Не фильтрами едиными: переосмысление блокировки рекламы с помощью LLM
Одно из самых больших препятствий, с которым постоянно сталкиваются блокировщики рекламы на протяжении всего своего существования, тесно связано с их самой сущностью — это ограничения фильтров и необходимость их обслуживания. В большинстве случаев это обслуживание осуществляется вручную и требует чрезвычайно кропотливой работы.
В этом исследовании я рассмотрю, как работает блокировка рекламы, и проанализирую предыдущие попытки её автоматизации с помощью машинного обучения. Затем я перейду к своим экспериментам по добавлению больших языковых моделей (LLM) в блокировку рекламы, расскажу, куда ведёт этот подход, и даже покажу рабочий прототип браузерного расширения, который вы можете скачать и протестировать самостоятельно.
И хотя я знаю, что вы, вероятно, с нетерпением ждёте рассказа об экспериментах с LLM и хотите попробовать расширение, сначала давайте зададим некий фон.
Как работает блокировка рекламы сегодня
В основе всех блокировщиков рекламы лежат фильтры, которые поддерживаются сообществом. Эти фильтры состоят из тысяч правил, которые делятся на две основные категории: сетевые и косметические правила.
Сетевые правила: первая линия защиты
Действия: блокировка, перенаправление или изменение запросов.
Пример: правило ||evil-ads.com^ блокирует сайт evil-ads.com и его поддомены.
Сетевые правила блокируют запросы к сторонним рекламным серверам ещё до того, как контент достигает браузера — это быстрый и эффективный подход. Эти правила могут блокировать, перенаправлять или изменять запросы.
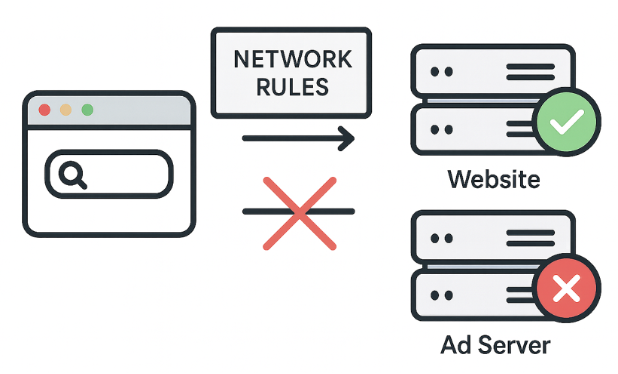
Но сетевые правила не могут блокировать всё. Например, некоторая реклама загружается с того же домена, что и основной контент, поэтому её блокировка на сетевом уровне приведёт к сбою работы сайта. Здесь на помощь приходят косметические правила.
Косметические правила: очистка страницы
Действия: использование селекторов CSS, чтобы скрыть нежелательные элементы непосредственно на странице или применить пользовательские стили.
Пример: правило example.com##.ad-banner скрывает элементы с классом "ad-banner" на example.com)
CSS (каскадные таблицы стилей) — это язык таблиц стилей, который определяет, как визуально представлены документы HTML или XML. Он указывает, как элементы должны отображаться на экране устройства.
Косметические правила в основном очищают оставшиеся рекламные элементы, которые не могут быть заблокированы более простыми сетевыми правилами.
За пределами CSS: правила скриптлетов
Действия: изменение или отключение определённых функций скриптов на странице.
Пример: правило example.com#%#//scriptlet('abort-on-property-read', 'alert') останавливает скрипт на example.com, если он пытается получить доступ к определённой функции браузера, такой как alert.
Когда CSS недостаточно для работы со сложными скриптами, такими как повторная вставка рекламы, мы используем скриптлеты. Скриптлеты — это небольшие фрагменты JavaScript-кода, которые блокировщики рекламы добавляют, чтобы нейтрализовать нежелательное поведение на странице.
Скриптлеты стали любимым инструментом разработчиков фильтров, потому что они решают проблемы, с которыми не справляются CSS и сетевые правила.
Возможности и ограничения
Мы кратко рассмотрели, как работают фильтры. Они мощны и очень хорошо работают с известными шаблонами, но у них есть и некоторые ограничения. Они не справляются с нативной рекламой, требуют постоянных обновлений, а в Manifest v3 делать эти обновления сложнее.
Эти ограничения приводят к фундаментальному вопросу: а что, если мы сможем полностью отказаться от фильтров? Что, если блокировщик рекламы сможет сам решать, что блокировать?
Представьте себе — никаких фильтров, никаких обновлений, никакой погони за рекламными сетями. Никаких ручных настроек и никаких игр в кошки-мышки. В конце концов, разве не этого пользователи хотят от блокировщиков рекламы? «Установил и забыл», возможность наслаждаться чистым интернетом без необходимости уделять какое-либо дополнительное внимание своему блокировщику. И это именно то, чего хотели достичь ранние эксперименты в области машинного обучения.
И, с этой мотивацией в уме, давайте посмотрим, как компании и исследователи пытались использовать машинное обучение для решения этих проблем.
Краткая история машинного обучения в блокировке рекламы
Давайте рассмотрим различные попытки заменить фильтры машинным обучением в прошлом. Это поможет нам понять, почему этого не произошло — по крайней мере, пока.
Проект Moonshot от eyeo
Цель: автоматизировать косметическую фильтрацию в больших масштабах.
Метод:
- Обучение модели машинного обучения на структуре страницы (DOM, HTML, CSS)
- Использование существующих фильтров для маркировки
- Анализ страниц непосредственно в браузерном расширении
Проект Moonshot от eyeo был представлен на Ad-Filtering Dev Summit в 2021 году. Они обучили модель структуре страницы, используя фильтры в качестве меток. Модель работала внутри браузерного расширения, чтобы предсказывать и скрывать рекламные элементы. Она работала, но сталкивалась с проблемами: несбалансированными наборами данных, трудностями внедрения и постоянной необходимостью переобучения.
Основная идея: решения на основе структуры страницы, а не изображений.
Результат: прогнозирование и скрытие рекламных элементов, дополняющее сетевую блокировку.
Проблемы: дисбаланс наборов данных, трудности с внедрением и постоянное переобучение.
AdGraph от Brave
Цель: Блокировать рекламу и трекеры в режиме реального времени.
Метод:
- Создание графика, связывающего все действия на странице (DOM, сеть, JavaScript)
- Классификация контента на основе его контекста в графике
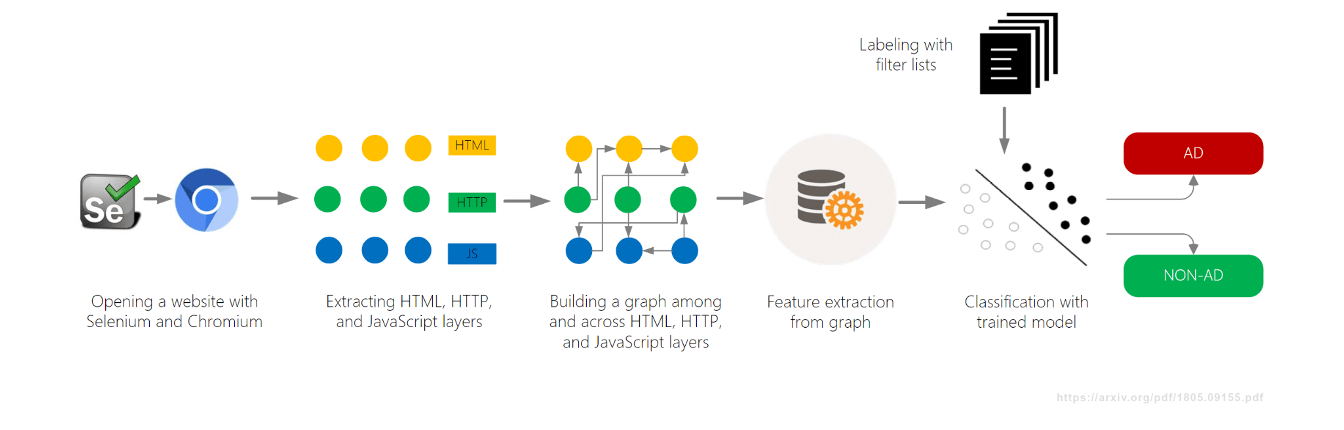
Ещё один проект в области машинного обучения, AdGraph, был разработан браузером Brave и представлен в 2019 году, также на AFDS. Они построили график, отслеживающий, как всё на странице соединяется — DOM, сеть, JavaScript — а затем классифицировали ресурсы на основе контекста.
AdGraph достиг высокой точности, отслеживая скрипты до рекламных серверов даже со случайными именами. Но для этого требовалась глубокая интеграция с браузером и постоянное обслуживание.
Ключевая идея: решения, основанные на причинности, а не только на статических шаблонах URL.
Результат: очень высокая точность (~95–98%) и устойчивость к обфускации.
Проблемы: требовалась глубокая интеграция с браузером и постоянное обслуживание.
PERCIVAL от Brave
Цель: Блокировать рекламные изображения в режиме реального времени.
Метод:
- Использование компактной нейронной сети (CNN) для классификации изображений.
- Внедрение её непосредственно в конвейер рендеринга изображений браузера.
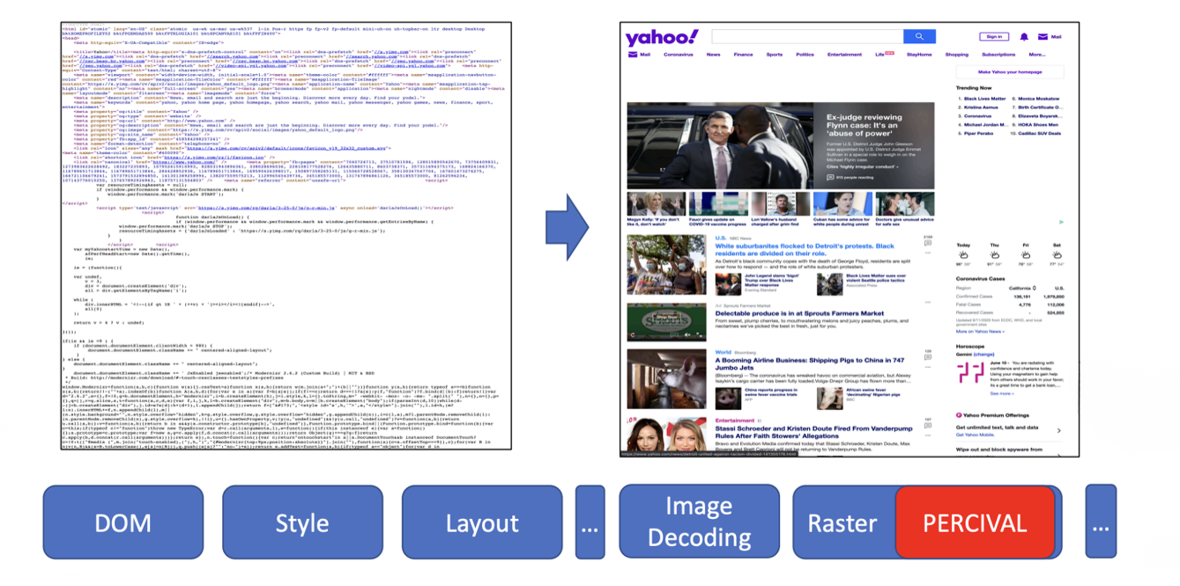
В 2020 году Brave представил другой подход к машинному обучению под названием PERCIVAL, который блокировал рекламные изображения. Они встроили компактную нейронную сеть непосредственно в конвейер рендеринга браузера для классификации изображений по мере их загрузки. Результаты были впечатляющими: они достигли точности 97%, анализируя содержимое изображений напрямую. Но у этого подхода были и свои ограничения — он был уязвим для адверсариальных изображений и работал только с графическими рекламными объявлениями.
Ключевая идея: анализировать визуальное содержание изображения, а не только его URL или метаданные.
Результат: точность ~97% при низких затратах на рендеринг.
Проблемы: уязвимость к адверсариальным изображениям; ограничение только графическими рекламными объявлениями.
AutoFR (научное исследование)
Цель: автоматическая генерация правил фильтрации с нуля.
Метод:
- Использование метода обучения с подкреплением (система проб и ошибок) для тестирования правил.
- Анализ содержания страниц, чтобы избежать сбоев в работе сайта.
Помимо усилий представителей отрасли, к поиску лучших решений присоединились и научные исследователи. Одним из интересных проектов стал AutoFR, целью которого была автоматическая генерация правил фильтрации.
AutoFR был представлен исследователем Hieu Van Le на AFDS 2022 и AFDS 2023.
Даный метод генерирует шаблоны URL и селекторы CSS, тестирует их и учится на результатах, избегая при этом сбоев в работе сайта. Результаты были весьма впечатляющими: AutoFR достиг эффективности 86% (по сравнению с EasyList), а правила генерировались за считанные минуты.
Ключевая идея: автоматическое создание правил с учётом возможных сбоев в работе сайта.
Результат: ~86% эффективности блокировки; правила генерируются за считанные минуты.
SINBAD (научное исследование)
Цель: обнаружение и точная локализация сбоев в работе сайта, вызванных блокировкой рекламы.
Метод:
- Использование «веб-салиентности» для выявления важных визуальных элементов.
- Сравнение версий страниц с блокировщиком рекламы и без него для выявления сбоев.
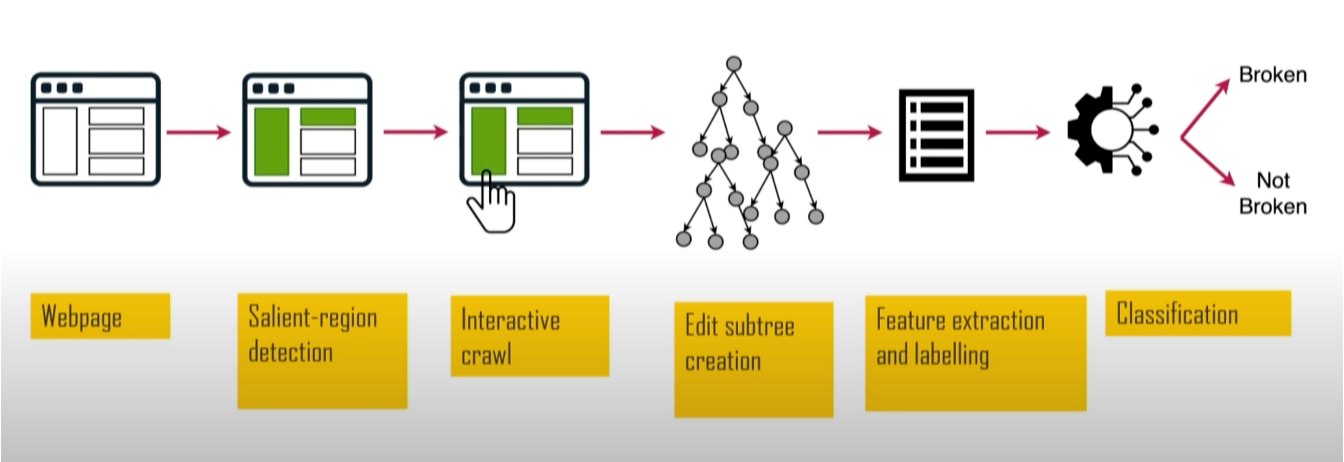
Ещё одним академическим проектом был SINBAD. Он обнаруживал случаи, когда правила фильтрации приводили к сбоям в работе сайтов. У него была большая ценность — сбои в работе сайтов являются одной из основных причин, по которым пользователи отказываются от блокировщиков рекламы. Проект был представлен на AFDS 2023 Сандрой Сиби из (на тот момент) Имперского колледжа Лондона.
Анализируя размер, положение и контраст, он выявляет визуально заметные элементы, такие как заголовки и кнопки, а затем тестирует их на сбой. SINBAD достиг высокой точности в обнаружении сбоев, с конкретными отчётами, показывающими, что именно сломалось и из-за каких правил.
Ключевая идея: сосредоточиться на видимом для пользователя воздействии, чтобы быстрее находить и исправлять проблемы.
Результат: более высокая точность в обнаружении сбоев с конкретными, действенными отчётами.
Почему машинное обучение не захватило рынок
Мы рассмотрели все эти эксперименты и исследовательские проекты. Но вот в чём дело: несмотря на всю работу, ни один из этих инструментов, основанных на машинном обучении, не получил широкого распространения. Логично задаться вопросом: почему машинное обучение не заменило фильтры?
Есть несколько причин:
- Высокая планка: фильтры, составленные людьми, чрезвычайно эффективны и развиты. Достичь такой же результативности — непростая задача.
- Высокая стоимость: создание и поддержание больших высококачественных наборов данных обходится дорого, в то время как большинство фильтров поддерживается сообществом бесплатно.
- Уязвимость: специализированные модели могут быть подвержены атакам злоумышленников.
Как оказалось, создание специализированных моделей с нуля — это медленный, дорогой и негибкий процесс. Именно поэтому подход на основе машинного обучения пока не набрал популярности, и мы по-прежнему полагаемся на старые добрые фильтры. Но, может, ситуация скоро изменится?
LLM вступают в игру: большие, дорогие… но другие
И вот появляются большие языковые модели (LLM) и начинают менять мир. Могут ли они изменить и блокировку рекламы? Давайте посмотрим, как LLM можно использовать для блокировки рекламы в браузерных расширениях. Но сначала давайте пройдёмся по основным характеристикам, которые определяют LLM.
Переосмысление блокировки с помощью LLM: сила быстрого прототипирования
Большие языковые модели (LLM) всё ещё находятся на стадии разработки, но они невероятно быстро прогрессируют. Сейчас они широко доступны через API, что позволяет разработчикам с минимальными усилиями интегрировать возможности на основе LLM в свои продукты. Многие модели доступны как в облачной, так и в локальной версии, что даёт пользователям гибкость в зависимости от их потребностей.
Возможности LLM варьируются от генерации высококачественного текста до анализа данных, создания изображений и видео, написания кода и поддержки сложных рабочих процессов. Это делает их ценными во многих отраслях и востребованными миллионами людей. Но не всё так радужно: запуск этих моделей или доступ к ним может быть дорогостоящим, особенно в больших масштабах — это реальная проблема внедрения LLM во многих областях.
Но самое важное то, что LLM позволяют очень быстро тестировать идеи. Итак, пора наконец показать вам мои эксперименты по применению LLM для блокировки рекламы в браузерных расширениях.
Эксперимент 1. Блокировка по смыслу
Идея моего первого эксперимента заключалась в том, чтобы проверить, может ли LLM мгновенно различать различные типы контента.
Идея:
- Немедленно «размываем» все посты.
- LLM анализирует их содержание.
- LLM убирает размытие, если контент безопасен, или оставляет его, если нет.
Я решил протестировать это на ленте X. Я брал код каждого поста и отправлял его LLM, спрашивая, касается ли он политики. Поскольку LLM работают немного медленно, я сразу же размывал все посты, анализировал их с помощью LLM, а затем убирал размытие, если они были безопасны.
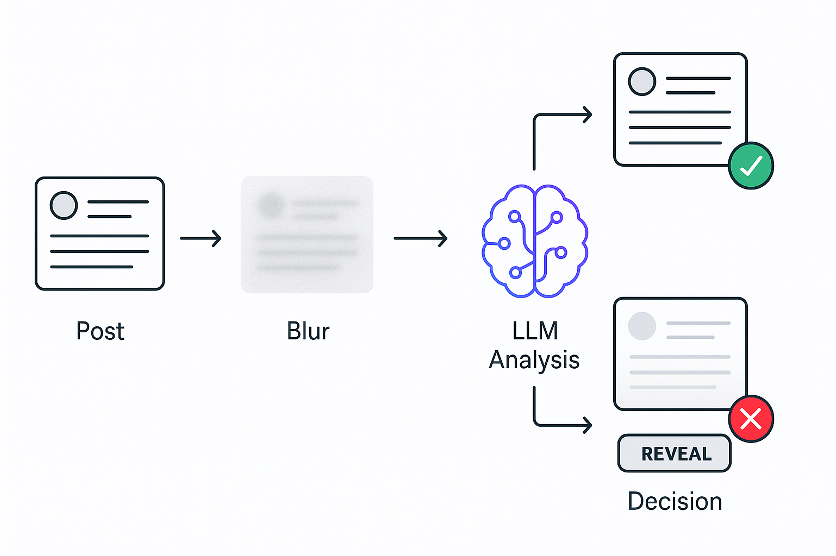
И это сработало!
Это доказывает, что новый семантический способ фильтрации контента возможен. И я создал прототип этого расширения всего за несколько часов — то, что заняло бы месяцы с традиционным машинным обучением.
Давайте посмотрим краткую демонстрацию:
На демонстрации можно увидеть, как это работает. Появляется пост, сразу же размывается, LLM анализирует его, затем снимает размытие, если он безопасен, или оставляет его скрытым, если нет. Пользователи могут вручную убрать размытие с любого поста.
Во время экспериментов с X я заметил, что некоторые посты не блокировались, потому что в основном состояли из изображений. Это привело меня ко второму эксперименту.
Эксперимент 2. Блокировка по визуальному значению
В этом эксперименте я научу блокировщик рекламы видеть.
Идея:
- Немедленно «размываем» все посты
- «Зрячий» LLM анализирует скриншот с постом
- Размытие снимается, если пост безопасен, или сохраняется, если нет
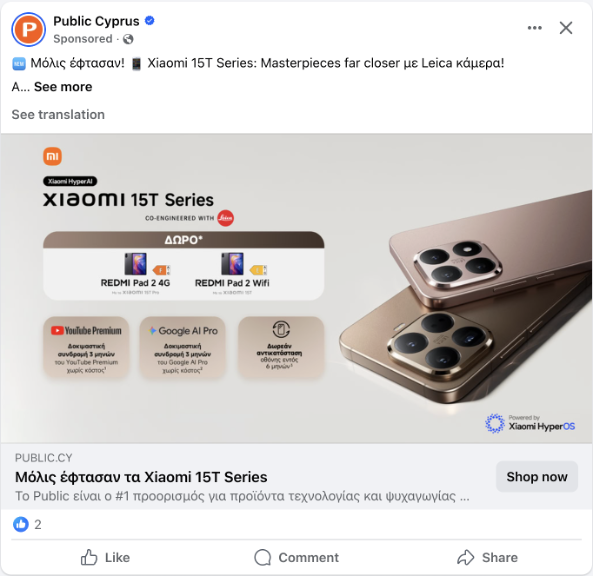
Посты часто содержат минимальное количество текста. Вот пример этой проблемы — пост в Facebook, в котором почти нет текста, только изображение.
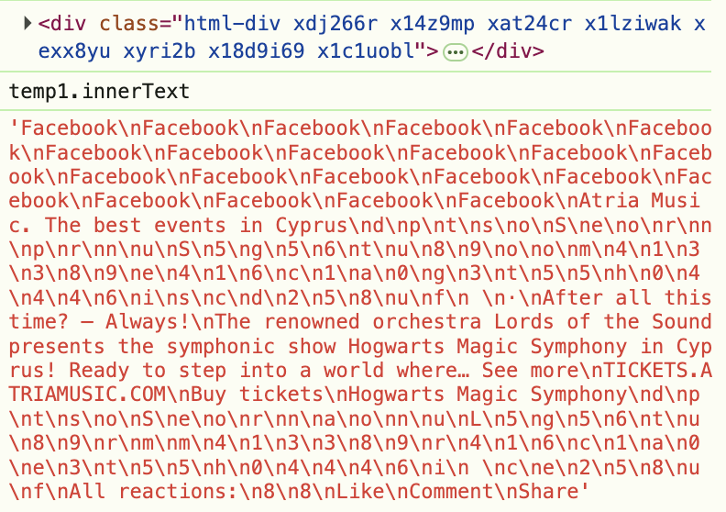
Но дело не только в постах без текста. Даже когда текст присутствует, сайты скрывают его с помощью обфусцированного HTML. Например, посмотрите на этот скриншот из инструментов разработчика — вы можете видеть, что метка Sponsored скрыта в рандомизированном HTML.
Вот почему мы должны перестать анализировать код и начать анализировать то, что пользователи действительно видят. Идея похожа на первый эксперимент, но теперь мы анализируем не код, лежащий в основе элемента, а то, что пользователи действительно видят на странице. Давайте сделаем скриншот поста, отправим его в LLM с функцией распознавания изображений и спросим, касается ли он политики.
Это снова сработало! Основная идея была воплощена в прототипе всего за час или около того. Но затем возникла настоящая проблема — делать скриншоты через браузерное расширение оказалось настоящим кошмаром.
И вот почему. Одним из подходов, который я попробовал, был Debugger API. Debugger API позволяет захватывать любой элемент, даже за пределами области просмотра (области, видимой в данный момент на экране), но это вызывает мерцание страницы, что может раздражать пользователей. См. демонстрацию ниже:
Другой подход заключался в использовании chrome.tabs.captureVisibleTab — стандартного API-расширения Chrome для создания скриншотов. Этот подход не вызывает мерцания, но позволяет захватывать только то, что в данный момент видно в окне просмотра, и Chrome при этом ограничивает количество скриншотов, которые можно сделать в секунду.
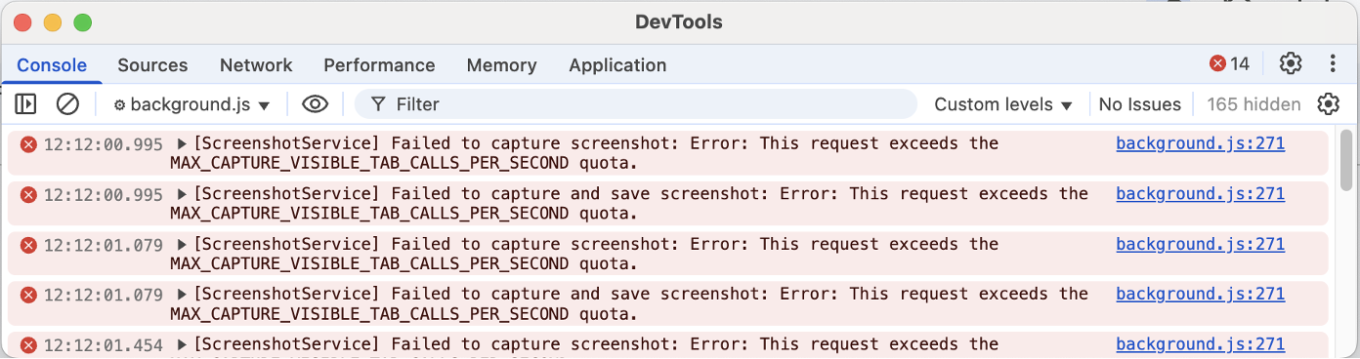
Таким образом, если у вас есть несколько элементов для анализа, вам придётся ждать, и вы сможете проверить только те посты, которые уже отображаются на экране.
Эти эксперименты показали, что LLM могут анализировать посты и принимать решение об их блокировке. Означает ли это, что мы можем полностью заменить фильтры? Нет, они по-прежнему нужны нам, чтобы знать, что нужно проверять. Веб-страница содержит тысячи элементов, и анализ их всех будет медленным и дорогостоящим.
Эксперимент 3. Расширение фильтров: новый примитив
Если нам по-прежнему необходимо знать, какие элементы следует проверять, логичным шагом будет соединить LLM с фильтрами и обобщить возможности LLM в виде многоразового инструмента для авторов фильтров. Но проблема в том, что написание нового пользовательского расширения для каждой семантической задачи не масштабируется — нам нужно более общее решение.
Вдохновение: расширенный псевдокласс CSS, :contains.
Вопрос: а что, если мы сможем проверять не только текст, но и значение?
Результат: три новых экспериментальных псевдокласса:
selector:contains-meaning-embedding('criteria')
selector:contains-meaning-prompt('criteria')
selector:contains-meaning-vision('criteria')
Для создания этого универсального решения я вдохновился библиотекой Extended CSS от AdGuard. Extended CSS — это библиотека JavaScript, которая добавляет дополнительные псевдоклассы, расширяя возможности нативного CSS.
В ней есть псевдокласс :contains(), который скрывает элементы с определённым текстом. Я решил, что мы можем усовершенствовать этот подход, чтобы проверять семантическое значение, а не только ключевые слова. Это привело к созданию трёх прототипов: embedding, prompt и vision.
:contains-meaning-embedding
Как это работает: сравнивает сходства между текстом и критериями.
Плюсы: очень быстрый и дешёвый.
Минусы: требует установки пороговых значений, есть трудности с несколькими языками.
Начну с :contains-meaning-embedding. Это правило использует модели встраивания, которые преобразуют текст в числа, представляющие значение. Мы вычисляем сходство между текстом элемента и критериями и решаем, соответствуют ли они друг другу. Преимущество в том, что это быстро и дешёво благодаря кешированию. Недостаток в том, что требуется настройка порогового значения и могут возникнуть проблемы с несколькими языками.
:contains-meaning-prompt
Как это работает: спрашивает LLM, соответствует ли контент критериям
Плюсы: более точный, без пороговых значений, независимый от языка
Минусы: более медленный и дорогой
Далее идёт :contains-meaning-prompt. Эти правила используют простой API-интерфейс, в котором мы просто спрашиваем, соответствует ли содержание какого-либо элемента критериям. Это более точно, не требует пороговых значений и работает на всех языках. Недостаток — это более медленный и дорогой способ, чем встраивание (embedding).
:contains-meaning-vision
Как это работает: спрашивает LLM, соответствует ли скриншот критериям.
Плюсы: улавливает то, что упускают текст и вложения.
Минусы: сложный интерфейс.
И последний метод — :contains-meaning-vision. Он делает скриншоты выбранных элементов и спрашивает LLM с возможностью визуального восприятия, соответствует ли скриншот критериям. После этого он работает так же, как :contains-meaning-prompt. Ключевое преимущество этого подхода — он может обнаруживать визуальный контент, который текстовые методы не могут увидеть. Недостаток — сложный интерфейс с возможным мерцанием экрана.
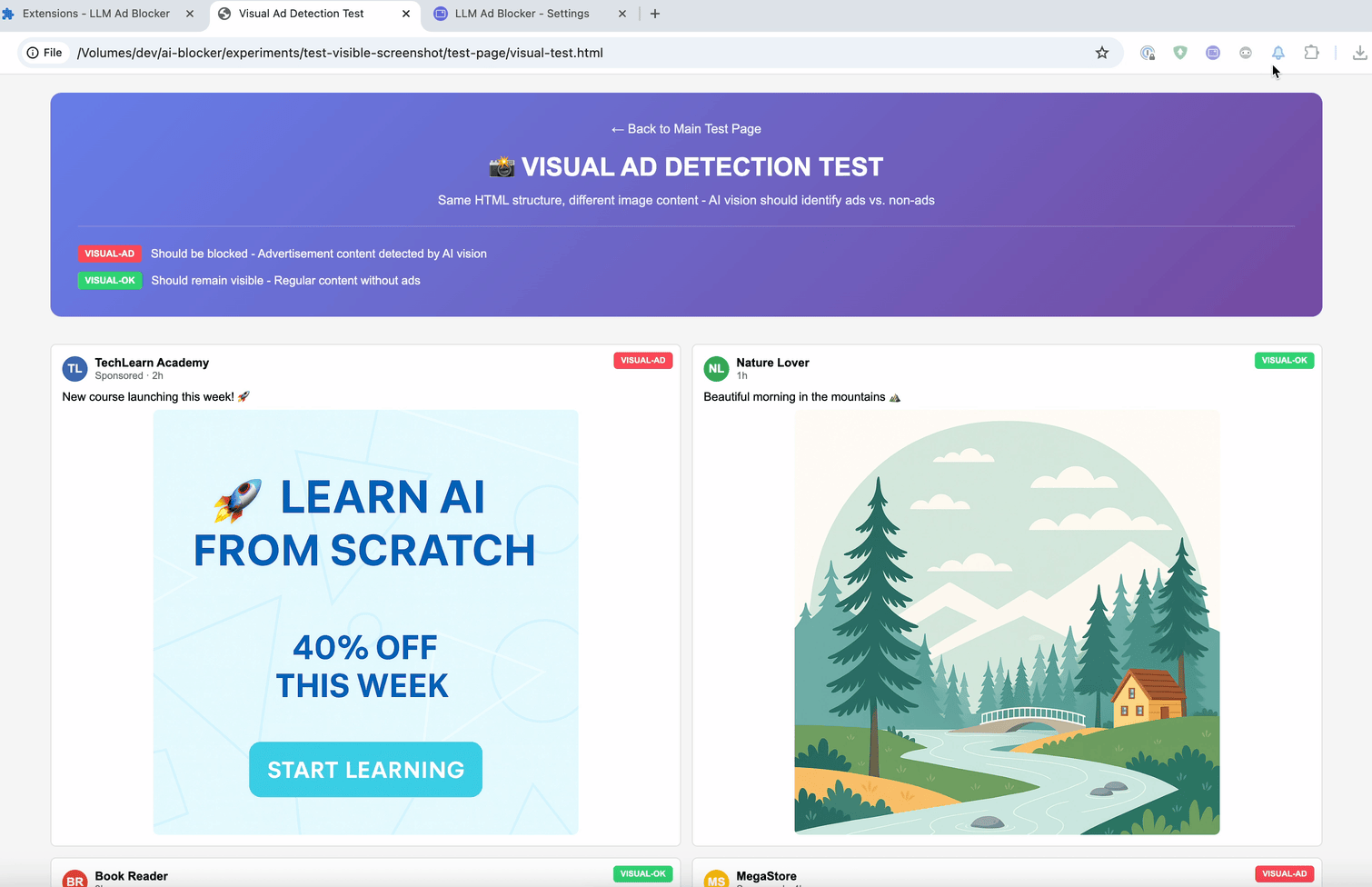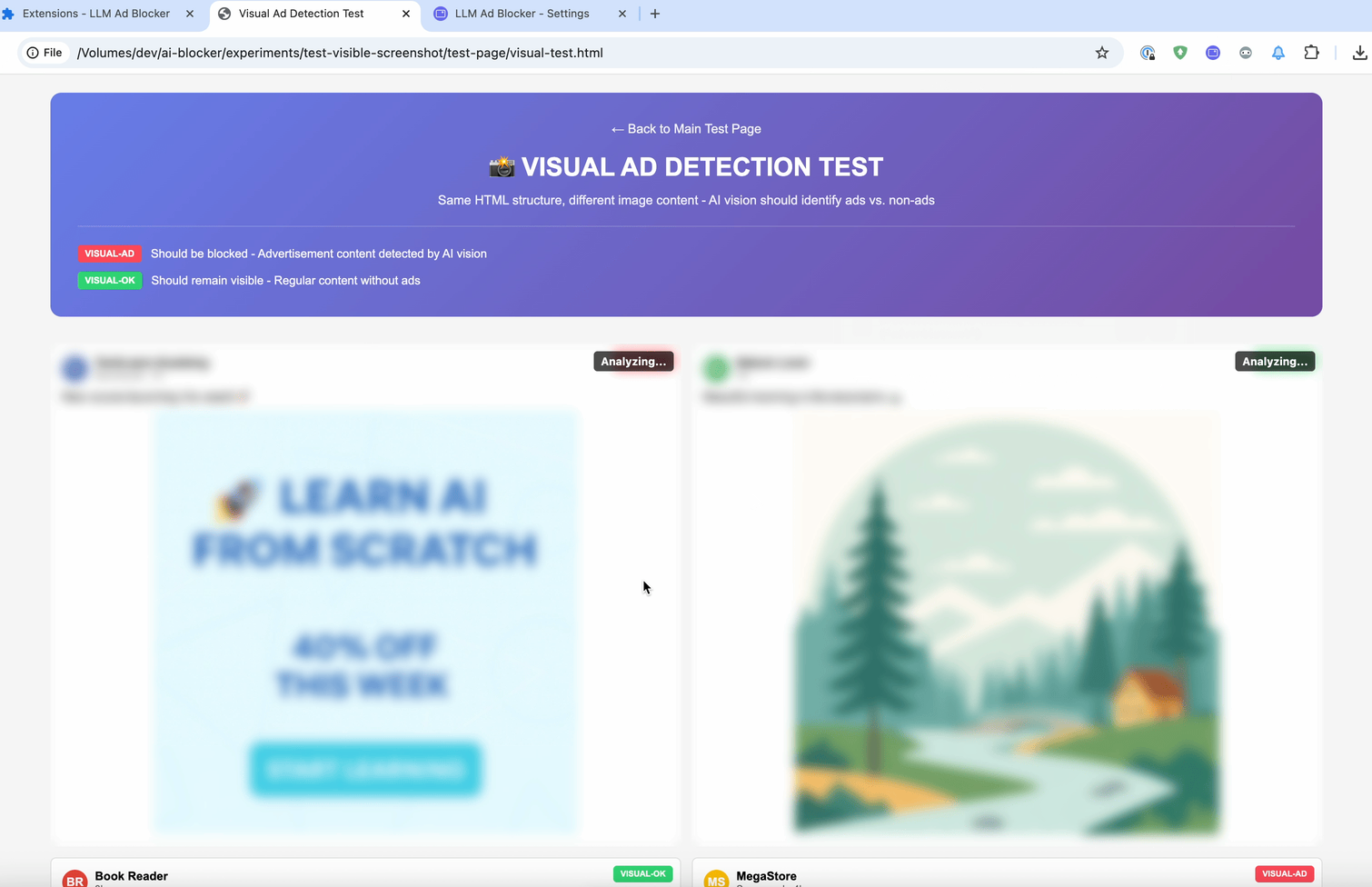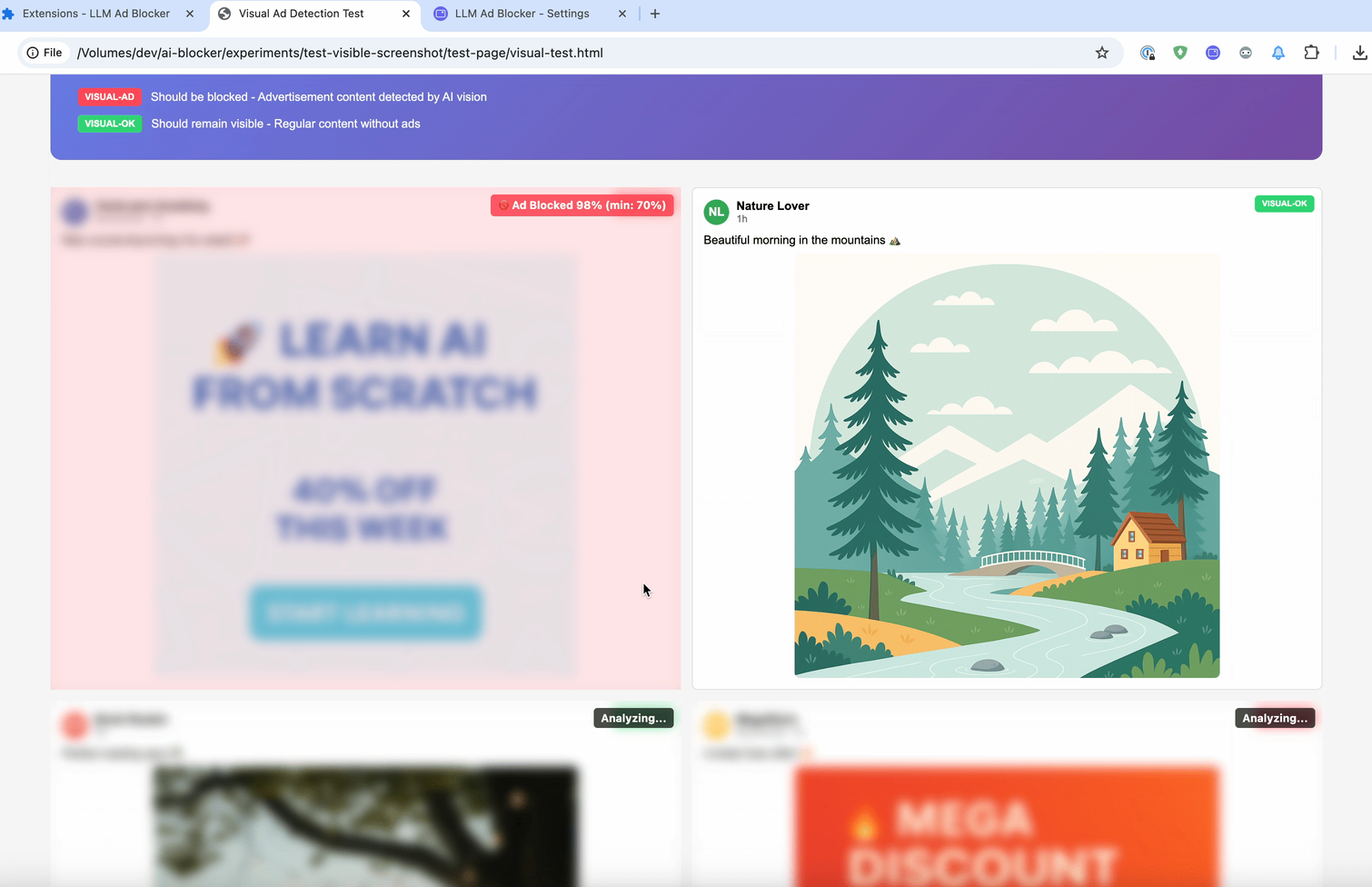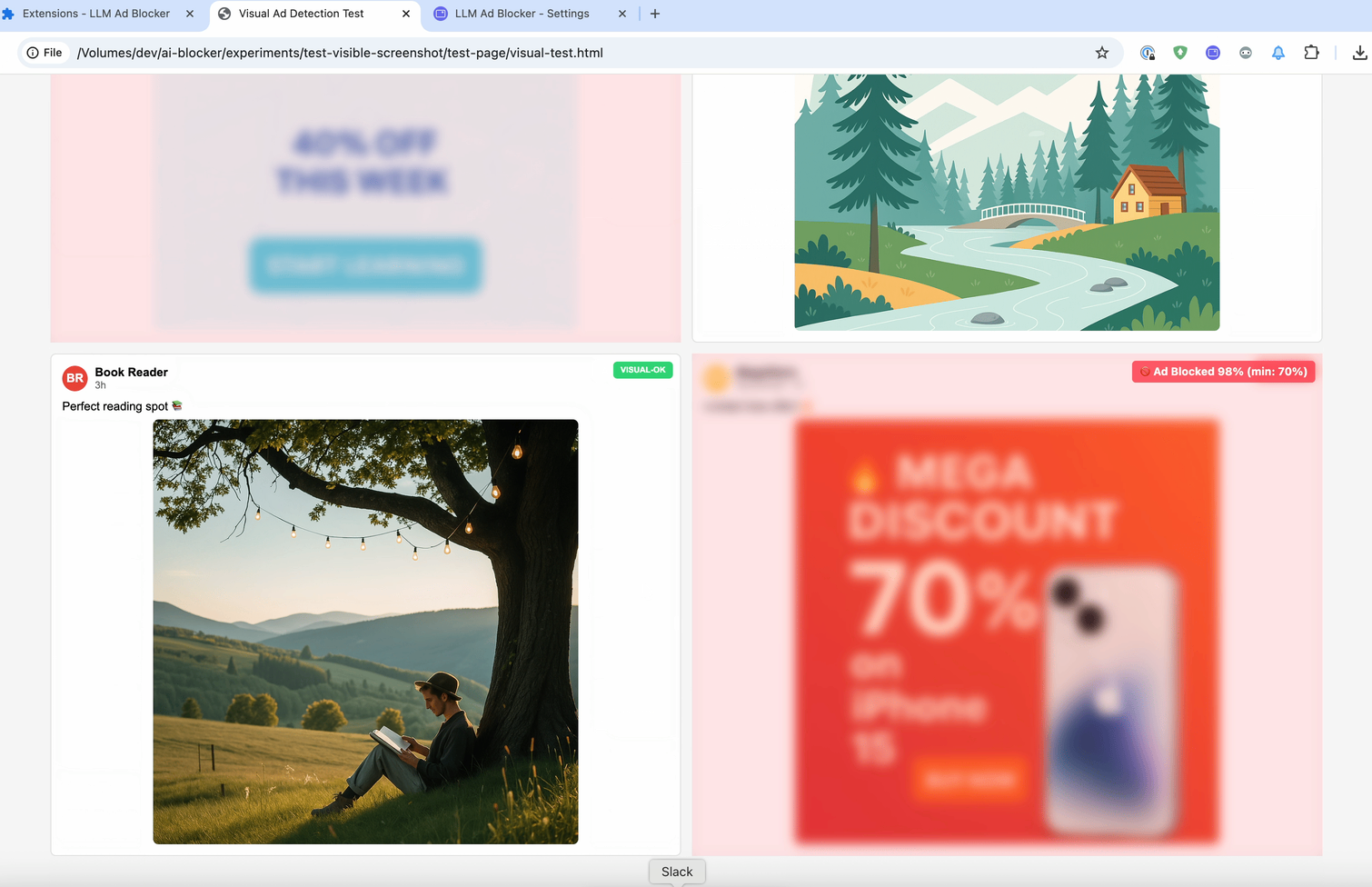
Эти три правила дают разработчикам фильтров гибкий инструмент. Они смогут выбирать: скорость встраивания, точность подсказки или визуальная информация. Чтобы уменьшить задержку анализа, можно сначала размыть элементы, а затем либо убрать размытие, либо оставить их скрытыми.
Анализ производительности и затрат
Теперь, когда у нас есть три прототипа, возникает два самых важных вопроса: насколько они практичны? И могут ли действительно работать? Чтобы ответить на них, я проанализировал производительность и затраты для каждого подхода.
Встраивания (embeddings)
Начну со встраиваний. Изначально я запустил расширение с помощью облачной модели OpenAI, и, честно говоря, результаты были не очень хорошими. Но потом я решил попробовать небольшую локальную модель, и результат меня удивил. Она работала быстрее, была полностью бесплатной и достигла в тестах точности 100%. Это показывает, что для определённых задач небольшие локальные модели могут превосходить по производительности большие облачные API.

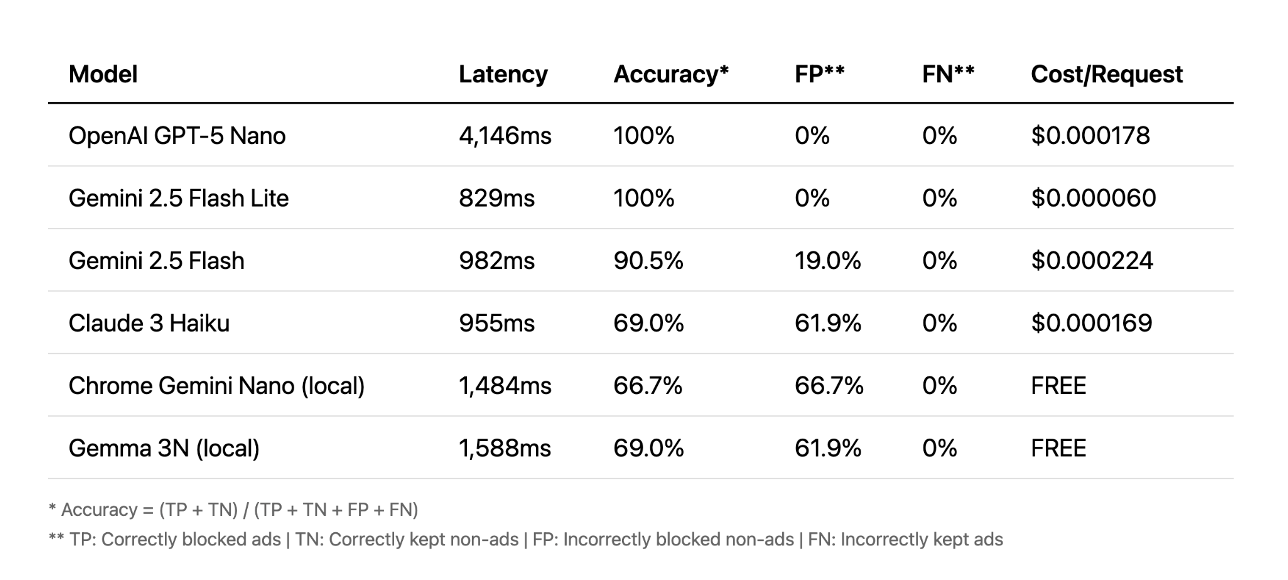
Промпты (prompts)
Далее рассмотрим промпты. Здесь ситуация обстоит иначе. Лучшие результаты показали облачные API, некоторые из которых достигали точности 100% менее чем за секунду. Некоторые тратили более четырёх секунд, что слишком медленно для удобства пользователей. В этом случае локальные модели просто не могли сравниться с точностью облачных.
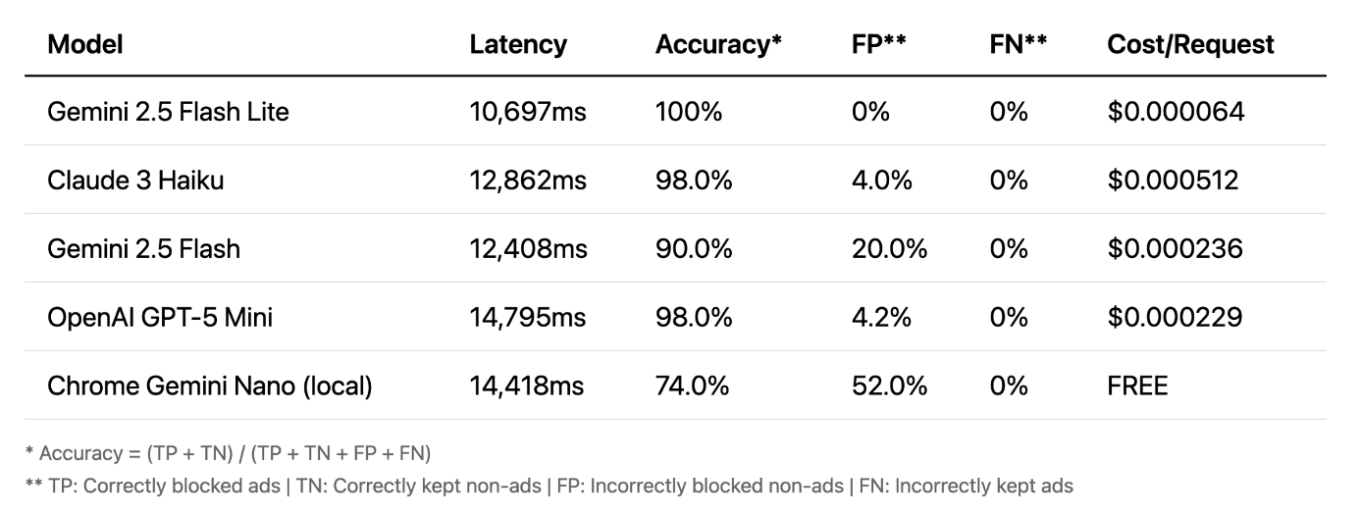
Зрение (vision)
И, наконец, поговорим о зрении. Здесь всё становится действительно интересным. Точность очень высокая — даже локальные модели работают хорошо. Зрение часто является самым точным методом. Его ключевое преимущество в том, что оно работает с изображениями, а не с текстом, ловя рекламу, которую пропускают другие методы. Однако есть один существенный минус: задержка. Задержка в 10–15 секунд непрактична для блокировки в режиме реального времени.
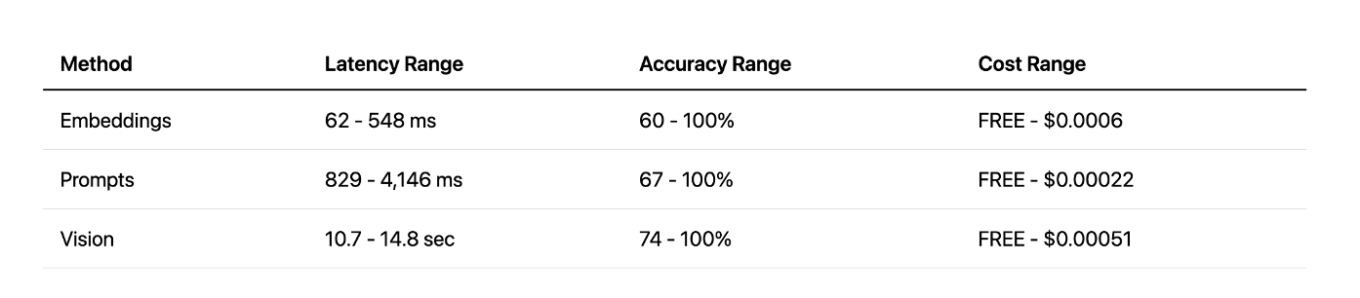
Сравнение методов
При сравнении всех методов зрительный метод обеспечивает высокую точность, но с очень большой задержкой. Подход с использованием подсказок обеспечивает хороший баланс между скоростью и точностью, особенно с облачными API. А подход с использованием локальных встраиваний стал приятным сюрпризом — он очень быстрый и эффективный, но только для определённых задач. В конечном итоге, у каждого метода свои сильные и слабые стороны.
Будущее этого подхода
Видение: сейчас слишком медленно, со временем будет улучшаться.
Встраивание: непрактично в расширениях, было бы идеально, если бы было встроено в браузеры.
Промпты LLM: экспериментально, требует большей точности.
Что это означает для будущего? По моему мнению, видение на данный момент просто слишком медленное. Встраивание не очень практично при использовании в браузерных расширениях, но может хорошо работать в качестве встроенного API браузера. А локальные промпты LLM — наиболее многообещающий путь для реального, готового к внедрению эксперимента с Prompt API Chrome. Существует также проблема улучшения пользовательского опыта, поскольку текущий подход с размытыми элементами не идеален. С помощью более быстрых моделей мы могли бы сократить время размытия, или, возможно, придумать совершенно другое решение.
Что мы узнали? Во-первых, LLM позволяют нам выйти за рамки простого сопоставления шаблонов и действительно понять смысл веб-контента. Это открывает совершенно новый семантический подход к фильтрации. Во-вторых, LLM дают нам возможность быстрого прототипирования. Идеи, которые раньше требовали месяцев разработки, теперь можно протестировать за считанные часы. Хотя ещё остаются практические проблемы, которые необходимо решить, этот новый подход позволяет нам переосмыслить возможности в мире фильтрации контента.
Надеюсь, это заставило вас по-новому взглянуть на фильтрацию контента. Вы можете самостоятельно опробовать всё, о чем я говорил в этой статье — просто установите Блокировщик AdGuard из интернет-магазина Chrome Store.
Полный исходный код также доступен на GitHub. Если у вас есть вопросы или предложения, пишите!













































