape ", for instance: $$script[tag-content="alert(""this is ad"")"]
For example, take a look at this HTML code:
<script type="text/javascript">
document.write('<div>banner text</div>" />');
</script>
Following rule will delete all script elements with a banner substring in their code:
$$script[tag-content="banner"]
The tag-content special attribute must not appear in a selector to the left of a > combinator.
This limitation does not apply to AdGuard Browser Extension v5.3 or later.
wildcard
This special attribute works almost like tag-content and allows you to check the innerHTML code of the document. Rule will check if HTML code of the element fits the search pattern.
You must use "" to escape ", for instance: $$script[wildcard=""banner""]
For example: $$script[wildcard="*banner*text*"]
It checks if the element code contains the two consecutive substrings banner and text.
The wildcard special attribute must not appear in a selector to the left of a > combinator.
This limitation does not apply to AdGuard Browser Extension v5.3 or later.
max-length
Specifies the maximum length for content of HTML element. If this parameter is set and the content length exceeds the value, a rule does not apply to the element.
Default value
If this parameter is not specified, the max-length is considered to be 8192.
For example:
$$div[tag-content="banner"][max-length="400"]
This rule will remove all the div elements, whose code contains the substring banner and the length of which does not exceed 400 characters.
The max-length special attribute must not appear in a selector to the left of a > combinator.
This limitation does not apply to AdGuard Browser Extension v5.3 or later.
min-length
Specifies the minimum length for content of HTML element. If this parameter is set and the content length is less than preset value, a rule does not apply to the element.
For example:
$$div[tag-content="banner"][min-length="400"]
This rule will remove all the div elements, whose code contains the substring banner and the length of which exceeds 400 characters.
The min-length special attribute must not appear in a selector to the left of a > combinator.
This limitation does not apply to AdGuard Browser Extension v5.3 or later.
Pseudo-classes
:contains()
Syntax
:contains(unquoted text)
o
:contains(/reg(ular )?ex(pression)?/)
:-abp-contains() and :has-text() are synonyms for :contains().
The :contains() pseudo-class is supported by AdGuard for Windows, AdGuard for Mac, AdGuard for Android, AdGuard for Linux with CoreLibs v1.13 or later, and AdGuard Browser Extension v5.3 or later.
Requires that the inner HTML of the element contains the specified text or matches the specified regular expression.
A :contains() pseudo-class must not appear in a selector to the left of a > combinator.
This limitation does not apply to AdGuard Browser Extension v5.3 or later.
Exceptions
Similar to hiding rules, there is a special type of rules that disable the selected HTML filtering rule for particular domains. The syntax is the same, you just have to change $$ to $@$.
For example, there is a rule in filter:
$$script[tag-content="banner"]
If you want to disable it for example.com, you can create an exception rule:
example.com$@$script[tag-content="banner"]
Sometimes, it may be necessary to disable all restriction rules. For example, to conduct tests. To do this, use the exclusion rule without specifying a domain.
$@$script[tag-content="banner"]
We recommend to use this kind of exceptions only if it is not possible to change the hiding rule itself. In other cases it is better to change the original rule, using domain restrictions.
JavaScript rules
AdGuard supports a special type of rules that allows you to inject any JavaScript code to websites pages.
We strongly recommend using scriptlets instead of JavaScript rules whenever possible. JS rules are supposed to help with debugging, but as a long-time solution a scriptlet rule should be used.
Syntax
rule = [domains] "#%#" script
domains— domain restriction for the rule. Same principles as in element hiding rules.script— arbitrary JavaScript code in one string.
Examples
example.org#%#window.__gaq = undefined;executes the codewindow.__gaq = undefined;on all pages atexample.organd all subdomains.
Exceptions
Similar to hiding rules, there is a special type of rules that disable the selected JavaScript rule for particular domains. The syntax is the same, you just have to change #%# to #@%#.
For example, there is a rule in filter:
#%#window.__gaq = undefined;
If you want to disable it for example.com, you can create an exception rule:
example.com#@%#window.__gaq = undefined;
Sometimes, it may be necessary to disable all restriction rules. For example, to conduct tests. To do this, use the exclusion rule without specifying a domain.
#@%#window.__gaq = undefined;
We recommend to use this kind of exceptions only if it is not possible to change the hiding rule itself. In other cases it is better to change the original rule, using domain restrictions.
JavaScript rules can only be used in trusted filters.
JavaScript rules are not supported by AdGuard Content Blocker.
Scriptlet rules
Scriptlet is a JavaScript function that provides extended capabilities for content blocking. These functions can be used in a declarative manner in AdGuard filtering rules.
AdGuard supports a lot of different scriptlets. In order to achieve cross-blocker compatibility, we also support syntax of uBO and ABP.
Blocking rules syntax
[domains]#%#//scriptlet(name[, arguments])
domains— optional, a list of domains where the rule should be applied;name— required, a name of the scriptlet from the AdGuard Scriptlets library;arguments— optional, a list ofstringarguments (no other types of arguments are supported).
Examples
-
Apply the
abort-on-property-readscriptlet on all pages ofexample.organd its subdomains, and pass it analertargument:example.org#%#//scriptlet('abort-on-property-read', 'alert') -
Remove the
brandingclass from alldiv[class^="inner"]elements on all pages ofexample.organd its subdomains:example.org#%#//scriptlet('remove-class', 'branding', 'div[class^="inner"]')
Exception rules syntax
Exception rules can disable some scriptlets on particular domains. The syntax for exception scriptlet rules is similar to normal scriptlet rules but uses #@%# instead of #%#:
[domains]#@%#//scriptlet([name[, arguments]])
domains— optional, a list of domains where the rule should be applied;name— optional, a name of the scriptlet to except from the applying; if not set, all scriptlets will not be applied;arguments— optional, a list ofstringarguments to match the same blocking rule and disable it.
Examples
-
Disable specific scriptlet rule so that only
abort-on-property-readis applied only onexample.organd its subdomains:example.org,example.com#%#//scriptlet("abort-on-property-read", "alert")example.com#@%#//scriptlet("abort-on-property-read", "alert") -
Disable all
abort-on-property-readscriptlets forexample.comand its subdomains:example.org,example.com#%#//scriptlet("abort-on-property-read", "alert")example.com#@%#//scriptlet("abort-on-property-read") -
Disable all scriptlets for
example.comand its subdomains:example.org,example.com#%#//scriptlet("abort-on-property-read", "alert")example.com#@%#//scriptlet() -
Apply
set-constantandset-cookieto any web page, but due to special scriptlet exception rule only theset-constantscriptlet will be applied onexample.organd its subdomains:#%#//scriptlet('set-constant', 'adList', 'emptyArr')#%#//scriptlet('set-cookie', 'accepted', 'true')example.org#@%#//scriptlet('set-cookie') -
Apply
adjust-setIntervalto any web page andset-local-storage-itemonexample.comand its subdomains, but there are also multiple scriptlet exception rules, so no scriptlet rules will be applied onexample.comand its subdomains:#%#//scriptlet('adjust-setInterval', 'count', '*', '0.001')example.com#%#//scriptlet('set-local-storage-item', 'ALLOW_COOKIES', 'false')example.com#@%#//scriptlet()
Learn more about how to debug scriptlets.
More information about scriptlets can be found on GitHub.
Scriptlets rules can only be used in trusted filters.
Scriptlet rules are not supported by AdGuard Content Blocker.
The full syntax of scriptlet exception rules is supported by AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for Linux with CoreLibs v1.16 or later, and AdGuard Browser Extension for Chrome, Firefox, and Edge with TSUrlFilter v3.0 or later. Previous versions only support exception rules that disable specific scriptlets.
Trusted scriptlets
Trusted scriptlets are scriptlets with extended functionality. It means the same syntax and restrictions. Trusted scriptlet names are prefixed with trusted-, e.g. trusted-set-cookie, to be easily distinguished from common scriptlets.
Trusted scriptlets are not compatible with other ad blockers except AdGuard.
Trusted scriptlets rules can only be used in trusted filters.
Trusted scriptlets rules are not supported by AdGuard Content Blocker.
Learn more about how to debug scriptlets.
More information about trusted scriptlets can be found on GitHub.
Modifiers for non-basic type of rules
Each rule can be modified using the modifiers described in the following paragraphs.
Syntax
rule = "[$" modifiers "]" [rule text]
modifiers = modifier0[, modifier1[, ...[, modifierN]]]
modifier— set of the modifiers described below.rule text— a rule to be modified.
For example, [$domain=example.com,app=test_app]##selector.
In the modifiers values, the following characters must be escaped: [, ], ,, and \ (unless it is used for the escaping). Use \ to escape them. For example, an escaped bracket looks like this: \].
| Modifier \ Products | CoreLibs apps | AdGuard para Chromium | AdGuard para Chrome MV3 | AdGuard para Firefox | AdGuard para iOS | AdGuard para Safari | Bloqueador de contenido AdGuard |
|---|---|---|---|---|---|---|---|
| $app | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
| $domain | ✅ | ✅ | ✅ *[1] | ✅ | ✅ | ✅ | ❌ |
| $path | ✅ | ✅ *[2] | ❌ | ✅ *[2] | ✅ | ✅ | ❌ |
| $url | ✅ | ✅ *[3] | ✅ *[3] | ✅ *[3] | ❌ | ❌ | ❌ |
- ✅ — totalmente compatible
- ✅ * — compatible, pero la confiabilidad puede variar o pueden ocurrir limitaciones; verifica la descripción del modificador para más detalles
- ❌ — not supported
$app
$app modifier lets you narrow the rule coverage down to a specific application or a list of applications. The modifier's behavior and syntax perfectly match the corresponding basic rules $app modifier.
Examples
[$app=org.example.app]example.com##.textadhides adivwith the classtextadatexample.comand all subdomains in requests sent from theorg.example.appAndroid app.[$app=~org.example.app1|~org.example.app2]example.com##.textadhides adivwith the classtextadatexample.comand all subdomains in requests sent from any app exceptorg.example.app1andorg.example.app2.[$app=com.apple.Safari]example.org#%#//scriptlet('prevent-setInterval', 'check', '!300')applies scriptletprevent-setIntervalonly in Safari browser on Mac.[$app=org.example.app]#@#.textaddisables all##.textadrules for all domains while usingorg.example.app.
Such rules with $app modifier are supported by AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for Linux.
$domain
$domain modifier limits the rule application area to a list of domains and their subdomains. The modifier's behavior and syntax perfectly match the corresponding basic rules $domain modifier.
Examples
[$domain=example.com]##.textad— hides adivwith the classtextadatexample.comand all subdomains.[$domain=example.com|example.org]###adblock— hides an element with attributeidequalsadblockatexample.com,example.organd all subdomains.[$domain=~example.com]##.textad— this rule hidesdivelements of the classtextadfor all domains, exceptexample.comand its subdomains.
There are 2 ways to specify domain restrictions for non-basic rules:
- the "classic" way is to specify domains before rule mask and attributes:
example.com##.textad; - the modifier approach is to specify domains via
$domainmodifier:[$domain=example.com]##.textad.
But rules with mixed style domains restriction are considered invalid. So, for example, the rule [$domain=example.org]example.com##.textad will be ignored.
Non-basic $domain modifier limitations
Since the non-basic $domain works the same as the basic one, it has the same limitations.
Such rules with $domain modifier are supported by AdGuard for Windows, AdGuard for Mac, AdGuard for Android, AdGuard Browser Extension for Chrome, Chrome MV3, Firefox, and Edge.
$path
$path modifier limits the rule application area to specific locations or pages on websites.
Syntax
$path ["=" pattern]
pattern — optional, a path mask to which the rule is restricted. Its syntax and behavior are pretty much the same as with the pattern for basic rules. You can also use special characters, except for ||, which does not make any sense in this case (see examples below).
If pattern is not set for $path, rule will apply only on the main page of website.
$path modifier matches the query string as well.
$path modifier supports regular expressions in the same way basic rules do.
Examples
[$path=page.html]##.textadhides adivwith the classtextadat/page.htmlor/page.html?<query>or/sub/page.htmlor/another_page.html[$path=/page.html]##.textadhides adivwith the classtextadat/page.htmlor/page.html?<query>or/sub/page.htmlof any domain but not at/another_page.html[$path=|/page.html]##.textadhides adivwith the classtextadat/page.htmlor/page.html?<query>of any domain but not at/sub/page.html[$path=/page.html|]##.textadhides adivwith the classtextadat/page.htmlor/sub/page.htmlof any domain but not at/page.html?<query>[$path=/page*.html]example.com##.textadhides adivwith the classtextadat/page1.htmlor/page2.htmlor any other path matching/page<...>.htmlofexample.com[$path]example.com##.textadhides adivwith the classtextadat the main page ofexample.com[$domain=example.com,path=/page.html]##.textadhides adivwith the classtextadatpage.htmlofexample.comand all subdomains but not atanother_page.html[$path=/\\/(sub1|sub2)\\/page\\.html/]##.textadhides adivwith the classtextadat both/sub1/page.htmland/sub2/page.htmlof any domain (please note the escaped special characters)
Path-in-domain syntax
For cosmetic rules, you can use a simplified path-in-domain syntax by specifying the path directly in the domain part of the rule instead of using the $path modifier.
Syntax
rule = [targets] "##" selector
targets = [target0, target1[, ...[, targetN]]]
target = domain [path]
Examples:
example.org/checkout##.promo-banner— hides.promo-bannerelements only on checkout pagesnews.site.com/article##.sidebar-ad— hides sidebar ads only on article pagesdomain1.com,example.org/path##.banner— applies to all pages ondomain1.comand only/pathpages onexample.org/example\.org\/article\d+/##.ad— hides ads on article pages with numeric IDs
Path-in-domain syntax works with all types of cosmetic rules (##, #@#, #$#, $$, $@$, #%#, #@%#)
Path-in-domain syntax has been introduced in CoreLibs v1.20, Browser extension v5.4.
$path modifier limitations
In AdGuard Browser Extension, the non-basic $path modifier is compatible with other non-basic modifiers only when it is placed last, e.g., [$domain=/example.(com|org)/,path=/foo]##.ad. Otherwise, it may not work as expected.
Rules with $path modifier are not supported by AdGuard Content Blocker.
$url
$url modifier limits the rule application area to URLs matching the specified mask.
Syntax
url = pattern
where pattern is pretty much the same as pattern of the basic rules assuming that some characters must be escaped. The special characters and regular expressions are supported as well.
Examples
[$url=||example.com/content/*]##div.textadhides adivwith the classtextadat addresses likehttps://example.com/content/article.htmland evenhttps://subdomain.example.com/content/article.html.[$url=||example.org^]###adblockhides an element with attributeidequal toadblockatexample.organd its subdomains.[$url=/\[a-z\]+\\.example\\.com^/]##.textadhidesdivelements of the classtextadfor all domains matching the regular expression[a-z]+\.example\.com^.
$url modifier limitations
Rules with the $url modifier are supported by AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for Linux with CoreLibs v1.11 or later, and AdGuard Browser Extension with TSUrlFilter v3.0.0 or later.
Information for filter maintainers
If you maintain a third-party filter that is known to AdGuard, you might be interested in the information presented in this section. Please note that hints will be applied to registered filters only. The filter is considered to be registered and known by AdGuard, if it is present in the known filters index. If you want your filter to be registered, please file an issue to AdguardFilters repo.
Preprocessor directives
We provide preprocessor directives that can be used by filter maintainers to improve compatibility with different ad blockers and provide:
- including a file
- applying rules conditionally by ad blocker type
- content blocker specifying for rules applying in Safari
Any mistake in a preprocessor directive will lead to AdGuard failing the filter update in the same way as if the filter URL was unavailable.
Preprocessor directives can be used in the user rules or in the custom filters.
Including a file
The !#include directive allows to include contents of a specified file into the filter. It supports only files from the same origin to make sure that the filter maintainer is in control of the specified file. The included file can also contain pre-directives (even other !#include directives). Ad blockers should consider the case of recursive !#include and implement a protection mechanism.
Syntax
!#include file_path
where file_path is a same origin absolute or relative file path to be included.
The files must originate from the same domain, but may be located in a different folder.
If included file is not found or unavailable, the whole filter update should fail.
Same-origin limitation should be disabled for local custom filters.
Examples
Filter URL: https://example.org/path/filter.txt
! Valid (same origin):
!#include https://example.org/path/includedfile.txt
!
! Valid (relative path):
!#include /includedfile.txt
!#include ../path2/includedfile.txt
!
! Invalid (another origin):
!#include https://domain.com/path/includedfile.txt
Conditions
Filter maintainers can use conditions to supply different rules depending on the ad blocker type. A conditional directive beginning with an !#if directive must explicitly be terminated with an !#endif directive. Conditions support all basic logical operators.
There are two possible scenarios:
-
When an ad blocker encounters an
!#ifdirective and no!#elsedirective, it will compile the code between!#ifand!#endifdirectives only if the specified condition is true. -
If there is an
!#elsedirective, the code between!#ifand!#elsewill be compiled if the condition is true; otherwise, the code between!#elseand!#endifwill be compiled.
Whitespaces matter. !#if is a valid directive, while !# if is not.
Syntax
!#if (conditions)
rules_list
!#endif
o
!#if (conditions)
true_conditions_rules_list
!#else
false_conditions_rules_list
!#endif
where:
!#if (conditions)— start of the block when conditions are trueconditions— just like in some popular programming languages, preprocessor conditions are based on constants declared by ad blockers. Authors of ad blockers define on their own what exact constants they declare. Possible values:adguardalways declared; shows maintainers that this is one of AdGuard products; should be enough in 95% of cases- product-specific constants for cases when you need a rule to work (or not work — then
!should be used before constant) in a specific product only:adguard_app_windows— AdGuard for Windowsadguard_app_mac— AdGuard for Macadguard_app_cli— AdGuard for Linuxadguard_app_android— AdGuard for Androidadguard_app_ios— AdGuard for iOSadguard_ext_safari— AdGuard for Safariadguard_ext_chromium— AdGuard Browser Extension for Chrome (and chromium-based browsers, e.g. new Microsoft Edge)adguard_ext_chromium_mv3— AdGuard for Chrome MV3adguard_ext_firefox— AdGuard Browser Extension for Firefoxadguard_ext_edge— AdGuard Browser Extension for Edge Legacyadguard_ext_opera— AdGuard Browser Extension for Operaadguard_ext_android_cb— AdGuard Content Blocker for mobile Samsung and Yandex browsersext_ublock— special case; this one is declared when a uBlock version of a filter is compiled by the FiltersRegistrycap_html_filtering— products that support HTML filtering rules: AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for Linux
!#else— start of the block when conditions are falserules_list,true_conditions_rules_list,false_conditions_rules_list— lists of rules!#endif— end of the block
Examples
! for all AdGuard products except AdGuard for Safari
!#if (adguard && !adguard_ext_safari)
||example.org^$third-party
domain.com##div.ad
!#endif
! directives even can be combined
!#if (adguard_app_android)
!#include /androidspecific.txt
!#endif
!#if (adguard && !adguard_ext_safari)
! for all AdGuard products except AdGuard for Safari
||example.org^$third-party
domain.com##div.ad
!#else
! for AdGuard for Safari only
||subdomain.example.org^$third-party
!#endif
The !#else directive is supported by the FiltersDownloader v1.1.20 or later.
It is already supported for filter lists compiled by the FiltersRegistry, but it still may not be supported by AdGuard products when adding a filter list with !#else as a custom one. The following products will support it in the mentioned versions or later:
- AdGuard for Windows, Mac, and Android with CoreLibs v1.13;
- AdGuard Browser Extension v4.2.208;
- AdGuard for Safari v1.11.16.
Safari affinity
Safari's limit for each content blocker is 150,000 active rules. But in AdGuard for Safari and AdGuard for iOS, we've split the rules into 6 content blockers, thus increasing the rule limit to 900,000.
Here is the composition of each content blocker:
- AdGuard General — Ad Blocking, Language-specific
- AdGuard Privacy — Privacy
- AdGuard Social — Social Widgets, Annoyances
- AdGuard Security — Security
- AdGuard Other — Other
- AdGuard Custom — Custom
User rules and allowlist are added to every content blocker.
The main disadvantage of using multiple content blockers is that rules from different blockers are applied independently. Blocking rules are not affected by this, but unblocking rules may cause problems. If a blocking rule is in one content blocker and an exception is in another, the exception will not work. Filter maintainers use !#safari_cb_affinity to define Safari content blocker affinity for the rules inside of the directive block.
Syntax
!#safari_cb_affinity(content_blockers)
rules_list
!#safari_cb_affinity
where:
!#safari_cb_affinity(content_blockers)— start of the blockcontent_blockers— comma-separated list of content blockers. Possible values:general— AdGuard General content blockerprivacy— AdGuard Privacy content blockersocial— AdGuard Social content blockersecurity— AdGuard Security content blockerother— AdGuard Other content blockercustom— AdGuard Custom content blockerall— special keyword that means that the rules must be included into all content blockers
rules_list— list of rules!#safari_cb_affinity— end of the block
Examples
! to unhide specific element which is hidden by AdGuard Base filter:
!#safari_cb_affinity(general)
example.org#@#.adBanner
!#safari_cb_affinity
! to allowlist basic rule from AdGuard Tracking Protection filter:
!#safari_cb_affinity(privacy)
@@||example.org^
!#safari_cb_affinity
Hints
"Hint" is a special comment, instruction to the filters compiler used on the server side (see FiltersRegistry).
Syntax
!+ HINT_NAME1(PARAMS) HINT_NAME2(PARAMS)
Multiple hints can be applied.
NOT_OPTIMIZED hint
For each filter, AdGuard compiles two versions: full and optimized. Optimized version is much more lightweight and does not contain rules which are not used at all or used rarely.
Rules usage frequency comes from the collected filter rules statistics. But filters optimization is based on more than that — some filters have specific configuration. This is how it looks like for Base filter:
"filter": AdGuard Base filter,
"percent": 30,
"minPercent": 20,
"maxPercent": 40,
"strict": true
where:
- filter — filter identifier
- percent — expected optimization percent
~= (rules count in optimized filter) / (rules count in original filter) * 100 - minPercent — lower bound of
percentvalue - maxPercent — upper bound of
percentvalue - strict — if
percent < minPercentORpercent > maxPercentand strict mode is on then filter compilation should fail, otherwise original rules must be used
In other words, percent is the "compression level". For instance, for the Base filter it is configured to 40%. It means that optimization algorithm should strip 60% of rules.
Eventually, here are the two versions of the Base filter for AdGuard Browser Extension:
- full: https://filters.adtidy.org/extension/chromium/filters/2.txt
- optimized: https://filters.adtidy.org/extension/chromium/filters/2_optimized.txt
If you want to add a rule which should not be removed at optimization use the NOT_OPTIMIZED hint:
!+ NOT_OPTIMIZED
||example.org^
And this rule will not be optimized only for AdGuard for Android:
!+ NOT_OPTIMIZED PLATFORM(android)
||example.org^
PLATFORM and NOT_PLATFORM hints
Used to specify the platforms to apply the rules. List of existing platforms and links to Base filter, for example, for each of them:
-
windows— AdGuard for Windows — https://filters.adtidy.org/windows/filters/2.txt -
mac— AdGuard for Mac — https://filters.adtidy.org/mac_v3/filters/2.txt -
cli— AdGuard for Linux — https://filters.adtidy.org/cli/filters/2.txt -
android— AdGuard for Android — https://filters.adtidy.org/android/filters/2_optimized.txt -
ios— AdGuard for iOS — https://filters.adtidy.org/ios/filters/2_optimized.txt -
ext_chromium— AdGuard Browser Extension for Chrome — https://filters.adtidy.org/extension/chromium/filters/2.txt -
ext_chromium_mv3— AdGuard Browser Extension for Chrome MV3 — https://filters.adtidy.org/extension/chromium-mv3/filters/2.txt -
ext_ff— AdGuard Browser Extension for Firefox — https://filters.adtidy.org/extension/firefox/filters/2.txt -
ext_edge— AdGuard Browser Extension for Edge — https://filters.adtidy.org/extension/edge/filters/2.txt -
ext_opera— AdGuard Browser Extension for Opera — https://filters.adtidy.org/extension/opera/filters/2.txt -
ext_safari— AdGuard for Safari — https://filters.adtidy.org/extension/safari/filters/2_optimized.txt -
ext_android_cb— AdGuard Content Blocker — https://filters.adtidy.org/extension/android-content-blocker/filters/2_optimized.txt -
ext_ublock— uBlock Origin — https://filters.adtidy.org/extension/ublock/filters/2.txt
Examples
This rule will be available only in AdGuard for Windows, Mac, Android:
!+ PLATFORM(windows,mac,android)
||example.org^
Except for AdGuard for Safari, AdGuard Content Blocker, and AdGuard for iOS, this rule is available on all platforms:
!+ NOT_PLATFORM(ext_safari, ext_android_cb, ios)
||example.org^
NOT_VALIDATE
This hint is used to skip validation of the rule. It is useful for rules for which support has not yet been added to the filters compiler, or for rules that are incorrectly discarded.
If you want to add a rule that should not be validated, use the NOT_VALIDATE hint:
!+ NOT_VALIDATE
||example.org^$newmodifier
How to debug filtering rules
It may be possible to create simple filtering rules "in your head" but for anything even slightly more complicated you will need additional tools to debug and iterate them. There are tools to assist you with that. You can use DevTools in Chrome and its analogs in other browsers but most AdGuard products provide another one — Filtering log.
Filtering log
Filtering log is an advanced tool that will be helpful mostly to filter developers. It lists all web requests that pass through AdGuard, gives you exhaustive information on each of them, offers multiple sorting options, and has other useful features.
Depending on which AdGuard product you are using, Filtering log can be located in different places.
- In AdGuard for Windows, you can find it in the Ad Blocker tab or via the tray menu
- In AdGuard for Mac, it is located in Settings → Advanced → Filtering log
- In AdGuard for Android, you can find it under Statistics → Recent activity. Recent activity can also be accessed from the Assistant
- In AdGuard Browser Extension, it is accessible from the Miscellaneous settings tab or by right-clicking the extension icon. Only Chromium- and Firefox-based web browsers show applied element hiding rules (including CSS, ExtCSS) and JS rules and scriptlets in their Filtering logs
In AdGuard for iOS and AdGuard for Safari, Filtering log does not exist because of the way content blockers are implemented in Safari. AdGuard does not see the web requests and therefore cannot display them.
Selectors debugging mode
Sometimes, you might need to check the performance of a given selector or a stylesheet. In order to do it without interacting with JavaScript directly, you can use a special debug style property. When ExtendedCss meets this property, it enables the debugging mode either for a single selector or for all selectors, depending on the debug value.
Open the browser console while on a web page to see the timing statistics for selector(s) that were applied there. Debugging mode displays the following stats as object where each of the debugged selectors are keys, and value is an object with such properties:
Always printed:
selectorParsed— text of the parsed selector, may differ from the input onetimings— list of DOM nodes matched by the selectorappliesCount— total number of times that the selector has been applied on the pageappliesTimings— time that it took to apply the selector on the page, for each of the instances that it has been applied (in milliseconds)meanTiming— mean time that it took to apply the selector on the pagestandardDeviation— standard deviationtimingsSum— total time it took to apply the selector on the page across all instances
Printed only for remove pseudos:
removed— flag to signal if elements were removed
Printed if elements are not removed:
matchedElements— list of DOM nodes matched by the selectorstyleApplied— parsed rule style declaration related to the selector
Examples
Debugging a single selector:
When the value of the debug property is true, only information about this selector will be shown in the browser console.
#$?#.banner { display: none; debug: true; }
Enabling global debug:
When the value of the debug property is global, the console will display information about all extended CSS selectors that have matches on the current page, for all the rules from any of the enabled filters.
#$?#.banner { display: none; debug: global; }
Testing extended selectors without AdGuard
ExtendedCss can be executed on any page without using any AdGuard product. In order to do that you should copy and execute the following code in a browser console:
!function(e,t,d){C=e.createElement(t),C.src=d,C.onload=function(){alert("ExtendedCss loaded successfully")},s=e.getElementsByTagName(t)[0],s?s.parentNode.insertBefore(C,s):(h=e.getElementsByTagName("head")[0],h.appendChild(C))}(document,"script","https://AdguardTeam.github.io/ExtendedCss/extended-css.min.js");
Alternatively, install the ExtendedCssDebugger userscript.
Now you can now use the ExtendedCss from global scope, and run its method query() as Document.querySelectorAll().
Examples
const selector = 'div.block:has=(.header:matches-css(after, content: Ads))';
// array of HTMLElements matched the `selector` is to be returned
ExtendedCss.query(selector);
Debugging scriptlets
If you are using AdGuard Browser Extension and want to debug a scriptlet or a trusted scriptlet rule, you can get additional information by opening the Filtering log. In that case, scriptlets will switch to debug mode and there will be more information in the browser console.
The following scriptlets are especially developed for debug purposes:
debug-current-inline-scriptdebug-on-property-readdebug-on-property-writelog-addEventListenerlog-on-stack-tracelog-evallog
The following scriptlets also may be used for debug purposes:
json-pruneprevent-fetchprevent-requestAnimationFrameprevent-setIntervalprevent-setTimeoutprevent-window-openwith specifiedreplacementparameterprevent-xhrtrusted-replace-fetch-responsetrusted-replace-xhr-response
Compatibility tables legend
Product shortcuts
CoreLibs apps— AdGuard for Windows, AdGuard for Mac, AdGuard for Android, and AdGuard for LinuxAdGuard for Chromium— AdGuard Browser Extension for Chrome and other Chromium-based browsers such as Microsoft Edge and OperaAdGuard for Chrome MV3— AdGuard Browser Extension for Chrome MV3AdGuard for Firefox— AdGuard Browser Extension for FirefoxAdGuard for iOS— AdGuard for iOS and AdGuard Pro for iOS (for mobile Safari browser)AdGuard for Safari— AdGuard for desktop Safari browserAdGuard Content Blocker— Content Blocker for Android mobile browsers: Samsung Internet and Yandex Browser
Compatibility shortcuts
- ✅ — totalmente compatible
- ✅ * — compatible, pero la confiabilidad puede variar o pueden ocurrir limitaciones; verifica la descripción del modificador para más detalles
- 🧩 — may already be implemented in nightly or beta versions but is not yet supported in release versions
- ⏳ — feature that is planned to be implemented but is not yet available in any product
- ❌ — not supported
- 👎 — deprecated; still supported but will be removed in the future
- 🚫 — removed and no longer supported