Apples Versuch mit der systemweiten Filter-API — taugt es etwas?
Dies ist die übersetzte Fassung eines Artikels von Andrey Meshkov und entsprechend aus seiner persönlichen Perspektive geschrieben.
Apples Ansatz für systemweite Inhaltsfilterung hat in letzter Zeit eine neue API hervorgebracht, die sich deutlich von dem unterscheidet, was Entwickler bisher gewohnt waren. Diese Änderungen haben mich dazu gebracht, neu darüber nachzudenken, wie sich Filtermechanismen auf Betriebssystemebene umsetzen lassen. Gerade deshalb ist dieser Ansatz ein spannendes Fallbeispiel für die Zukunft der Inhaltsblockierung.
Auf dem AFDS drehen sich viele Diskussionen traditionell um Browser und Web-Erweiterungen — also um die Umgebungen, in denen Inhaltsfilterung heute am häufigsten stattfindet. Die systemweite Filterung stellt jedoch eine umfassendere und zunehmend relevante Herausforderung dar. Ein genauer Blick auf die Möglichkeiten und Grenzen von Apples neuer API liefert Erkenntnisse, die auch dabei helfen können, browserbasierte Filterlösungen weiterzuentwickeln.
Bevor wir darauf eingehen, klären wir jedoch zunächst, was genau unter „systemweiter Filterung“ zu verstehen ist.
Was ist systemweite Filterung?
Unter systemweiter Filterung versteht man die Möglichkeit, den Internetverkehr aller Anwendungen zu überwachen und zu blockieren — nicht nur den von Browsern.
Die Filterung innerhalb eines Browsers war schon immer vergleichsweise einfach. Browsererweiterungen bieten dafür eine klare Grundlage, und selbst mit Manifest V3 stellen Browser weiterhin eine gut definierte API für Inhaltsfilterung bereit.
Ganz anders sieht es auf Betriebssystemebene aus. Hier stoßen wir auf ein grundsätzliches Problem: Kein gängiges Betriebssystem stellt eine eigene, speziell für Inhaltsfilterung gedachte API bereit. Wer systemweit filtern möchte, muss daher auf plattformspezifische Techniken zurückgreifen — und jede dieser Lösungen bringt ihre ganz eigenen Einschränkungen mit sich.
An dieser Stelle stellt sich eine naheliegende Frage: Warum ist systemweite Filterung überhaupt wichtig? Reicht es nicht aus, Werbung einfach im Browser zu blockieren?
Aktuelle Studien zeichnen ein klares Bild. Auf Mobilgeräten stammen weniger als 15% des gesamten Datenverkehrs aus Browsern. Auf dem Desktop sind Browser zwar noch führend und machen etwa 55–60% des Traffics aus. Betrachtet man jedoch alle Plattformen zusammen, entfallen nur rund 30% des gesamten Internetverkehrs auf Browser. Die übrigen 70% stammen aus Apps.

Genau hier liegt die eigentliche Herausforderung für den Datenschutz. Tracking innerhalb von Apps ist oft deutlich invasiver als auf Websites. Apps haben Zugriff auf mehr persönliche Daten, können direkt mit Ressourcen des Geräts interagieren und nutzen dauerhafte Kennungen, die Websites schlicht nicht zur Verfügung stehen. Umso wichtiger wird es, den gesamten Datenverkehr eines Geräts filtern zu können.
Systemweite Filterung gehört seit jeher zu den Kernkompetenzen von AdGuard. Tatsächlich war bereits die allererste Version von AdGuard, die vor über 15 Jahren veröffentlicht wurde, eine Windows-Anwendung, die Werbung direkt auf Netzwerkebene blockierte. Im Laufe der Zeit haben wir unsere Lösungen auf alle wichtigen Plattformen ausgeweitet — und sind noch einen Schritt weiter gegangen: mit AdGuard DNS und AdGuard Home, zwei Produkten, die nicht nur einzelne Browser, sondern ganze Geräte oder sogar komplette Netzwerke schützen.
Genau deshalb finde ich dieses Thema besonders spannend. Es gibt hier nach wie vor viel Potenzial für Verbesserungen, und umso erfreulicher ist es, dass nun auch einer der großen Betriebssystemhersteller — Apple — diesem Bereich endlich mehr Aufmerksamkeit schenkt.
Wie das Ganze funktioniert
Um meine Perspektive besser zu verstehen, lohnt sich zunächst ein Blick zurück: Wie hat systemweite Filterung überhaupt begonnen, wie funktioniert sie heute — und mit welchen Herausforderungen haben Entwickler von Werbeblockern weiterhin zu kämpfen?
Ein kurzer Test für alte Hasen: Wussten Sie, dass Werbeblockierung ursprünglich mit HOSTS-Dateien begann? Dabei wurden Werbeserver einfach auf nicht existierende IP-Adressen umgeleitet. Eine HOSTS-Datei ist eine einfache Textdatei, die Hostnamen IP-Adressen zuordnet — im Grunde ganz ähnlich wie ein DNS-Server.
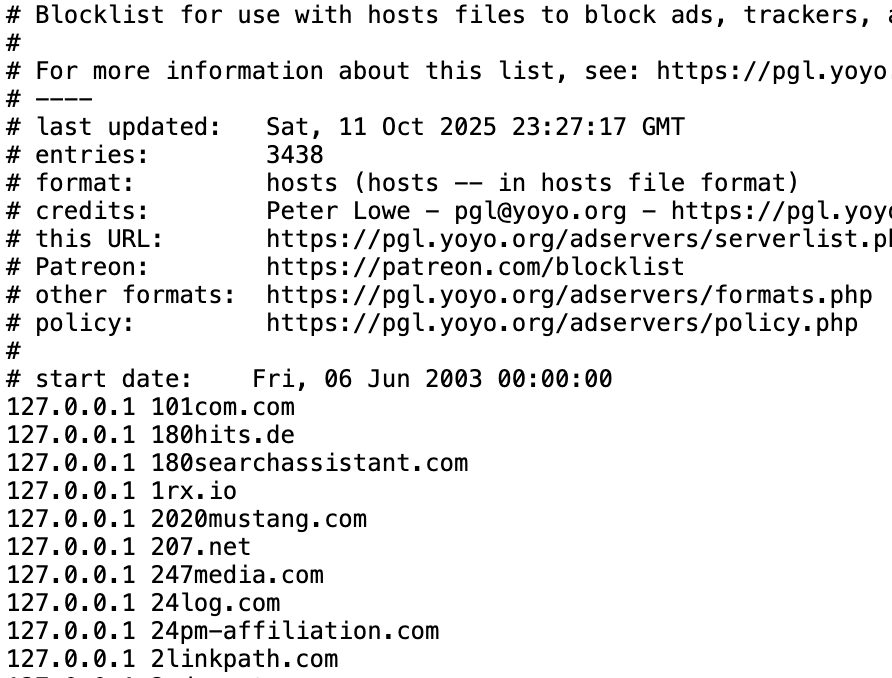
Ausschnitt aus der Peter Lowe’s blocklist
Natürlich haben HOSTS-Dateien klare Grenzen. Sie sind statisch, können nur exakt definierte Domains blockieren, lassen sich nur schwer aktuell halten und können relativ leicht umgangen werden. Trotzdem: Hier nahm alles seinen Anfang.
Ein weiterer verbreiteter Ansatz war später das sogenannte DNS-Sinkholing. Die Grundidee ist dieselbe wie bei HOSTS-Dateien, wird jedoch auf DNS-Ebene umgesetzt — mit dem Vorteil, dass sich so gleich mehrere Geräte gleichzeitig schützen lassen.
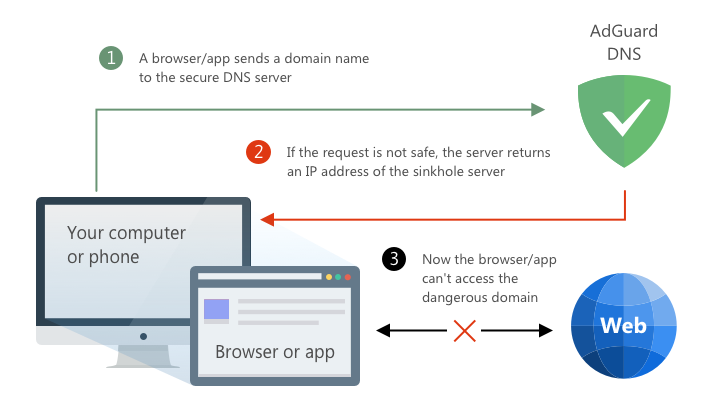
Beispiel für das Blockieren einer Domain über einen DNS-Server
Dieser Ansatz löste einige der ursprünglichen Probleme, brachte jedoch eigene Einschränkungen mit sich. Auch hier lassen sich ausschließlich Domains blockieren — und auch diese Methode kann umgangen werden. DNS-Sinkholing ist daher in vielen Situationen hilfreich, stellt jedoch keine vollständige Lösung dar.
Als Nächstes kamen Proxys ins Spiel — Server, die als Vermittler zwischen Ihrem Gerät und dem Internet fungieren, zumindest für HTTP-Verkehr. Dieser Ansatz war in den Anfangsjahren der Werbeblockierung äußerst verbreitet. Viele der „klassischen“ Tools setzten darauf, darunter Ad Muncher oder auch frühe Versionen von AdGuard. Der Screenshot unten stammt von vor etwa 15 Jahren, als AdGuard (damals noch als Adguard geschrieben!) im Kern genau so funktionierte: als HTTP-Proxy.
Der große Vorteil eines Proxys liegt darin, dass sich der Datenverkehr anhand vollständiger URLs filtern lässt — nicht nur anhand von Domainnamen. Voraussetzung ist allerdings, dass der Verkehr nicht verschlüsselt ist. Und selbst bei verschlüsselten Verbindungen bleibt zumindest der Domainname sichtbar.
Unabhängig davon, welche Methode Sie für systemweite Filterung einsetzen, steht am Anfang immer dieselbe technische Herausforderung: Der gesamte Datenverkehr muss abgefangen und zum Filter umgeleitet werden — egal ob es sich dabei um DNS, einen Proxy oder einen anderen Mechanismus handelt. Je nach Plattform kommen dafür unterschiedliche Techniken zum Einsatz:
- Android: lokales VPN
- iOS: lokales VPN, DNS-Einstellungen über eine Erweiterung
- macOS: Network Extension (transparenter Proxy, DNS-Proxy)
- Windows: WFP-, TDI-, WinSock- oder NDIS-Treiber
Ich werde hier nicht im Detail auf jede einzelne Methode eingehen — das ist an dieser Stelle auch gar nicht nötig. Wichtig ist vor allem eines: All diese Ansätze sind technisch anspruchsvoll, leicht fehleranfällig und führen nicht selten zu Kompatibilitätsproblemen. Dennoch bilden sie die grundlegenden Bausteine, mit denen wir arbeiten müssen, wenn wir Datenverkehr auf Betriebssystemebene filtern wollen.
Selbst wenn wir alle bisherigen Herausforderungen meistern, bleibt noch ein großes Problem: Für präzise Filterung brauchen wir vollständige URL-Sichtbarkeit. Warum das so wichtig ist, möchte ich an zwei Beispielen zeigen.
- Facebooks Werbenetzwerk
Facebook liefert sowohl legitime Inhalte als auch Tracking-Anfragen über dieselbe Domain aus — graph.facebook.com. Ohne Zugriff auf die vollständige URL ließe sich diese Domain nicht blockieren, ohne gleichzeitig Facebook selbst funktionsunfähig zu machen.
Auf die Details gehe ich hier nicht näher ein, aber vereinfacht gesagt werden Werbeauktionen dabei auf die Serverseite verlagert. Anzeigen werden anschließend direkt über die Domain des Publishers ausgeliefert und erscheinen dadurch wie Inhalte aus erster Hand.
Derzeit gibt es nur einen wirklich zuverlässigen Weg, vollständige URLs zu analysieren: einen Proxy mit TLS-Interception. Das ist allerdings technisch extrem anspruchsvoll — und dennoch etwas, auf das wir bislang nicht verzichten können.
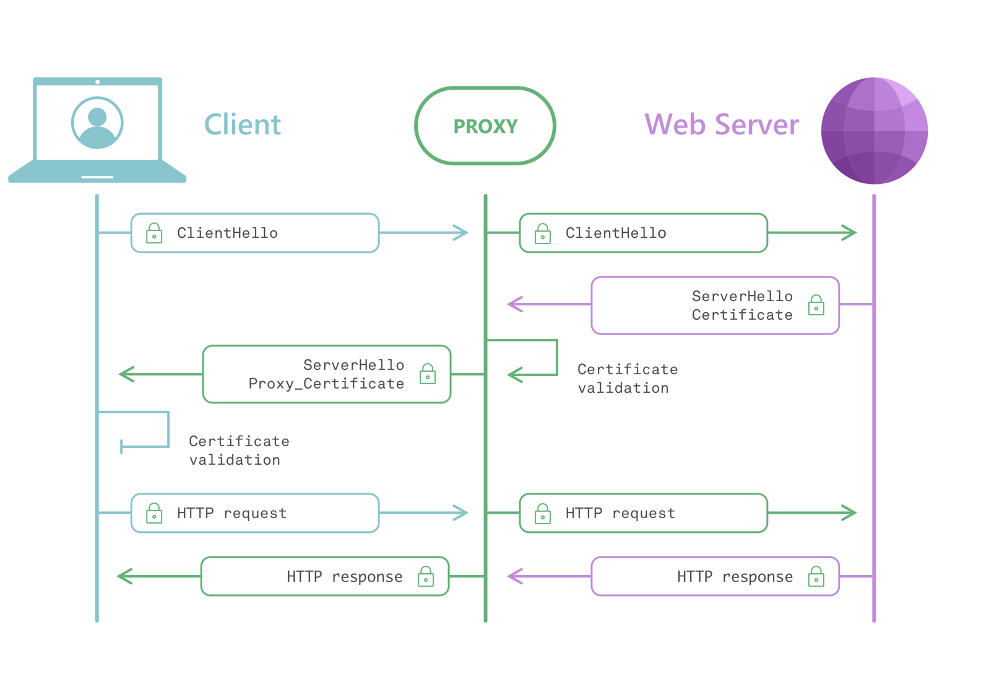
Proxy mit TLS-Interception — schematische Darstellung
Damit Filterung überhaupt funktionieren kann, muss also jemand den Datenverkehr beobachten — sei es eine Browsererweiterung, ein VPN oder eine Sicherheitssoftware. Das lässt sich schlicht nicht vermeiden. Idealerweise geschieht diese Verarbeitung lokal auf dem Gerät. Das ist sicherer, weil die Daten das Gerät nicht verlassen. Doch selbst dann ist Vertrauen erforderlich — und die Vergangenheit hat gezeigt, dass dieses Vertrauen missbraucht werden kann.
Lokale Filterung ist daher zwar die bessere Option, aber keine absolute Garantie für Privatsphäre. Letztlich müssen Sie dem Anbieter vertrauen, der den Filter betreibt.
Wie sollte also eine ideale Lösung für systemweite Filterung aussehen? Es gibt mehrere Kriterien, die sie erfüllen müsste:
Zunächst muss sie vollständige URL-Filterung unterstützen — das ist entscheidend für Genauigkeit.
Sie sollte umfassende Filtermöglichkeiten bieten. Es reicht nicht aus, Anfragen nur zu blockieren; oft müssen sie auch verändert, umgeleitet oder Antworten analysiert werden.
Das System muss mit sehr großen Blocklisten umgehen können.
Gleichzeitig müssen Updates schnell und effizient erfolgen.
Datenschutz sollte von Anfang an mitgedacht sein: Der Content-Blocker sollte nicht wissen müssen, welche Websites aufgerufen werden, sondern Regeln ausschließlich lokal anwenden.
Dennoch sollte es eine gewisse Rückmeldung geben — zumindest grundlegende Statistiken oder eine Bestätigung darüber, was blockiert wurde.
Schließlich braucht es gute Debugging-Tools. Sowohl für Entwickler wie uns als auch für Filterlisten-Maintainer, die ihre Regeln zuverlässig testen und anpassen müssen.
Mit dieser Checkliste im Hinterkopf wenden wir uns nun Apples URL-Filter zu.
Apples URL-Filter
In diesem Abschnitt wird es etwas technischer. Wenn Sie gerade keine Lust auf viele Details haben, können Sie diesen Teil gern überfliegen oder direkt zur Zusammenfassung springen.
Vor etwa zehn Jahren war Apple der erste Browserhersteller, der eine spezielle API für Content-Blocking eingeführt hat. Heute, rund ein Jahrzehnt später, geht das Unternehmen noch einen Schritt weiter — diesmal auf Betriebssystemebene. Zum ersten Mal stellt Apple eine offizielle API für systemweites URL-Filtering bereit. Auf den ersten Blick sind das hervorragende Nachrichten. Und ehrlich gesagt ist es genau das, worauf viele im Bereich Datenschutz und Netzwerkfilterung lange gewartet haben: eine spannende neue Möglichkeit.
Schauen wir uns nun an, wie diese API tatsächlich funktioniert. Zunächst ganz auf hoher Ebene.
Zuerst registriert die App einen speziellen URL-Filter im Betriebssystem. Das gilt sowohl für iOS als auch für macOS.
Anschließend folgt ein Autorisierungsschritt: Das System kommuniziert mit dem eigenen Server, um Konfiguration und Zugangsdaten zu überprüfen.
Ist dieser Prozess abgeschlossen, wechselt der Filter in den Status Running. Ab diesem Moment nutzt das System ihn, um die URLs von Anfragen zu prüfen. Solange der URL-Filter aktiv ist, analysiert er jede Webanfrage, die von beliebigen Apps auf dem System ausgeht.
Schauen wir uns an, was passiert, wenn eine App eine Anfrage an https://example.org/test senden möchte:
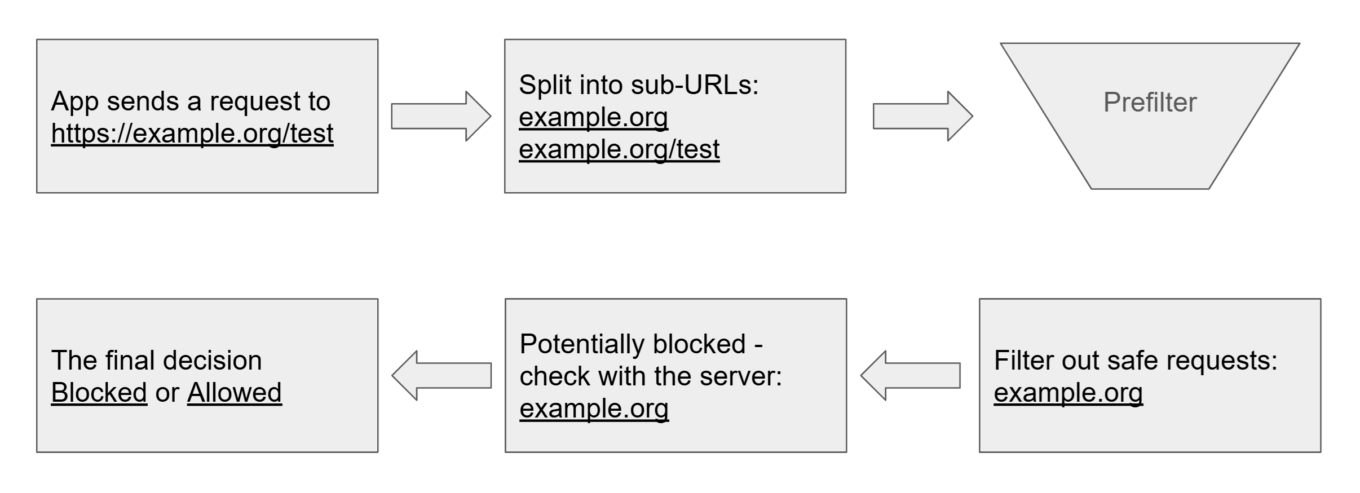
Apples URL-Filter: Überblick auf hoher Ebene — Filterung
Das System zerlegt die URL in mehrere Teil-URLs.
Diese werden zunächst mit einem lokalen Vorfilter abgeglichen, um schnell zu entscheiden, welche URLs als unbedenklich gelten.
Die verbleibenden URLs werden anschließend zur weiteren Prüfung an den entfernten Server gesendet.
Auf Basis der Serverantwort entscheidet das System schließlich, ob die Anfrage zugelassen oder blockiert wird.
An dieser Stelle lässt sich leicht erkennen, wie eine naive Umsetzung schnell zu einem Albtraum für den Datenschutz werden könnte. Um dem vorzubeugen, hat Apple mehrere durchdachte Designentscheidungen getroffen, die den Schutz der Privatsphäre gewährleisten und gleichzeitig eine effektive Filterung ermöglichen.
Die gesamte URL-Filter-API basiert auf mehreren modernen Datenschutztechnologien.
Zunächst kommt Privacy Pass zum Einsatz, das für die Authentifizierung genutzt wird.
Danach folgt Private Information Retrieval (PIR), das für Serverabfragen verwendet wird. Ergänzt wird es durch einen Bloom-Filter, der als lokaler Vorfilter dient.
Und schließlich wird Oblivious HTTP eingesetzt.
All diese Technologien sind noch relativ neu und hochmodern. Umso spannender ist es zu sehen, dass Apple sie nicht nur einsetzt, sondern in ein reales System integriert hat. Im nächsten Schritt schauen wir uns die einzelnen Komponenten genauer an und erklären, wie sie zusammenspielen.
Privacy Pass
Die erste Komponente ist Privacy Pass. Dabei handelt es sich um ein modernes Authentifizierungssystem mit starkem Fokus auf Datenschutz. Es ermöglicht es Clients, anonyme Tokens zu erhalten, mit denen sich die Berechtigung nachweisen lässt — ohne Identität oder Nutzungsverhalten offenzulegen.
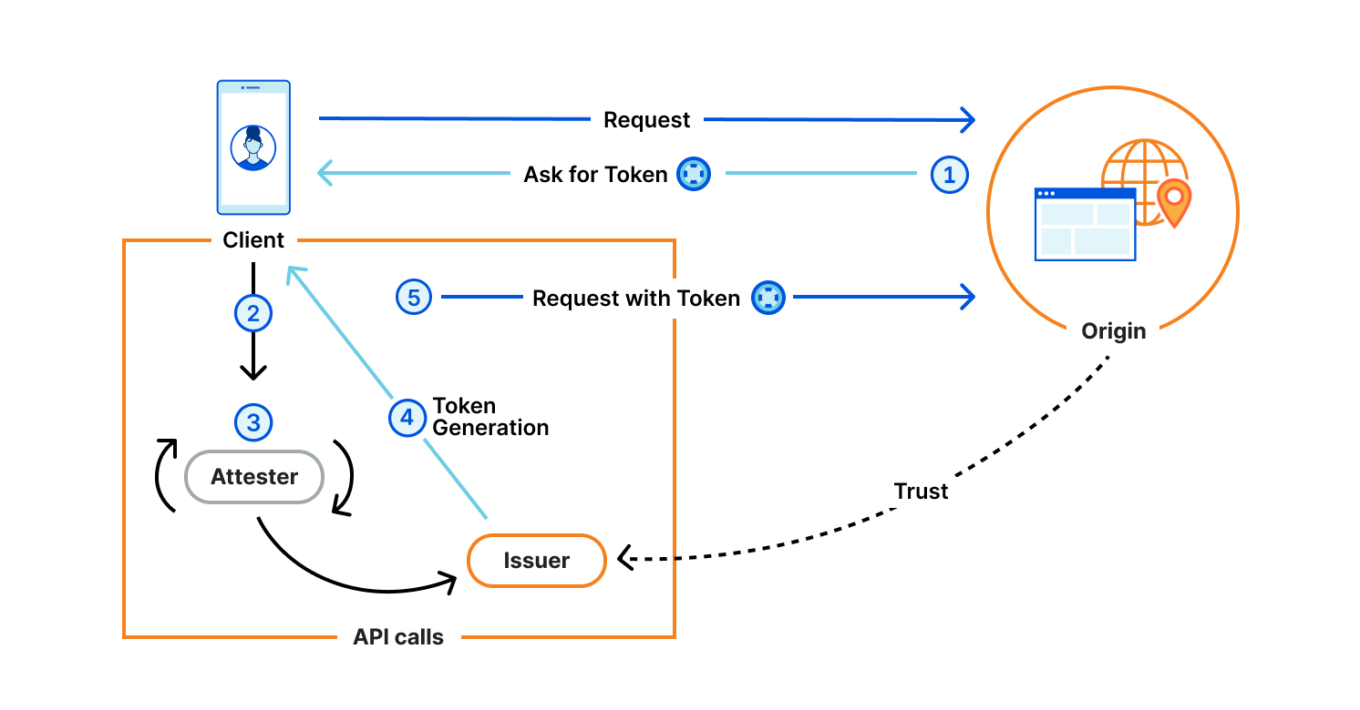
Privacy-Pass-Ablaufdiagramm. Quelle: Cloudflare Blog
Wie im Diagramm dargestellt:
Wenn ein Client eine Anfrage an den Origin-Server sendet, kann er ein gültiges Token anfordern.
Der Client wendet sich an einen Attester, um seine Berechtigung bestätigen zu lassen. Nach erfolgreicher Prüfung stellt ein Issuer ein Privacy-Pass-Token aus.
Der Client übermittelt dieses Token an den Origin, der es mithilfe der öffentlichen Schlüssel des Issuers überprüft und die Anfrage akzeptiert.
Die zentrale Datenschutzidee dahinter ist die Trennung der Rollen: Bleiben Origin und Issuer voneinander unabhängig, bleibt die Authentifizierung anonym. Der Server weiß dann, dass das Token gültig ist, aber nicht, wer dahintersteht. So funktioniert Privacy Pass in der Theorie — schauen wir uns nun an, wie Apple diesen Ansatz in der Praxis umsetzt.
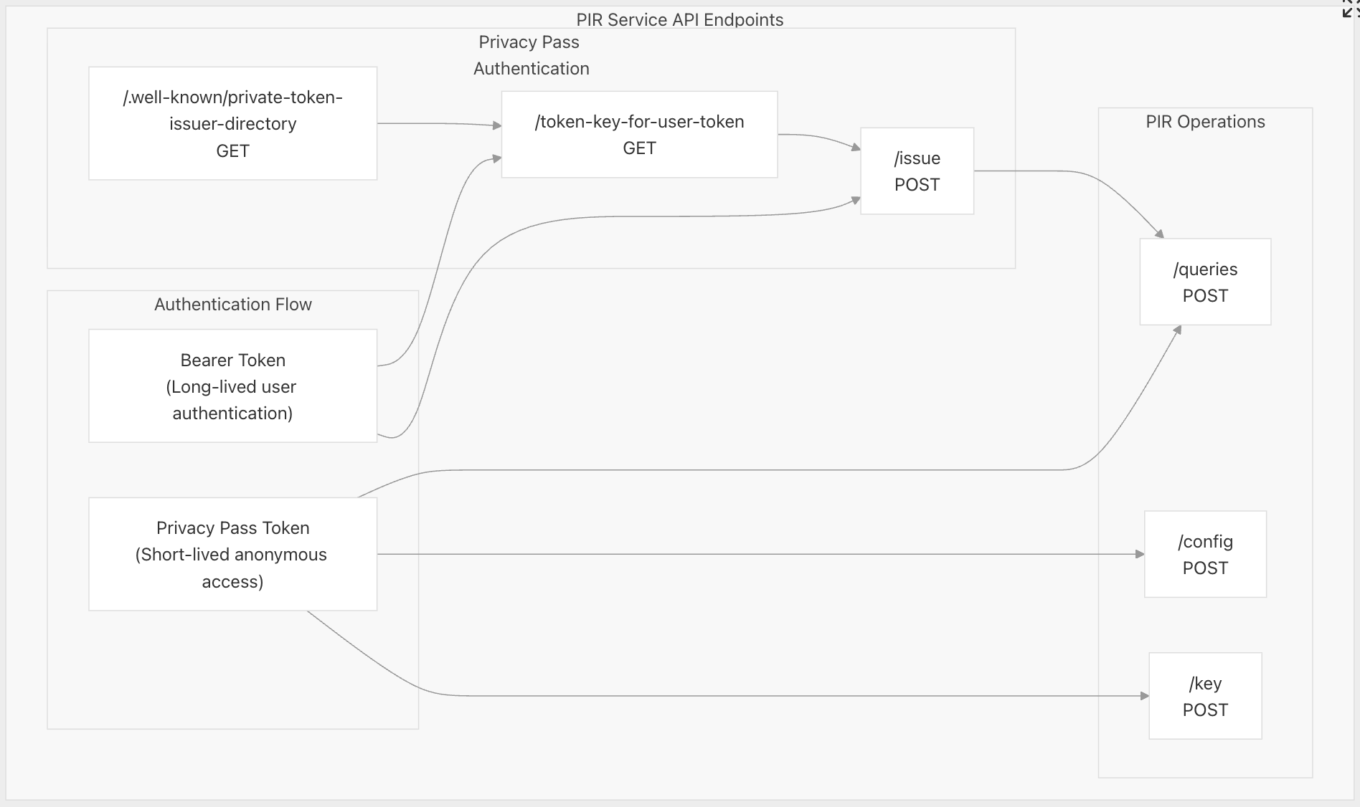
Privacy Pass — Apples PIR
Zunächst authentifiziert sich der Client über eine dauerhafte Kennung (etwa ein Benutzerkonto), um kurzlebige Privacy-Pass-Tokens zu erhalten.
Für jede PIR-Anfrage wird eines dieser Tokens eingelöst, um die Berechtigung nachzuweisen.
Das ähnelt auf den ersten Blick dem ursprünglichen Konzept. Der entscheidende Unterschied liegt jedoch darin, dass in Apples System sowohl der Issuer als auch der Origin — also der PIR-Dienst — zur gleichen Partei gehören, nämlich zum Entwickler. Da beide Komponenten unter derselben Kontrolle stehen, können Tokens potenziell mit einzelnen Personen verknüpft werden. Die tatsächliche Anonymität hängt damit vollständig von der konkreten Implementierung durch den Entwickler ab.
Im nächsten Abschnitt richten wir den Fokus auf PIR, also Private Information Retrieval.
Private Information Retrieval (PIR)
Vereinfacht gesagt ist PIR eine Familie kryptografischer Protokolle, die es einem Client ermöglichen, Daten von einem Server abzurufen, ohne dass der Server erfährt, welches konkrete Element abgefragt wurde. Die Grundidee ist nicht neu — sie wird bereits seit den 1990er-Jahren erforscht. Ein frühes und bis heute weit verbreitetes Beispiel für ein PIR-ähnliches System ist Google SafeBrowsing, das vor rund 20 Jahren eingeführt wurde. Es folgt einem ähnlichen Prinzip, kommt jedoch ohne aufwendige Kryptografie aus.
Apples Umsetzung von Private Information Retrieval ist deutlich komplexer — es handelt sich um ein echtes, kryptografisch abgesichertes Design mit starkem Fokus auf Datenschutz. Auf hoher Ebene funktioniert es folgendermaßen:
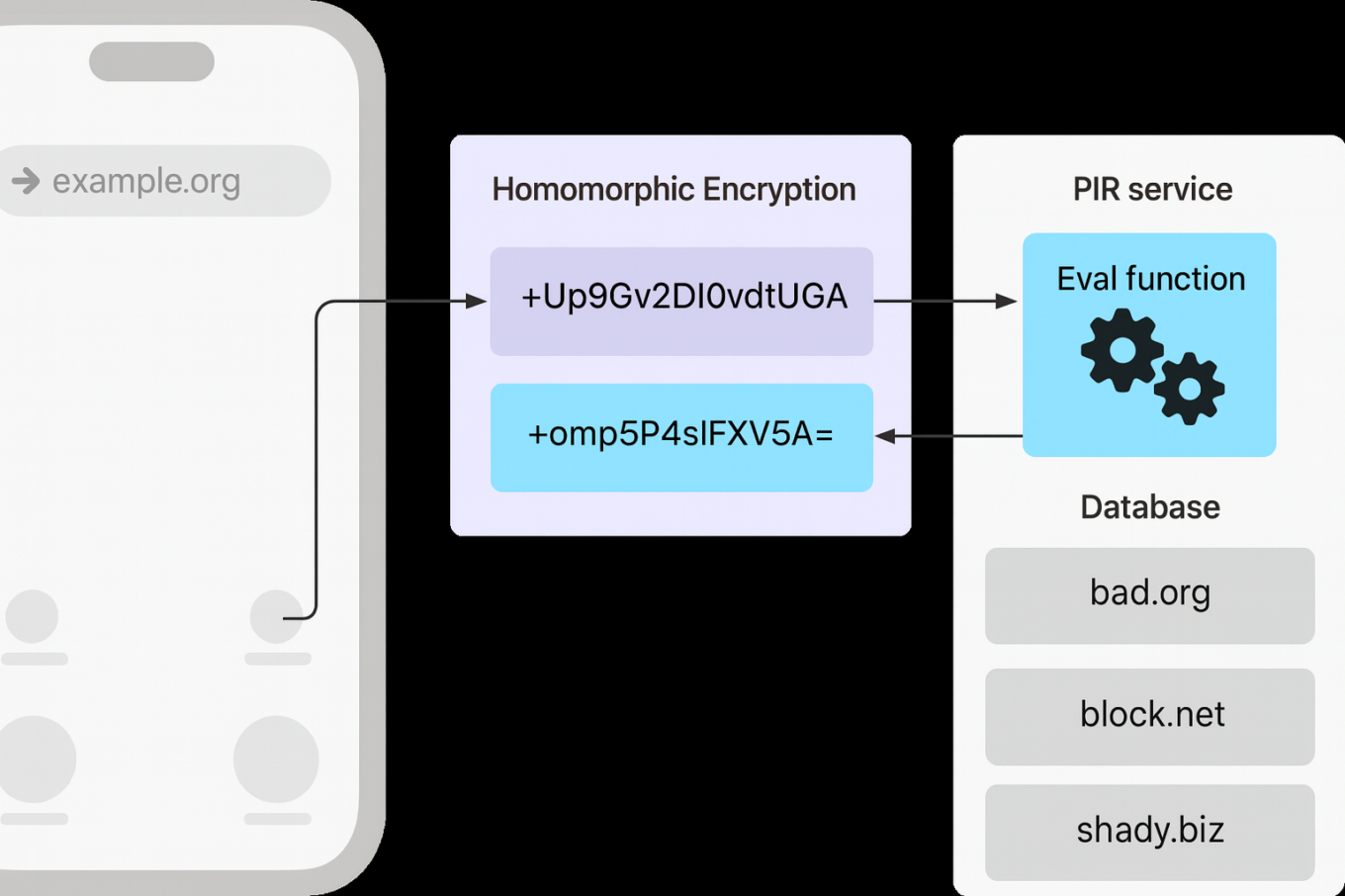
Apples PIR-Implementierung
Der Server bereitet eine Datenbank vor — im Wesentlichen eine Hash-Tabelle — in der jeder Eintrag verschlüsselt und indexiert ist.
Anschließend veröffentlicht er eine Konfiguration, die beschreibt, wie Clients mit dem Dienst interagieren sollen: die Struktur der Hash-Tabelle, Verschlüsselungsparameter und weitere Metadaten.
Möchte ein Client eine bestimmte URL überprüfen, ermittelt er den passenden Index in dieser Hash-Tabelle.
Danach erstellt der Client eine Anfrage nach dem Muster „Ich möchte Element X“, verschlüsselt diese jedoch so, dass der Server nicht erkennen kann, wofür X steht.
Der Server verarbeitet diese verschlüsselte Anfrage mithilfe homomorpher Verschlüsselung und erzeugt eine ebenfalls verschlüsselte Antwort, die mehrere mögliche Einträge enthält.
Der Client entschlüsselt die Antwort lokal und prüft, ob sich X unter den Ergebnissen befindet.
Wird X gefunden, wird die Anfrage als blockiert markiert.
Private-Information-Retrieval-Lösung — das angestrebte Ziel wird damit grundsätzlich erreicht.
Doch sprechen wir über die Performance. Apples PIR-System ist vergleichsweise ressourcenintensiv:
- Jede Abfrage kann rund 30 KB groß sein — für einen einzelnen API-Request ist das ziemlich viel.
- Selbst unter idealen Bedingungen kann eine einzelne Abfrage mehr als 100 Millisekunden dauern.
Wie zu erwarten, werden einzelne Abfragen langsamer, je größer die Datenbank ist. Um dieses Problem zu lösen, unterstützt Apples PIR-API sogenanntes Sharding — also das Aufteilen der Hauptdatenbank in kleinere Teile. Der Server definiert mehrere Shards. Bei der Überprüfung einer URL berechnet der Client anhand einer Funktion, zu welchem Shard sie gehört, und übermittelt diese Information mit der Anfrage.
Das beschleunigt die Abfragen, bringt aber ein potenzielles Datenschutzproblem mit sich: Gibt es sehr viele Shards, kann ein einzelner Shard im Extremfall nur noch einer einzigen URL entsprechen. In diesem Fall ließe sich erkennen, welche URL geprüft wird.
Lässt sich dieses Risiko verringern? Meiner Meinung nach ja. Apple könnte dem entgegenwirken, indem beispielsweise eine Mindestgröße für Shards oder eine maximale Anzahl von Shards festgelegt wird. Hoffentlich wird dieser Aspekt künftig berücksichtigt. Doch selbst Sharding reicht nicht aus, wenn der Client jede einzelne URL an den Server senden muss. Deshalb hat Apple einen weiteren Optimierungsschritt eingeführt — einen Vorfilter, genauer gesagt einen Bloom-Filter.
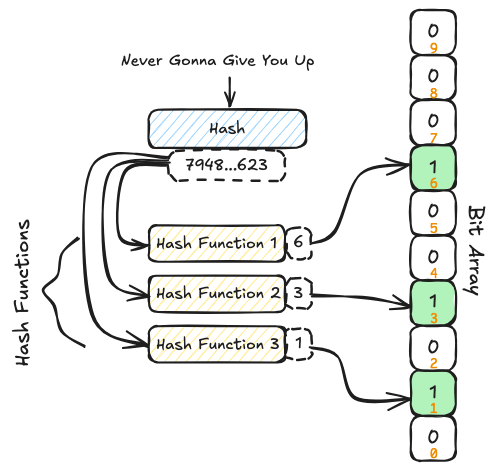
Bloom-Filter-Diagramm. Quelle: bytedrum.com
Ohne zu sehr ins Detail zu gehen, sind dafür vor allem folgende Punkte wichtig:
Bloom-Filter sind sehr schnell und benötigen wenig Speicherplatz.
Sie beantworten im Kern eine einzige Frage: „Ist diese URL im Datensatz enthalten?“
Die möglichen Antworten sind:
definitiv nicht
möglicherweise ja (das heißt, die URL könnte auf der Blockliste stehen und sollte per PIR noch einmal überprüft werden)
Das Ergebnis: Der Großteil aller Abfragen verlässt das Gerät gar nicht erst.
Oblivious HTTP
Die letzte Komponente der URL-Filter-API ist Oblivious HTTP. Zur kurzen Einordnung: Privacy Pass sorgt für anonyme Authentifizierung, PIR verbirgt die eigentliche Anfrage, und OHTTP entfernt schließlich den letzten eindeutigen Identifikator — die IP-Adresse. Dazu trennt Oblivious HTTP Client und Server mithilfe von vier beteiligten Parteien:
- Client (das Gerät)
- Relay (Apple)
- Gateway (der Entwickler)
- Target (der eigentliche Dienst, also PIR oder Privacy Pass)
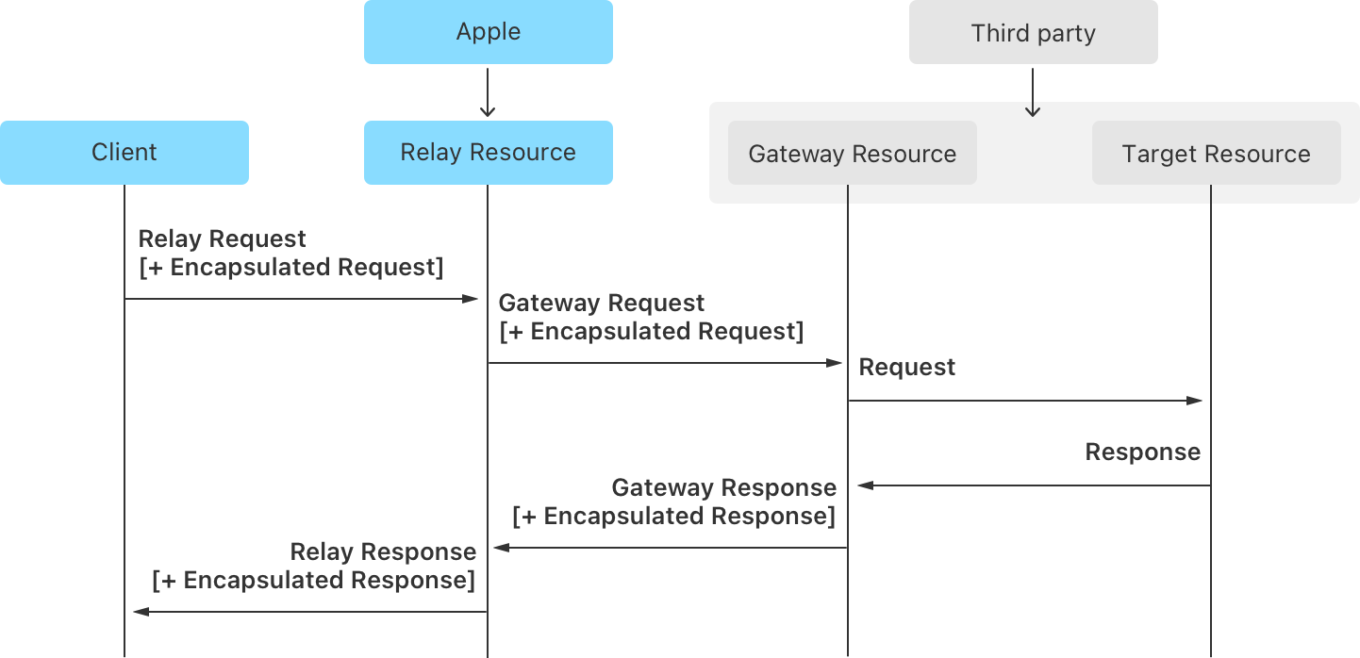
Oblivious HTTP in Apples PIR
Der Client verschlüsselt die Anfrage für das Gateway und sendet sie über das Relay, das die Daten lediglich weiterleitet. Das Gateway entschlüsselt und verarbeitet die Anfrage, verschlüsselt die Antwort und sendet sie anschließend wieder über das Relay zurück an den Client. Die Grundidee dabei: Das Relay weiß, von wem die Anfrage stammt, kennt aber deren Inhalt nicht. Das Gateway sieht die Anfrage, hat jedoch keine Informationen über die Person dahinter.
Doch selbst wenn technisch alles funktioniert, bleibt noch ein letzter Schritt — der Prüfprozess von Apple. Bevor eine App die neue API nutzen darf, müssen sowohl der eigene PIR-Dienst als auch das Oblivious-HTTP-Gateway von Apple geprüft und freigegeben werden. Darauf sollte man vorbereitet sein: Dieser Prozess kann durchaus einige Zeit in Anspruch nehmen. Wer die API fest einplant, sollte das frühzeitig berücksichtigen.
Zusammenfassung
Wie gut ist also Apples URL-Filter? Im ersten Abschnitt habe ich eine Reihe von Eigenschaften beschrieben, die eine ideale systemweite Filterlösung erfüllen sollte. Nun lohnt es sich, diese Punkte noch einmal aufzugreifen und zu prüfen, wie Apples neue URL-Filter-API im Vergleich abschneidet.
✅ Vollständige URL-Filterung
Hier gibt es nichts zu diskutieren — dieser Punkt ist erfüllt.
🚫 Umfangreiche Filterfunktionen
Leider fällt dieser Punkt durch. Apples System erlaubt es, Anfragen zu blockieren — und das war es im Wesentlichen auch schon. Darüber hinaus gibt es mehrere wichtige Einschränkungen:
Einzelne Domains lassen sich nicht gezielt freigeben. Es gilt immer alles oder nichts: Entweder ist die gesamte Blockliste aktiv oder sie ist komplett deaktiviert.
Ein Wechsel zwischen mehreren Blocklisten ist nicht möglich. Jede App kann nur eine einzige Liste bereitstellen.
Theoretisch gibt es Umgehungslösungen, diese wirken jedoch eher wie Notbehelfe als wie saubere Lösungen.
✅ Unterstützung sehr großer Blocklisten
Hier gibt es ein klares Häkchen. Die API wurde von Anfang an für sehr große Blocklisten ausgelegt.
✅ Schnelle Updates der Blocklisten
Auch in diesem Punkt schneidet Apple gut ab. Die API unterstützt automatische Updates, wobei das minimale Update-Intervall bei 45 Minuten liegt — ein durchaus guter Wert.
❔ Datenschutz von Grund auf
Dieser Punkt ist etwas komplexer. Für mich bedeutet „Datenschutz von Grund auf“, dass bei der Nutzung dieser API vollständige Anonymität gewährleistet ist und es keine Möglichkeit gibt, Rückschlüsse auf einzelne Personen zu ziehen. Genau das ist auch Apples erklärtes Ziel: Die gesamte Architektur ist darauf ausgelegt, die Privatsphäre zu schützen. In der Praxis sehe ich jedoch einige potenzielle Schwachstellen, über die sich Nutzeraktivitäten theoretisch doch wieder zuordnen ließen. Hoffentlich wird Apple diese Punkte in zukünftigen Versionen adressieren und die Anonymitätsgarantien weiter stärken.
🚫 Rückmeldungen durch die API
Bietet die API dem Entwickler irgendwelche Rückmeldungen darüber, wie sie tatsächlich arbeitet? Die Antwort lautet leider: nein. Es gibt keinerlei Feedback. Die App erfährt weder, ob eine Anfrage blockiert wurde, noch ob eine bestimmte URL überhaupt geprüft wurde. Kurz gesagt: Das System ist eine vollständige Blackbox.
🚫 Debugging-Tools
Ebenso fehlen integrierte Tools, mit denen sich nachvollziehen ließe, was intern passiert. Und wie man sich vorstellen kann, ist die Fehlersuche bei einem URL-Filter unter diesen Umständen äußerst schwierig.
✅✅✅ Trotz all der genannten Einschränkungen möchte ich mit einem positiven Fazit schließen. Diese API ist um ein Vielfaches besser, als überhaupt keine systemweite Filtermöglichkeit zu haben. Sie stellt einen großen Schritt nach vorn dar — und ist der erste ernsthafte Versuch eines Betriebssystemherstellers, systemweite Filterung sowohl sicher als auch datenschutzfreundlich umzusetzen. Dafür gebührt Apple Anerkennung. Das System ist noch nicht perfekt, aber es ist ein sehr vielversprechender Anfang, und ich bin gespannt, wie es sich in Zukunft weiterentwickelt.
Abschließend möchte ich erwähnen, dass wir eine eigene PIR-Implementierung entwickelt haben, die sich derzeit bei Apple im Prüfprozess befindet — inzwischen seit über einem Monat. Ich hoffe sehr, dass sie bald freigegeben wird und wir diese Funktionalität in AdGuard-Produkten einsetzen können.
Wenn Sie mit Apples PIR-System experimentieren möchten, können die folgenden Tools und Ressourcen den Einstieg erleichtern:
- PIR-Dienst + Privacy Pass: Apple stellt eine Beispielimplementierung für PIR- und Privacy-Pass-Dienste bereit. Sie ist nicht für den produktiven Einsatz gedacht, eignet sich aber hervorragend, um zu verstehen, wie die einzelnen Komponenten zusammenspielen.
- Testen von PIR und Privacy Pass: Um Tests zu vereinfachen, habe ich ein kleines Kommandozeilen-Tool entwickelt, mit dem sich der Ablauf von PIR und Privacy Pass simulieren lässt. Es ist Open Source und auf GitHub verfügbar.
- Bloom-Filter: Apple hat keinen offiziellen Code für die Erstellung von Bloom-Filtern veröffentlicht, und die Dokumentation war anfangs recht vage. Deshalb habe ich eine Swift-Bibliothek erstellt, mit der sich Bloom-Filter erzeugen lassen, die vollständig mit Apples URL-Filter-API kompatibel sind.
- Oblivious-HTTP-Gateway: Für Oblivious HTTP stellt Cloudflare sowohl eine Referenzbibliothek als auch eine sofort einsatzbereite Serverimplementierung zur Verfügung.
- GoCurl — Testen von Oblivious HTTP: Wenn Sie Ihre OHTTP-Konfiguration testen möchten, kann GoCurl helfen — ein langjähriges Nebenprojekt von mir. Es handelt sich um eine Go-basierte Neuimplementierung von curl mit zusätzlichen Funktionen, darunter integrierte Unterstützung für Oblivious HTTP.















































