AdGuard сделает «песочницу конфиденциальности» Google по-настоящему конфиденциальной. Всё о Google Privacy Sandbox
- Privacy Sandbox — это набор технологий, предложенных Google, чтобы помирить рекламу с заботой о конфиденциальности пользователя.
- Концепция «песочницы конфиденциальности» терпит фиаско из-за одного неисправного элемента — Google Topics.
- Topics не помешают техгигантам собирать огромное количество пользовательских данных.
- Topics могут затруднить идентификацию пользователей для одного веб-сайта в вакууме, но корпорациям это не составит труда.
- Topics упрочат рекламную монополию Google.
- Topics — это «одна паршивая овца, которая портит всё стадо», поэтому AdGuard будет их блокировать.
Google объявила о старте глобального тестирования своей инициативы в области защиты пользовательских данных Privacy Sandbox в Chrome и на Android. Пришло время и нам высказать своё отношение к ней. Не углубляясь в детали (вы можете подробно ознакомиться со всеми технологиями Privacy Sandbox ниже), скажем сразу, что одна из них, а именно Google Topics, вызывает у нас наибольшие опасения.
Мы считаем, что Topics представляет собой далёкий от совершенства механизм, который, вопреки заявленной цели, не предотвратит массовый сбор данных о пользователях. Более того, он позволит Google упрочить своё лидирующее положение на рынке таргетированной рекламы. Исходя из этого, AdGuard будет блокировать Topics API.
Если вкратце, то в основе Topics лежит идея не допустить создания цифрового отпечатка пользователя. Рекламодатели будут иметь доступ к интересам пользователей, но они им будут предоставлены в таком виде, что идентификация станет невозможной. В теории. На практике же компании с большой долей вероятности как и прежде смогут вычислить отдельных пользователей.
Что касается инициативы Google в целом, то, блокируя Topics, мы избавимся от потенциальной уязвимости, и превратим Privacy Sandbox в действительно эффективный инструмент для повышения уровня конфиденциальности пользователей.
Google объявил о старте тестирования Privacy Sandbox в прошлом месяце, предоставив разработчикам возможность опробовать её ключевые технологии, в числе прочего Topics, которые должны заменить сторонние файлы cookies. На данный момент только «ограниченное число пользователей Chrome Beta» могут принимать участие в тестировании продукта. В список тестируемых механизмов входят уже упомянутые Topics, а также FLEDGE и Attribution Reporting.
В конце апреля Google также выпустил предварительную версию Privacy Sandbox для Android, и разработчики получили возможность протестировать SDK Runtime и Topics на Android. Версия «песочницы» для Android создана по образу и подобию Privacy Sandbox для Chrome с незначительными изменениями.
Предлагаем подробнее рассмотреть Privacy Sandbox для Chrome и Privacy Sandbox для Android, чтобы понять, чего разработчикам и простым пользователям стоит ждать от внедрения этого решения Google.
Privacy Sandboxes
Google Privacy Sandbox – это комплекс предложений для защиты пользовательских данных, который получил две реализации: Privacy Sandbox для web (для браузера Chrome) и Privacy Sandbox на Android (для использования на устройствах с ОС Android). Мы уже делали краткий обзор инициативы Google для Android. В данной статье мы рассмотрим оба предложения подробнее.
Privacy Sandbox для браузера
Инициатива представляет собой набор технологий, призванных повысить уровень конфиденциальности пользователей. Вот некоторые из них:
DNS-over-HTTPS(DoH). DNS часто сравнивают со списком контактов в телефоне. Мы ищем нужный контакт в телефоне по имени, а не по номеру. По такому же принципу работает DNS. Когда мы вводим в строку браузера Chrome (или любого другого браузера) доменное имя сайта, браузер на самом деле не понимает, куда ему нужно перейти. В сети не используются понятные человеку адреса, такие как google.com, facebook.com и т.д. При подключении к сайту ваш браузер сначала запрашивает IP адрес этого сайта у DNS сервера. Раньше весь этот процесс осуществлялся с использованием открытого протокола, и, несмотря на зашифрованный HTTPS-трафик и другие меры защиты данных, можно было узнать, какие сайты вы посещаете. Это означало, что вы теряли часть своей анонимности.
DoH исправляет это упущение. В рамках протокола запросы вашего браузера к серверу DNS и ответы на них передаются в зашифрованном виде.
Gnatcatcher — технология, которая скрывает ваш реальный IP-адрес. Она чем-то напоминает VPN, так как её главная цель — исключить возможность установить ваш реальный IP-адрес, а вместе с тем и ваше местонахождение.
Privacy Budget — набор мер по ограничению объёма данных, получаемых сайтом о вашей системе. Чем меньше о вас знает вебсайт, тем сложнее вас «вычислить» в толпе.
FLEDGE — специальный механизм таргетинга пользовательской аудитории локально на устройстве. Его можно использовать для показа рекламы. Например, когда вы кладёте товары в корзину в одном онлайн-магазине, выходите из него, а другое приложение показывает вам рекламу этого магазина с напоминанием о том, что вы не закончили оформление заказа. В настоящее время ретаргентиг рекламы основывается на «списках» аудиторий, которые загружают рекламодатели. Список может содержать, например, адрес электронной почты пользователя, а зачастую и другую идентификационную информацию. Рекламодатели делятся такими списками как друг с другом, так и с третьими лицами. После внедрения FLEDGE выбор рекламы для показа пользователю будет происходить внутри браузера, а следовательно, и устройства пользователя.
Пожалуй, самым спорным и одновременно интересным моментом в инициативе Privacy Sandbox является технология Google Topics.
Что такое Google Topics?
Google Topics — это новая технология Google, которая должна прийти на смену сторонним файлам cookie, и, как следствие, стать альтернативой перекрёстному таргетингу и фингерпринтингу (созданию уникального цифрового «отпечатка» пользователя). Но действительно ли она отвечает этой цели? Прежде чем ответить на этот вопрос, давайте посмотрим, как всё устроено сейчас.
Как всё устроено сейчас?
Сейчас при посещении сайта ваше устройство загружает небольшие текстовые файлы с сервера и хранит их локально. Эти файлы могут содержать сведения о состоянии аутентификации, статистике посещений, данные о личных предпочтениях и настройках пользователя, а также могут использоваться для отслеживания состояния сеанса. Данная технология получила название cookies. Если вы, например, перейдёте на сайт www.example.com, то ваше устройство загрузит cookies с этого сайта. При каждом вашем последующем посещении этого сайта файлы cookie будут отправляться обратно на сайт, позволяя ему идентифицировать вас. Cookies могут содержать фактически любую информацию, в том числе данные об операционной системе, типе и версии вашего браузера, данные о том, что вы искали в интернете и какими товарами интересовались. Надо отметить, что cookies также делают жизнь пользователя проще: благодаря cookies вам не приходится каждый раз вручную вводить логин или пароль на сайте для авторизации.
Теперь о том, что такое сторонние файлы cookies. Если сайт содержит рекламные баннеры или иные рекламные объявления, размещённые от лица другого доменного имени (например, ad.sirbuymepls.com), то вы получите файлы и от этого сайта тоже. Они и будут называться сторонними файлами cookies. Подытожим: сторонние файлы cookies отправляются третьей стороной, а не сайтом, на которым вы в данный момент находитесь.
Некоторые рекламодатели (на самом деле, многие) используют этот тип cookies для отслеживания взаимодействия пользователя с другими сайтами. Эта технология называется перекрёстным таргетингом. Помимо информации о вашем интересе к своим продуктам, рекламодатели могут попытаться выяснить и другую информацию о вас, например, ваш пол, этническую принадлежность, религиозные и политические взгляды для более точной настройки рекламы. Подобная практика периодически подвергается жёсткой критике. Само собой разумеется, собранная информация продаётся и покупается. Это является серьезным нарушением конфиденциальности пользователей, которое приводит к неправомерному использованию данных.
Эта проблема как-то решается?
Да, работа в этом направлении ведётся довольно давно. Сейчас многие браузеры, такие как Safari, Firefox, Brave, Tor имеют встроенную защиту от межсайтового отслеживания. Например, Apple Safari использует движок WebKit, в котором реализован механизм интеллектуальной защиты Intelligent Tracking Prevention (ITP). Brave хранит личные данные пользователей в изолированных (секционированных) хранилищах и удаляет их при закрытии вкладки браузера, тем самым не давая третьим лицам получить эти данные.
Помимо уже перечисленных компаний, свой браузер разрабатывает и популярный анонимный поисковик DuckDuckGo. Можно с уверенностью предположить, что DuckDuckGo потеснит другие браузеры на этом рынке.
К сожалению, пока что сложно оценить эффект от этих мер. К тому же, Google в своем браузере Chrome только планирует начать блокировать сторонние куки.
У Google свой собственный путь?
Определенно. В отличие от Apple, блокирующей сторонние куки в браузере Safari, Google предпочла бы и дальше разрешать таргетированную рекламу. Google является дочерней компанией Alphabet Inc, которая зарабатывает, как мы знаем, на рекламе. К тому же, Google Chrome является самым популярным браузером в мире. Таким образом, Alphabet Inc прямо заинтересована в сохранении рынка рекламы.
Однако для Meta, которая стремительно теряет прибыль, пользователей и капитализацию, благоразумнее было бы не противиться новой тенденции, а возглавить её.
Вероятно, открытое противодействие новым веяниям и поддержка текущего положения на рынке таргетированной рекламы ухудшили бы положение Google, поэтому компания вынуждена идти навстречу изменениям. Мы можем наблюдать попытку Google усидеть на двух стульях: с одной стороны, компания делает шаг в сторону защиты пользовательских данных, а с другой хочет сохранить свою выигрышную позицию на рынке рекламы.
Как мы уже отмечали ранее, Google Chrome занимает доминирующее положение на рынке веб-браузеров. Помимо этого, движок браузера Chromium используется во многих других браузерах, а значит, Google почти целиком контролирует развитие веб-стандартов. Например, технология Accelerated Mobile Pages (AMP), представленная Google в 2015 году, получила широкое распространение, несмотря на наличие подобных решений у конкурентов.
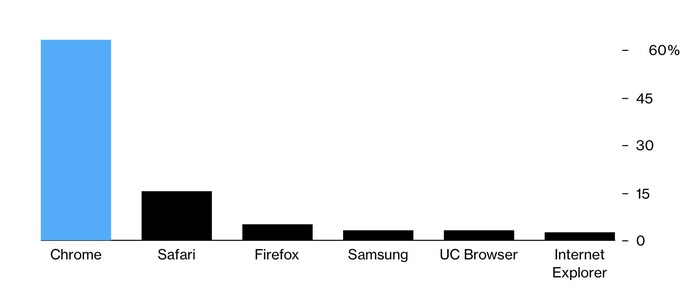
Наличие монополиста в области веб-технологий уже само по себе плохо, но ещё хуже, когда этот монополист получает львиную часть своих доходов от рекламы.
Первые робкие шаги Google в направлении отказа от файлов cookie были восприняты крайне негативно. Многие разработчики веб-браузеров отказались от использования технологии FLoC (Federated Learning of Cohorts), которая изначально должна была стать альтернативой cookies. Google провел «работу над ошибками», и миру была представлена новая технология — Google Topics.
Насколько хороши Google Topics?
Чтобы ответить на этот вопрос, нам нужно разобраться, как работает эта технология. По сути, Topics — это «темы», например, «Книги и литература» или «Компьютеры и электроника», которые Google будет определять исходя из того, чем вы интересовались за определенный период времени, например, за одну неделю.
Вот как это будет выглядеть: каждую неделю на устройстве пользователя с помощью специальной программы выбирается 5 самых популярных тем, к ним добавляется 6-я тема, выбранная случайно из полного списка тем. Сайту возвращается 1 из 6 тем за неделю. При этом сайт, на который вы заходите впервые, получает 3 темы, отобранные за 3 предыдущих недели.
Google сам определяет общее количество тем, доступных для рекламодателя. Сейчас это число составляет 350. Список тем будет размещаться в открытом доступе и редактироваться вручную.
Предполагается, что сайты не смогут собирать информацию сверх того, что позволяет технология. Предполагается также, что разным сайтам будут выдаваться разные темы, и, следовательно, они не смогут сопоставлять данные и идентифицировать вас.
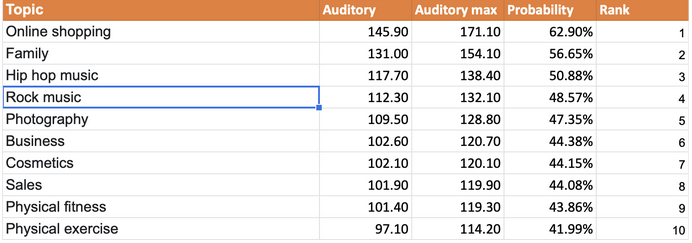
Однако это не совсем так. В результате поиска по открытым источникам мы получили данные из ресурса facebook.com по 272 миллиардам просмотрам рекламы аудиторией США. Следует сразу отметить, что в исследовании участвовало всего 260 тем, что меньше 350, предлагаемых Google. И тем более, гораздо меньше возможного количества когорт.
Итак, что мы получили? В таблице представлены наиболее популярные…
…и наименее популярные интересы.
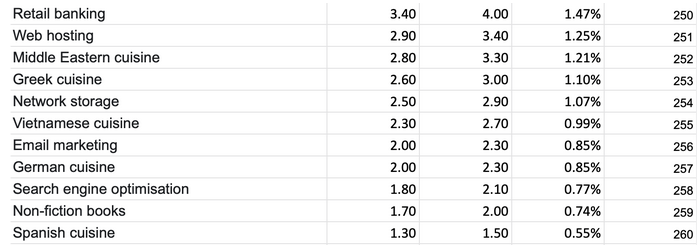
Столбцы отражают минимальное и максимальное покрытие по аудитории в миллионах человек, а также вероятность (probability) попадания человека в данный интерес. Все интересы проранжированы от наиболее до наименее популярных. В итоге мы получили следующее распределение:
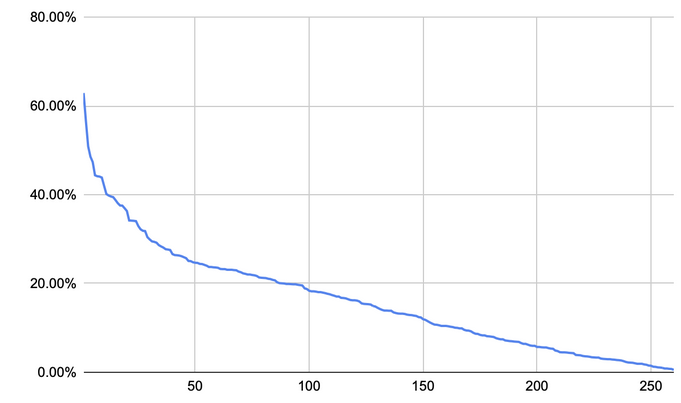
А затем получили следующие данные:
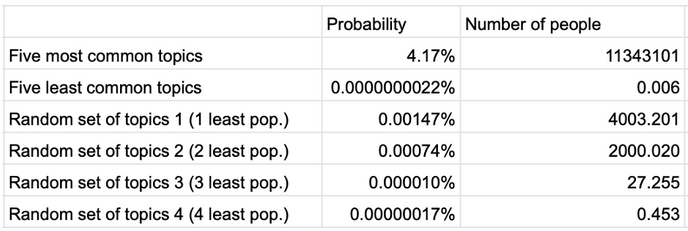
Вопреки утверждению Google, что использование большого количества «крупных» тем поделит пользователей на большое количество подгрупп, мы можем наблюдать обратное.
К тому же, согласно Google, 350 — это лишь примерное число тем, которое в будущем может составить несколько тысяч, упрощая задачу идентификации. Более того, если дополнить эти данные информацией о городе проживания пользователя, то можно будет с большой долей вероятности его вычислить.
Таким образом, утверждение Google, что сайтам не удастся идентифицировать пользователя, будет справедливо лишь для какого-то одного единственного сайта в вакууме. В реальности корпорации, которые владеют сразу несколькими сервисами, будут всё так же получать информацию о пользователе и, более того, смогут её коррелировать.
Самым очевидным примером является Meta, которая владеет Facebook, Instagram и WhatsApp. В данном случае мы имеем 3 чрезвычайно популярных сервиса, каждый из которых сможет получать по 1 теме в неделю, коррелируя полученные результаты между собой. А теперь представим, что информация будет накапливаться в течение нескольких месяцев. В этих условиях не составит труда отсечь дополнительные темы, выбранные случайным образом, и узнать все о предпочтениях пользователя.
Google сама по себе является хорошим примером. Наверняка вы пользуетесь каким-то из этих сервисов: смотрите YouTube, слушаете YouTube Music, используете Google Maps, Google Drive, Gmail — список можно продолжать. Догадываетесь, к чему мы ведём? С таким количеством сервисов Google сможет получать огромный массив данных почти о каждом пользователе. Не говоря о различных SDK (Software Development Kit, набор средств разработки ПО), которые собирают метрики и которые используются почти на каждом сайте. Кто является ведущим разработчиком этих SDK? Всё те же Google и Meta.
Google сумела убить двух зайцев сразу. Во-первых, компания осложнила сбор пользовательских данных для своих более мелких конкурентов. А во-вторых, она предоставила самой себе почти безграничные возможности в этой сфере. Учитывая, насколько широкое распространение получил браузер Chrome и браузеры на базе Chromium, всё это лишь укрепит позиции компании на рынке Adtech.
Google пытается представить новую технологию как безусловное благо, но мы теперь знаем, что тем самым она пытается упрочить свою монополию на рекламном рынке.
Android Privacy Sandbox
Аналогичная технология под названием Android Privacy Sandbox планируется для внедрения на Android. Если в предыдущем случае речь шла о сайтах, то теперь о приложениях и возможности отслеживать, какими приложениями пользуется владелец устройства. Посмотрим, что предлагает Google.
SDK Runtime
На сегодняшний день существует множество SDK, которые упрощают разработку программного обеспечения, а именно предлагают разработчикам фиксированный набор различных механизмов и/или утилит для использования в приложении. Таким образом обеспечивается переиспользуемость данных SDK в различных приложениях: разработчикам не нужно заново изобретать велосипед, вместо этого они используют готовое и проверенное временем решение. Это позволяет им сосредоточиться на функционале продукта и существенно сократить время его разработки, а следовательно, и его стоимость.
Проблема заключалась в том, что используемые SDK являлись частью приложения и выполнялись вместе с ним в одной «песочнице» (изолированном от основной системы и других приложений пространстве).
Схема с SDK несла в себе немалые риски. Если приложению давался доступ, например, к контактам, местоположению, звонкам, сообщениям и файловой системе пользователя, то данные разрешения наследовались и самим SDK. Так как SDK не всегда проверялись на незадекларированные возможности, компании-разработчики могли получить доступ к пользовательским данным. Разумеется, существовали недобросовестные вендоры, которые собирали пользовательские данные и продавали их с целью заработать.
Google утверждает, что SDK Runtime решит эту проблему. Если вкратце, то теперь зависимости в виде SDK будут выполняться в отдельной от приложения «песочнице» и не будут наследовать разрешения на доступ к пользовательским данным от приложения.
Более того, Google планирует реализовать доверенную модель распространения SDK. Если раньше разработчики скачивали SDK из сторонних источников, рискуя получить SDK с внедренным вредоносным кодом, то теперь разработчики смогут скачивать их из специального магазина. При этом, так как SDK уже не будет частью приложения, в приложении появятся специализированные интерфейсы данных SDK. Проще говоря, протоколы взаимодействия с данными SDK.
Загрузка SDK на устройство пользователя будет происходить из доверенного магазина SDK.
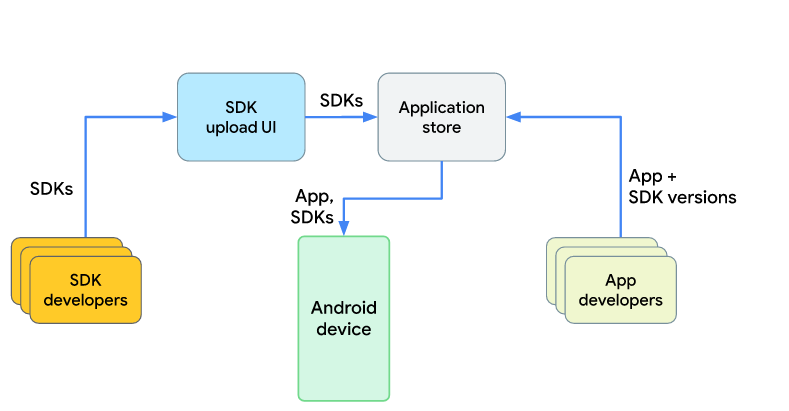
Таким образом уменьшится количество атак на цепочку поставок данных SDK. Мы надеемся, что в магазине SDK будет также реализована функция проверки по образу и подобию Google Play Store. Это станет ещё один шагом по борьбе с вирусами на устройствах на базе Android. К тому же, сторонние SDK теперь не смогут бесконтрольно собирать пользовательскую информацию.
Android Topics
Как по своему названию, так и по сути технология похожа на Google Topics для Chrome. Однако между ними существуют небольшие различия, на которых мы сейчас и остановимся.
Так как в данном случае технология разрабатывается для телефона, то отслеживаться будут не сайты, а мобильные приложения, с которыми взаимодействует пользователь.
В целом, схема не претерпела больших изменений. Аналогичным образом будут определяться 5 самых популярных тем, которые больше всего интересовали пользователя на неделе. Как и в версии для браузера, будет добавляться 6-я тема, выбранная случайным образом. В этом плане алгоритм полностью идентичен Topics для Chrome.
Тема приложения будет определяться исходя из его названия и описания.
Google утверждает, что так как разные приложения будут получать разные данные о вас, то они не смогут создать ваш «цифровой отпечаток».
Недостатки данного подхода мы уже рассматривали. Напомним: даже если эта технология и затруднит сбор данных для отдельное приложения, то у мегакорпораций и компаний с большим количеством приложений проблем не возникнет. Допустим, у вас на телефоне установлены Facebook, WhatsApp, Instagram и, возможно, Messenger. Все эти приложения смогут получать ваши темы — более того, они будут накапливать информацию о вас в течение продолжительного времени. Сможет ли Meta соотнести данные от этих приложений и понять, что речь идет об одном и том же человеке? При желании это не составит труда.
Мы уже упоминали сервисы Google. У каждого из них есть мобильные приложения: Youtube, Google Play, Youtube Music, Gmail, Google Drive, gPhoto. Представляете масштаб собираемой информации? А ведь есть ещё сама операционная система Android, которая тоже собирает данные.
Не стоит забывать и о наличии SDK рекламных сетей и прочих SDK в составе приложения. Более того, в одном приложении может быть сразу несколько различных SDK.
Рассмотрим распределение популярных SDK по устройствам.
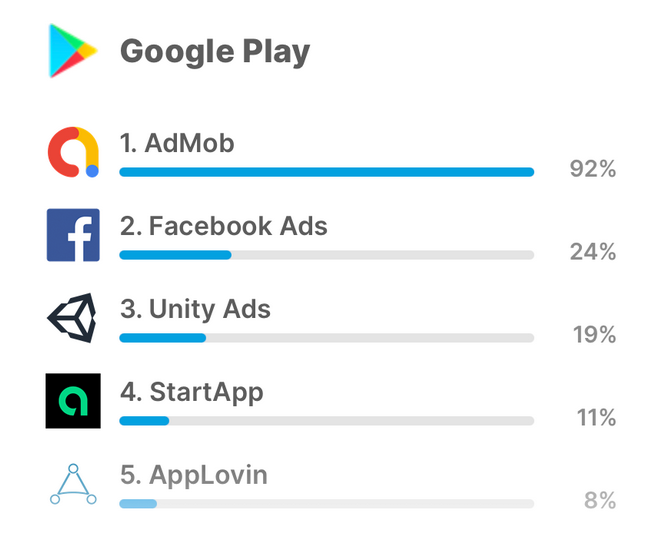
Исходя из вышеприведённых данных, SDK AdMob, принадлежащий Google, встроен в более чем 90% приложений на Android! Только представьте себе, какой объём данных способна собирать Google, если она может получать информацию от 19 из 20 приложений на вашем устройстве?
А это очень лакомый кусок пирога. И если оценить влияние предложений Google для Chrome на рынок веб-рекламы достаточно сложно, так как они ещё не вступили в силу в полной мере, то грядущие изменения для Android можно оценить на примере новой политики конфиденциальности Apple и Meta.
Напомним: Apple обязала разработчиков приложений раскрывать, какие данные они собирают. Активнее всех против нововведения Apple выступила Meta, которая публично раскритиковала новую политику и попыталась препятствовать её внедрению посредством судебных исков. В итоге Meta подчинилась правилам, а Messenger оказался лидером по объёму сбора пользовательских данных среди всех приложений в App Store. Иронично, не правда ли?
Отчет Meta за четвертый квартал, опубликованный в феврале, показал снижение чистой прибыли компании, а основная её часть — это доходы от рекламы. На этом фоне капитализация компании снизилась почти на $250 млрд.
Предпринимаемые Apple шаги могут нанести серьезный удар по рекламной деятельности компании. Meta заявила, что недополучит $10 млрд рекламной выручки за 2022 год из-за новой политики конфиденциальности Apple.
Теперь ясно, почему Meta так резко выступала против новой политики Apple. Любопытный факт: после того как Apple обязала всех разработчиков сообщать о том, какие данные собирают их приложения, Google не обновляла свои приложения для iOS более одного месяца.
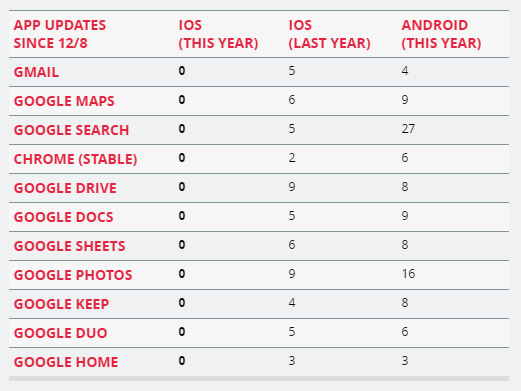
Согласитесь, это просто кошмар для компании, которая существует благодаря рекламе.
Тем не менее, Google вынуждена идти по стопам Apple и заставлять разработчиков раскрывать информацию о сборе данных их приложениями. Причина кроется в общественном давлении и нежелании отстать от своего главного конкурента.
Можем резюмировать, что, хотя Google и пробует бороться с фингерпринтингом, она делает это более мягкими методами, чем Apple, и, в основном, для видимости. Технические причины, которые бы помешали компании продолжать собирать информацию о пользователях, просто-напросто отсутствуют.
FLEDGE для Android
Мы уже рассказывали о технологии FLEDGE для web: FLEDGE для Android работает по такому же принципу. Она призвана защитить пользовательские данные от неправомерного использования третьими лицами.
Одним из наиболее ярких примеров недобросовестного использования личных данных является печально знаменитый случай с магазином Target в США. На основании того, что беременная девочка-подросток смотрела/покупала в интернете, магазин отправил скидочные купоны на одежду для грудничков и памперсы на её адрес. Родители девочки не знали о её положении и сильно удивились, получив купоны по почте. Сегодня неправомерное использование данной технологии уже не кажется чем-то незначительным.
В свою очередь, Google предлагает специальные алгоритмы для создания «списков аудиторий», которые бы хранились локально на устройстве. Реклама для показа пользователю будет выбираться специальным алгоритмом внутри устройства на основе списков. Такой подход направлен на избежание попадания данных к третьим лицам.
Attribution reporting
Эта технология вносит изменения в учет и измерение конверсии. Рекламодатели хотят знать, как пользователь взаимодействует с их рекламой, на что он кликает, на каком моменте отваливается и т.д., чтобы понять, что привлекает аудиторию и какие рекламные объявления «продают» больше. Сейчас эта информация привязывается к уникальному идентификатору пользователя и собирается различными SDK. Мы можем догадаться, что с этой информации происходит дальше.
Google, по аналогии с предыдущими механизмами, предлагает выполнять все измерения и расчёты на самом устройстве, удалять уникальный идентификатор пользователя и в агрегированном и зашифрованном виде отправлять отчёт рекламодателю. Расшифровать эти данные самостоятельно рекламодатель не сможет.
Таким образом, рекламодатель для начала должен будет зарегистрироваться в соответствующем доверенном сервисе и затем передать ему накопленные данные в зашифрованном и агрегированном виде. В сервисе же будет происходить расшифровка и проверка легитимности атрибуции.
Помимо этого, ограничивается количество собираемой информации при триггерах (количество бит информации, доступных для отчетов событий). Например, для триггеров для кликов (click-through triggers) будет доступно всего 3 бита информации, что не позволит, например, получить сведения о времени клика. Будут введены ограничения на количество триггеров. Также компании не смогут регистрироваться в сервисе повторно и получать разные данные по нескольким каналам. Тем самым количество собираемой информации сократится, а доступных объёмов будет достаточно лишь для получения действительно необходимых данных о конверсии.
Выводы
Можно заключить, что представленные Google технологии ещё нуждаются в доработке. Некоторые из них, а именно: Runtime SDK, Fledge, Attribution Reporting, действительно полезны и повышают уровень конфиденциальности пользователей.
Однако польза от такой технологии, как Topics, неочевидна. Скорее всего, с этой технологией будет проще выдавить с рынка небольшие компании, что упрочит и без того доминирующее положение техногигантов. При этом главная проблема останется нерешенной: кто сказал, что собирать данные и делиться нашими интересами без нашего согласия — нормально?
В одном можно быть абсолютно уверенным: технология, алгоритмы, инфраструктура для реализации данных механизмов делает Google монополистом на рынке рекламы для Chrome и Android. Компания технически никак не ограничивает себе сбор информации пользователей за счёт разветвлённой системы приложений, сервисов и SDK.
В войне между AdTech и приватностью пользователей (пока) побеждает Google.












































