Mit LLMs gegen Werbung: Ein neuer Ansatz ohne Filterlisten
Eines der größten Hindernisse, mit denen Werbeblocker seit jeher zu kämpfen haben, hängt direkt mit ihrem Grundprinzip zusammen: den Einschränkungen von Filterlisten und dem ständigen Aufwand, sie aktuell zu halten. In den meisten Fällen passiert diese Pflege manuell — und sie ist mühsam, zeitaufwendig und fehleranfällig.
In dieser Analyse schauen wir uns an, wie Werbeblockierung heute funktioniert und welche früheren Versuche es gab, diesen Prozess mithilfe von Machine Learning zu automatisieren. Danach stellen wir unsere eigenen Experimente vor, bei denen ein LLM zum Einsatz kommt, zeigen, wohin dieser Ansatz führen könnte, und präsentieren sogar eine funktionierende Prototyp-Erweiterung, die Sie selbst herunterladen und testen können.
Wir wissen: Wahrscheinlich möchten Sie direkt zu den LLM-Experimenten springen und die Erweiterung ausprobieren — aber bevor wir dort einsteigen, schaffen wir erst ein bisschen Kontext.
Wie Werbeblockierung heute funktioniert
Im Kern aller Werbeblocker stehen Filterlisten, die von der Community gepflegt werden. Diese Listen bestehen aus Tausenden von Regeln, die in zwei Hauptkategorien fallen: Netzwerkregeln und kosmetische Regeln.
Netzwerkregeln: Die erste Verteidigungslinie
Was sie tun: Anfragen blockieren, umleiten oder verändern.
Beispiel:||evil-ads.com^. Diese Regel blockiert evil-ads.com und alle zugehörigen Subdomains.
Netzwerkregeln verhindern, dass Anfragen zu externen Werbeservern überhaupt im Browser ankommen — ein schneller und sehr effektiver Ansatz. Sie können Anfragen blockieren, umleiten oder anpassen.
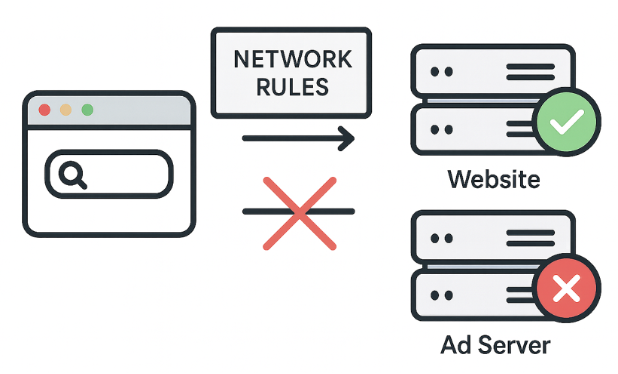
Allerdings lassen sich nicht alle Werbeelemente auf diese Weise blockieren. Manche Anzeigen werden direkt über dieselbe Domain ausgeliefert wie der eigentliche Seiteninhalt. Eine Blockierung auf Netzwerkebene würde in solchen Fällen die ganze Seite beschädigen. Genau hier kommen die kosmetischen Regeln ins Spiel.
Kosmetische Regeln: Die Seite aufräumen
Was sie tun: Mithilfe von CSS-Selektoren störende Elemente direkt auf der Seite ausblenden oder eigene Styles anwenden.
Beispiel:example.com##.ad-banner. Diese Regel blendet auf example.com alle Elemente mit der Klasse „ad-banner“ aus.
CSS (Cascading Style Sheets) ist eine Gestaltungssprache, die festlegt, wie HTML- oder XML-Dokumente dargestellt werden. Sie bestimmt also, wie Elemente auf dem Bildschirm erscheinen sollen.
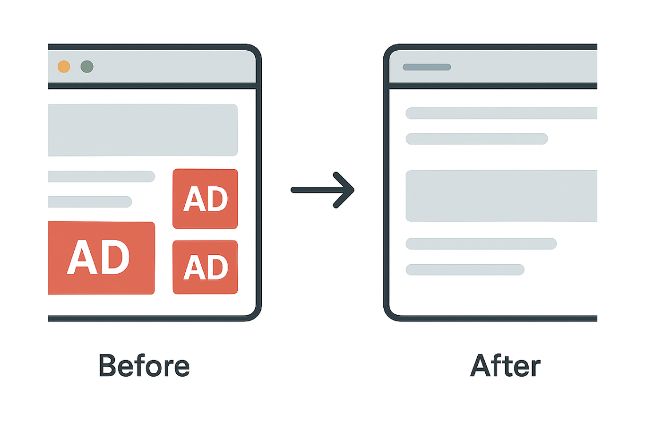
Kosmetische Regeln entfernen im Grunde die Reste von Werbeelementen, die sich mit reinen Netzwerkregeln nicht zuverlässig blockieren lassen.
Mehr als nur CSS: Scriptlet-Regeln
Was sie tun: Bestimmte Skriptfunktionen auf der Seite ändern oder deaktivieren.
Beispiel:example.com#%#//scriptlet('abort-on-property-read', 'alert'). Damit wird ein Skript auf example.com gestoppt, sobald es versucht, auf eine bestimmte Browserfunktion wie alert zuzugreifen.
Wenn CSS nicht ausreicht — etwa bei komplexen Skripten oder Mechanismen zur erneuten Werbeeinblendung — kommen Scriptlets ins Spiel. Scriptlets sind kleine JavaScript-Bausteine, die der Werbeblocker in die Seite einfügt, um unerwünschtes Verhalten zu neutralisieren.
Für viele Filterentwickler sind Scriptlets inzwischen zum Lieblingswerkzeug geworden, weil sie Probleme lösen können, bei denen CSS und Netzwerkregeln keine Chance haben.
Stärke und Grenzen
Wir haben uns kurz angesehen, wie Filterlisten funktionieren. Sie sind sehr leistungsfähig und funktionieren hervorragend, solange es um bekannte Muster geht. Gleichzeitig haben sie aber klare Grenzen: Native Ads, ständige Aktualisierungen — und mit Manifest v3 wird genau diese Pflege noch komplizierter.
Diese Grenzen führen zu einer grundlegenden Frage: Was wäre, wenn man komplett ohne Filterlisten auskommen könnte? Was wäre, wenn ein Werbeblocker selbst entscheiden könnte, was blockiert werden soll?
Stellen Sie sich vor: keine Filter, keine Updates, kein Hinterherjagen neuer Werbenetzwerke. Keine manuellen Anpassungen, kein endloses Katz-und-Maus-Spiel. Am Ende ist es doch genau das, was viele von einem Werbeblocker erwarten: einmal installieren und nicht mehr darüber nachdenken, während das Web sauber bleibt.
Genau dieses Ziel hatten die ersten Machine-Learning-Ansätze im Blick.
Und mit diesem Gedanken im Hinterkopf schauen wir uns an, wie Unternehmen und Forschungseinrichtungen versucht haben, diese Probleme mithilfe von Machine Learning zu lösen.
Ein kurzer Blick auf die Geschichte von Machine Learning im Adblocking
Werfen wir einen Blick zurück auf frühere Versuche, Filterlisten durch Machine Learning zu ersetzen. Das hilft zu verstehen, warum es bisher nicht dazu gekommen ist.
Project Moonshot von eyeo
Ziel: Kosmetisches Filtern in großem Umfang automatisieren.
Ansatz:
- Ein ML-Modell wurde auf Basis der Seitenstruktur trainiert (DOM, HTML, CSS)
- Bestehende Filterlisten dienten als Grundlage für die Kennzeichnung
- Die Analyse fand direkt in der Browsererweiterung statt
Project Moonshot wurde bereits 2021 auf dem Ad-Filtering Dev Summit vorgestellt. Die Idee war, ein Modell zu trainieren, das anhand der Seitenstruktur erkennt, welche Elemente Werbung sind — ganz ohne Bilderkennung. Die Erweiterung sollte diese Elemente dann automatisch ausblenden.
Der Ansatz funktionierte grundsätzlich, brachte aber einige Schwierigkeiten mit sich: unausgewogene Daten, aufwendige Bereitstellung und die Notwendigkeit, das Modell ständig neu zu trainieren.
Kernidee: Entscheidungen basieren auf der Struktur einer Seite — nicht auf Bildern.
Ergebnis: Das Modell konnte Werbeelemente erkennen und ausblenden und damit die Netzwerkblockierung ergänzen.
Herausforderungen: Ungleich verteilte Daten, komplizierte Auslieferung und dauerhafter Bedarf an Retraining.
AdGraph von Brave
Ziel: Werbung und Tracker in Echtzeit blockieren.
Ansatz:
- Ein Graph wurde erstellt, der alle Aktivitäten einer Seite miteinander verknüpft (DOM, Netzwerk, JavaScript)
- Inhalte wurden anhand ihres Kontexts innerhalb dieses Graphen klassifiziert
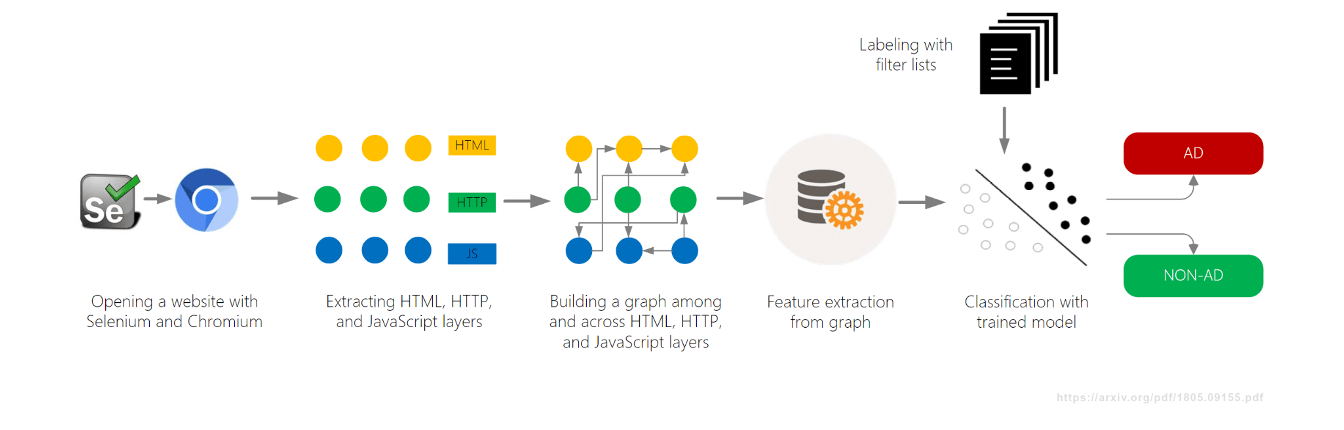
Ein weiteres Machine-Learning-Projekt, AdGraph, wurde vom Brave Browser entwickelt und bereits 2019 auf dem AFDS vorgestellt. Die Idee: einen umfassenden Graphen aufzubauen, der zeigt, wie jedes Element einer Seite miteinander verbunden ist — vom DOM über Netzwerkaufrufe bis hin zu JavaScript-Aktivitäten. Auf Basis dieses Kontexts wurden dann Entscheidungen getroffen, was blockiert werden sollte.
AdGraph erreichte eine sehr hohe Genauigkeit, da es Skripte selbst dann zuverlässig zuordnen konnte, wenn sie zufällige oder verschleierte Namen hatten. Allerdings benötigte das System eine tiefgehende Integration in den Browser und damit auch laufende Pflege.
Kernidee: Entscheidungen basieren auf Ursache-Wirkungs-Beziehungen statt nur auf statischen URL-Mustern.
Ergebnis: Sehr hohe Genauigkeit (ca. 95–98%) und widerstandsfähig gegen Verschleierung.
Herausforderungen: Benötigte tiefgehende Browser-Integration und kontinuierliche Wartung.
PERCIVAL von Brave
Ziel: Werbebilder in Echtzeit blockieren.
Ansatz:
- Einsatz eines kompakten neuronalen Netzes (CNN) zur Bildklassifizierung
- Direkte Einbettung in die Rendering-Pipeline des Browsers
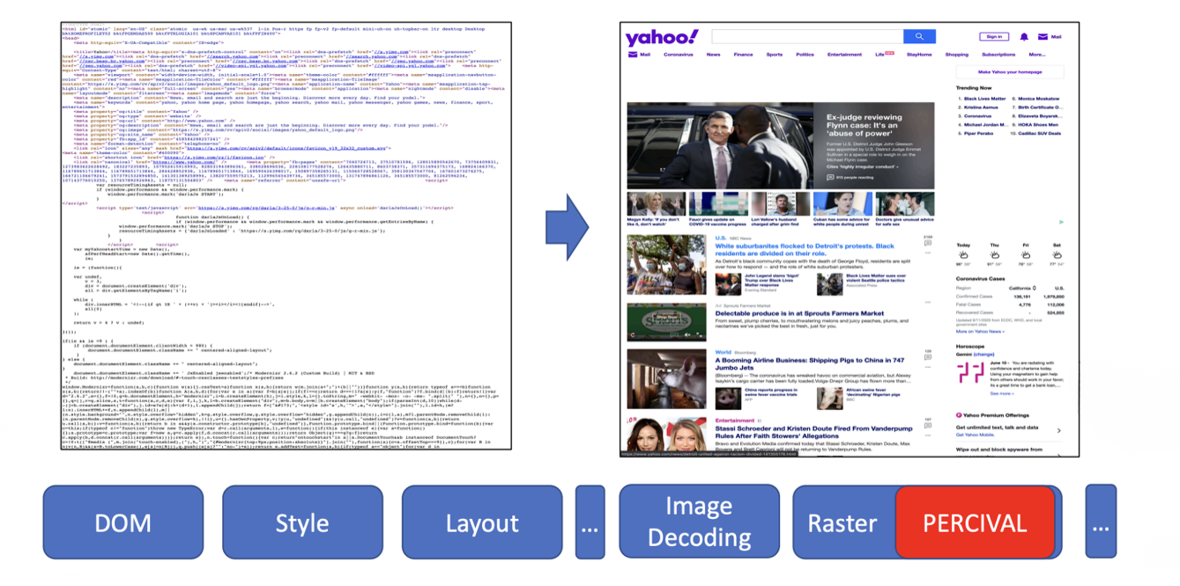
Im Jahr 2020 stellte Brave einen weiteren Machine-Learning-Ansatz vor: PERCIVAL. Dieses Projekt konzentrierte sich speziell auf Werbebilder. Dazu wurde ein kompaktes neuronales Netz direkt in die Rendering-Pipeline integriert, sodass jedes Bild bereits beim Laden analysiert und eingestuft werden konnte.
Die Ergebnisse waren beeindruckend: Rund 97% Genauigkeit, basierend auf der Analyse des tatsächlichen Bildinhalts. Gleichzeitig gab es aber auch klare Grenzen — das System war anfällig für manipulierte („adversarial“) Bilder und funktionierte ausschließlich bei bildbasierten Anzeigen.
Kernidee: Nicht die URL oder Metadaten auswerten, sondern den visuellen Inhalt selbst.
Ergebnis: Rund 97% Genauigkeit bei minimalem Einfluss auf die Renderleistung.
Herausforderungen: Anfällig gegenüber manipulierten Bildern und nur für bildbasierte Werbung geeignet.
AutoFR (wissenschaftliche Forschung)
Ziel: Filterregeln automatisch von Grund auf erzeugen.
Ansatz:
- Einsatz von Reinforcement Learning (Versuch-und-Irrtum-Prinzip), um Regeln zu testen
- Analyse des Seiteninhalts, um Fehler oder beschädigte Seiten zu vermeiden
Neben Projekten aus der Industrie gab es auch Forschungsteams, die nach neuen Wegen suchten. Ein besonders interessantes Beispiel ist AutoFR, ein Ansatz zur vollständig automatischen Erstellung von Filterregeln.
AutoFR wurde von Hieu Van Le auf dem AFDS 2022 und später erneut auf dem AFDS 2023 vorgestellt.
Das System erzeugt URL-Muster und CSS-Selektoren, testet sie, lernt aus den Ergebnissen und achtet gleichzeitig darauf, die Seite nicht zu beschädigen. Die Resultate waren bemerkenswert: AutoFR erreichte rund 86% Wirksamkeit im Vergleich zu EasyList — und das bei Regeln, die innerhalb weniger Minuten erstellt wurden.
Kernidee: Automatische Regelerstellung mit besonderem Augenmerk darauf, dass die Seite funktionsfähig bleibt.
Ergebnis: Rund 86% Blockierleistung; Regeln entstehen innerhalb von Minuten.
SINBAD (wissenschaftliche Forschung)
Ziel: Fehler erkennen, die durch Werbeblockierung auf Webseiten entstehen.
Ansatz:
- Analyse der „Web-Salienz“, um wichtige visuelle Elemente zu identifizieren
- Vergleich von Seitenversionen mit und ohne Werbeblocker, um herauszufinden, was kaputtgeht
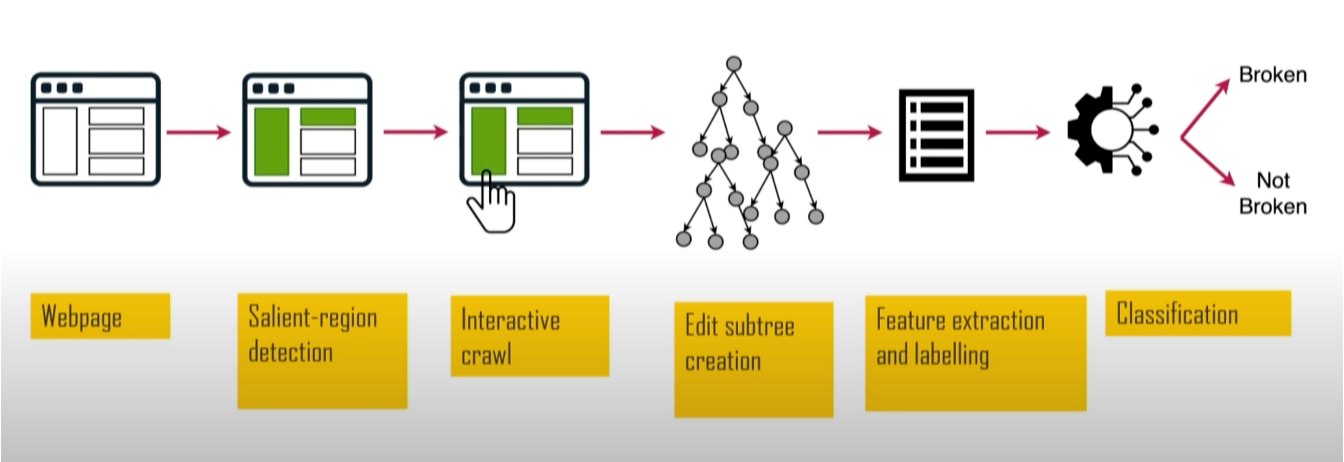
Ein weiteres Forschungsprojekt war SINBAD. Der Schwerpunkt lag darauf, zu erkennen, wann und wodurch Filterregeln eine Website beschädigen. Das ist besonders wichtig, denn genau solche Probleme sind einer der Hauptgründe, warum viele Menschen Werbeblocker wieder deinstallieren. Vorgestellt wurde das Projekt 2023 auf dem AFDS von Sandra Siby vom Imperial College London.
SINBAD analysiert Größe, Position und Kontrast von Elementen und erkennt dadurch Bereiche, die für die Orientierung besonders wichtig sind — zum Beispiel Überschriften oder Buttons. Anschließend wird geprüft, ob diese Elemente durch Filterregeln beeinträchtigt wurden. Das System liefert sehr genaue Ergebnisse und zeigt sogar konkret, welches Element betroffen ist und welche Regel das Problem ausgelöst hat.
Kernidee: Sich auf das konzentrieren, was für Menschen sichtbar und relevant ist — so lassen sich Probleme schneller finden und beheben.
Ergebnis: Hohe Genauigkeit bei der Erkennung von Fehlern und klare, nachvollziehbare Berichte.
Zusammenfassung: Warum sich ML nicht durchgesetzt hat
Wir haben nun verschiedene Experimente und Forschungsansätze gesehen. Doch trotz all dieser Arbeit hat sich keiner der Machine-Learning-Ansätze wirklich durchgesetzt. Die naheliegende Frage lautet also: Warum hat Machine Learning die klassischen Filter nicht ersetzt?
Dafür gibt es mehrere Gründe:
- Hohe Messlatte: Von Menschen gepflegte Filterlisten sind unglaublich effektiv und seit vielen Jahren erprobt. Ihre Qualität zu erreichen, ist alles andere als einfach.
- Hoher Aufwand: Große und gut gepflegte Datensätze zu erstellen und aktuell zu halten, ist teuer. Filterlisten entstehen dagegen größtenteils in mühevoller Community-Arbeit — kostenlos.
- Umgehung: Spezialisierte Modelle können anfällig für gezielte Manipulationen sein.
Kurz gesagt: Spezielle Modelle komplett neu aufzubauen ist teuer, langsam und wenig flexibel. Deshalb hat sich der ML-Ansatz bisher nicht durchgesetzt — und wir verlassen uns weiterhin auf die klassischen Filterlisten.
Aber: Steht hier vielleicht ein Wandel bevor?
LLMs betreten die Bühne: Groß, teuer … aber anders
Und dann kamen die Large Language Models (LLMs) — und stellen seither so ziemlich alles auf den Kopf. Können sie vielleicht auch das Adblocking verändern?
Schauen wir uns an, wie LLMs in Browsererweiterungen eingesetzt werden könnten.
Doch bevor wir einsteigen, werfen wir kurz einen Blick auf einige Eigenschaften, die LLMs ausmachen.
Wie LLMs schnelles Prototyping möglich machen
Large Language Models (LLMs) sind zwar noch eine relativ junge Technologie, doch ihre Entwicklung schreitet rasant voran. Heute stehen sie über APIs sehr leicht zugänglich zur Verfügung, sodass sich LLM-basierte Funktionen mit wenig Aufwand in Produkte integrieren lassen. Viele Modelle gibt es sowohl als Cloud-Variante als auch zur lokalen Ausführung — je nachdem, was besser passt.
LLMs können erstaunlich viel: Texten und Daten analysieren, Bilder und Videos erzeugen, Code schreiben und sogar komplexe Arbeitsabläufe unterstützen. Dadurch sind sie in zahlreichen Branchen gefragt — und werden täglich von Millionen Menschen genutzt.
Allerdings hat die Sache auch eine Kehrseite: Der Betrieb oder Zugriff auf solche Modelle kann teuer werden, besonders im großen Maßstab. Das ist einer der wichtigsten Gründe, warum LLMs nicht überall sofort übernommen werden.
Der entscheidende Vorteil ist jedoch: LLMs ermöglichen extrem schnelles Ausprobieren von Ideen. Und genau deshalb können wir jetzt einen Blick auf unsere ersten Experimente werfen — wie sich LLMs direkt in Browsererweiterungen für Werbeblockierung einsetzen lassen.
Experiment 1: Blockieren nach Bedeutung
Die Idee hinter dem ersten Experiment war simpel: Kann ein LLM Inhalte in Echtzeit voneinander unterscheiden?
Unsere Idee:
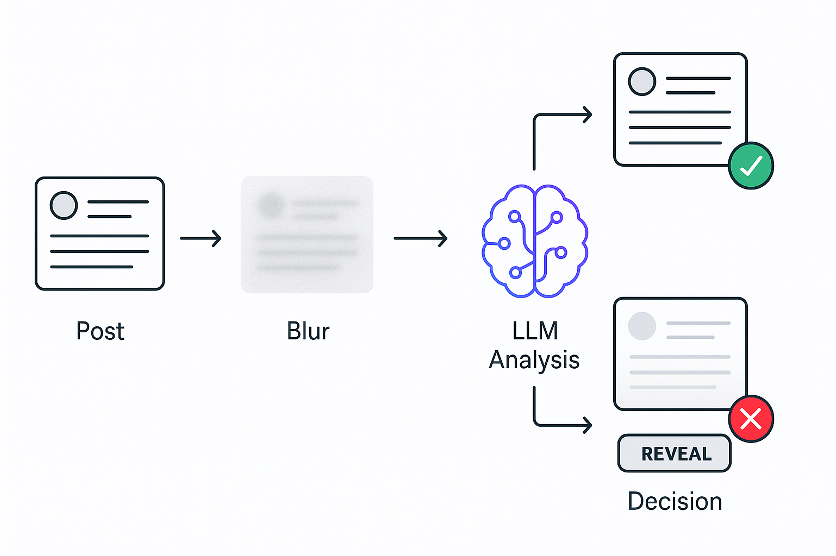
- Beiträge sofort unscharf machen
- LLM analysiert den Inhalt
- Beitrag wird wieder sichtbar, wenn er als unbedenklich eingestuft wird — ansonsten bleibt er verschwommen
Getestet haben wir das Ganze im Feed von X. Dafür haben wir den Code jedes Beitrags an ein LLM geschickt und gefragt, ob es sich um politische Inhalte handelt. Da LLMs nicht besonders schnell reagieren, wurden alle Beiträge zunächst unscharf gemacht. Erst nach der Analyse durch das Modell wurden sie — je nach Ergebnis — wieder angezeigt.
Damit zeigt sich, dass eine völlig neue, semantische Form der Inhaltsfilterung möglich ist.
Und das Beeindruckendste: Der komplette Prototyp entstand innerhalb weniger Stunden — etwas, das mit klassischem Machine Learning Monate gedauert hätte.
Hier eine kurze Demo:
So funktioniert es: Ein Beitrag erscheint, wird sofort unscharf, vom LLM analysiert und anschließend entweder sichtbar gemacht oder verborgen. Falls nötig, kann jeder Beitrag manuell eingeblendet werden.
Während dieser Tests auf X stellten wir fest, dass einige Beiträge nicht erfasst wurden — oft deshalb, weil sie hauptsächlich aus Bildern bestanden. Und genau das brachte uns zum zweiten Experiment.
Experiment 2: Blockieren nach visueller Bedeutung
Im zweiten Experiment wollten wir dem Werbeblocker beibringen, zu sehen.
Unsere Idee:
- Beiträge sofort unscharf machen
- Ein Vision-LLM analysiert einen Screenshot des Beitrags
- Beitrag wird wieder sichtbar, wenn er unbedenklich ist — ansonsten bleibt er verschwommen
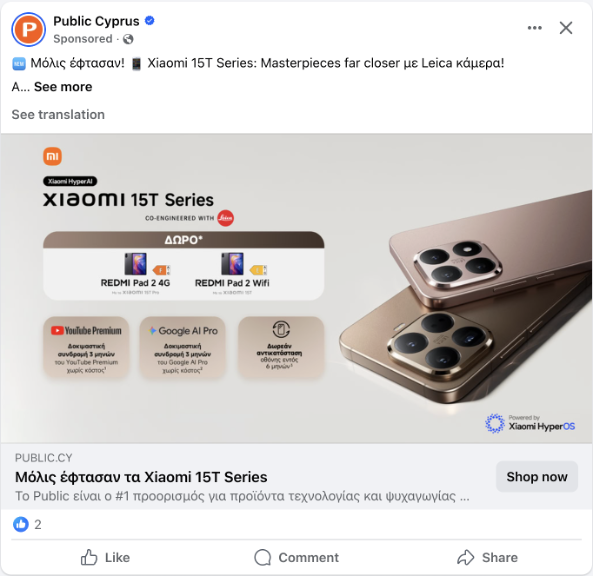
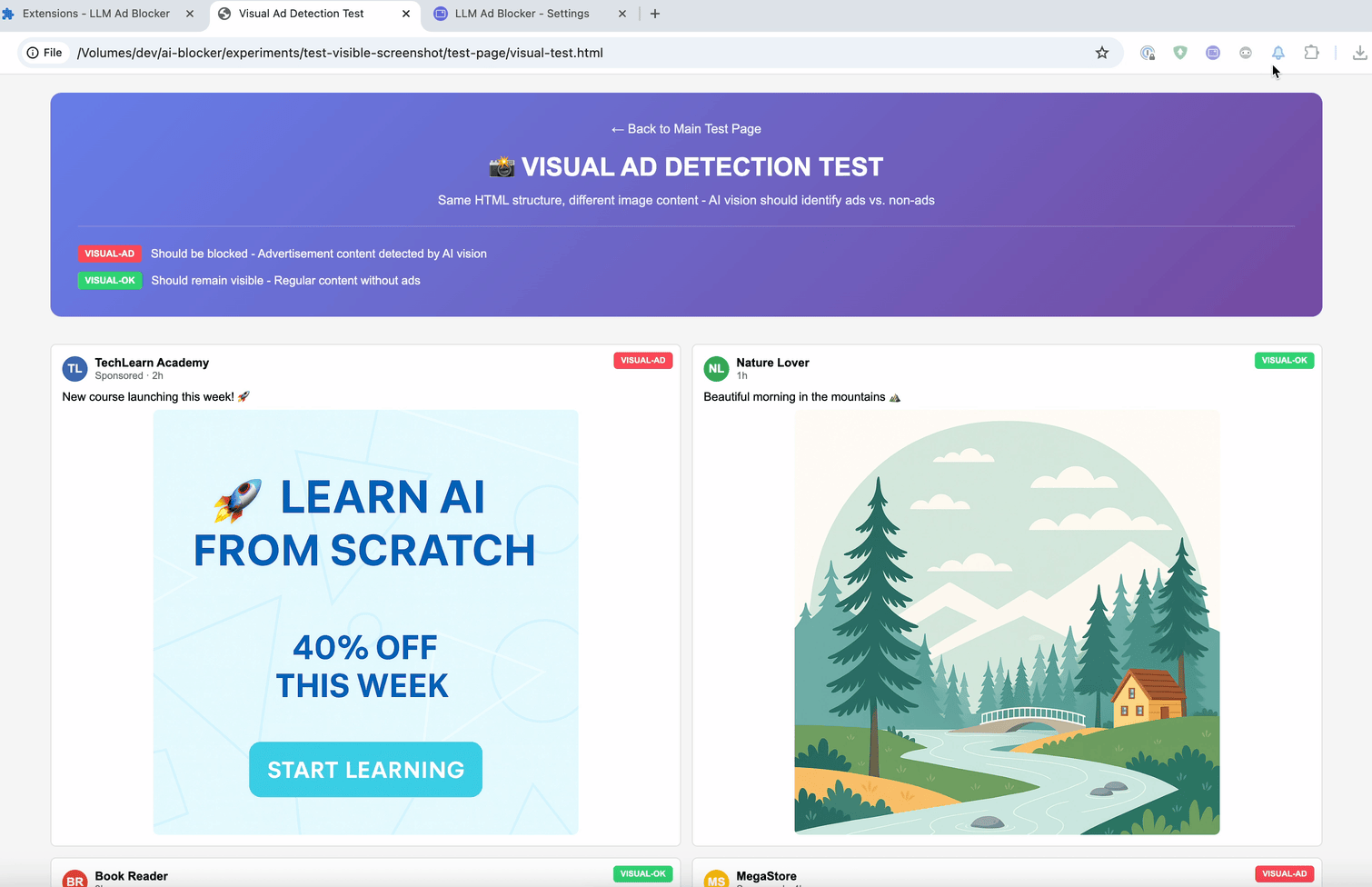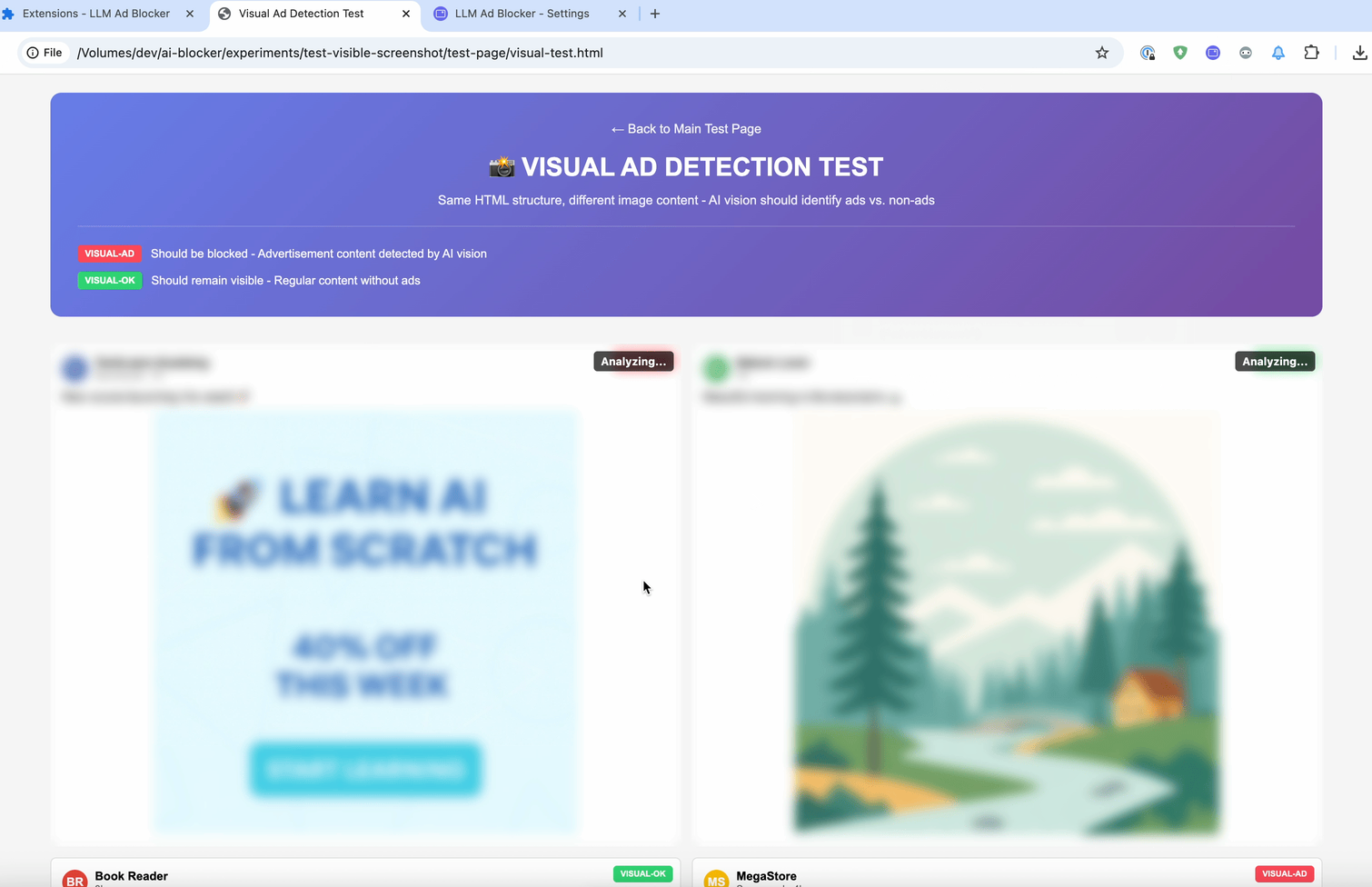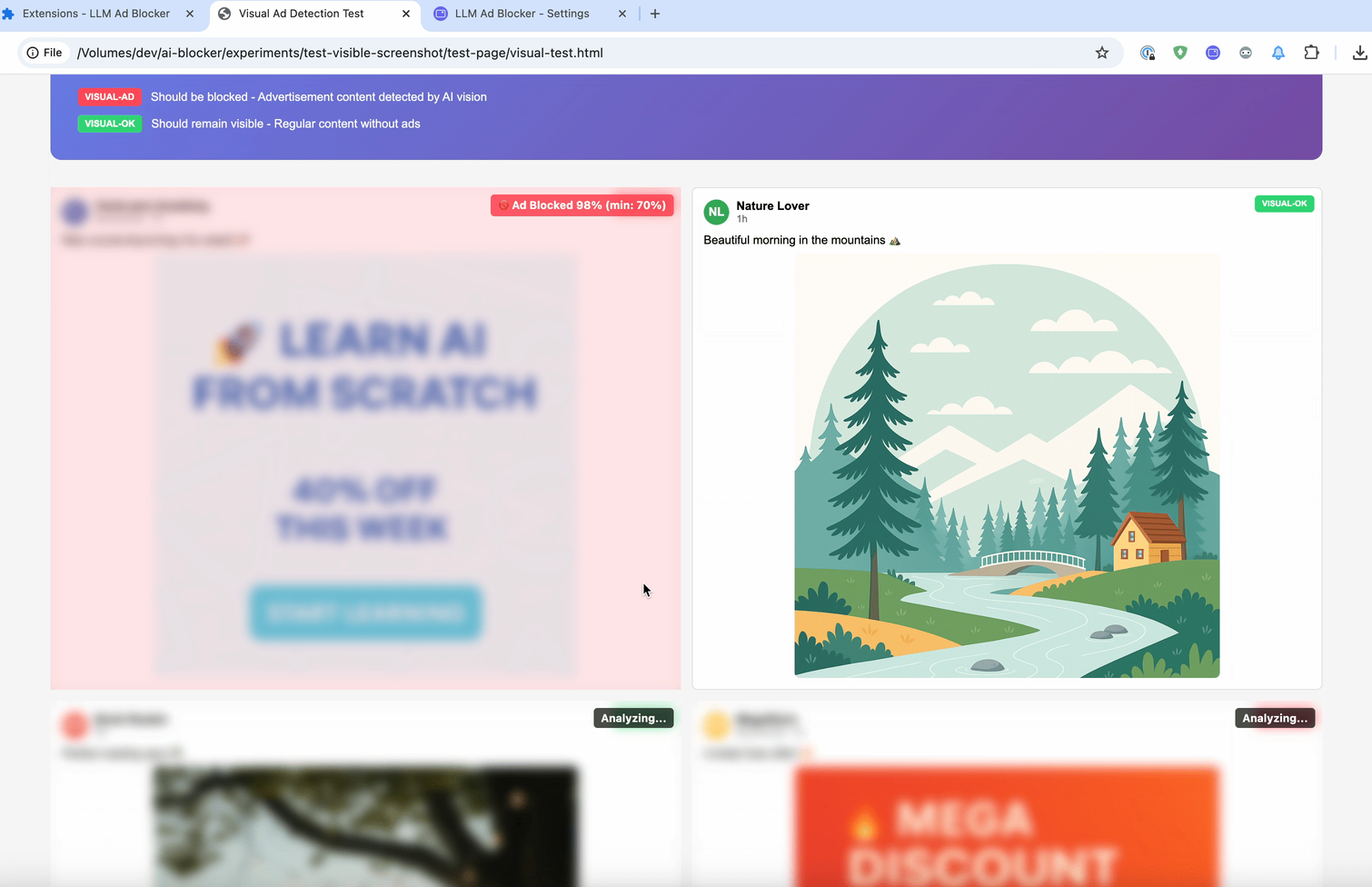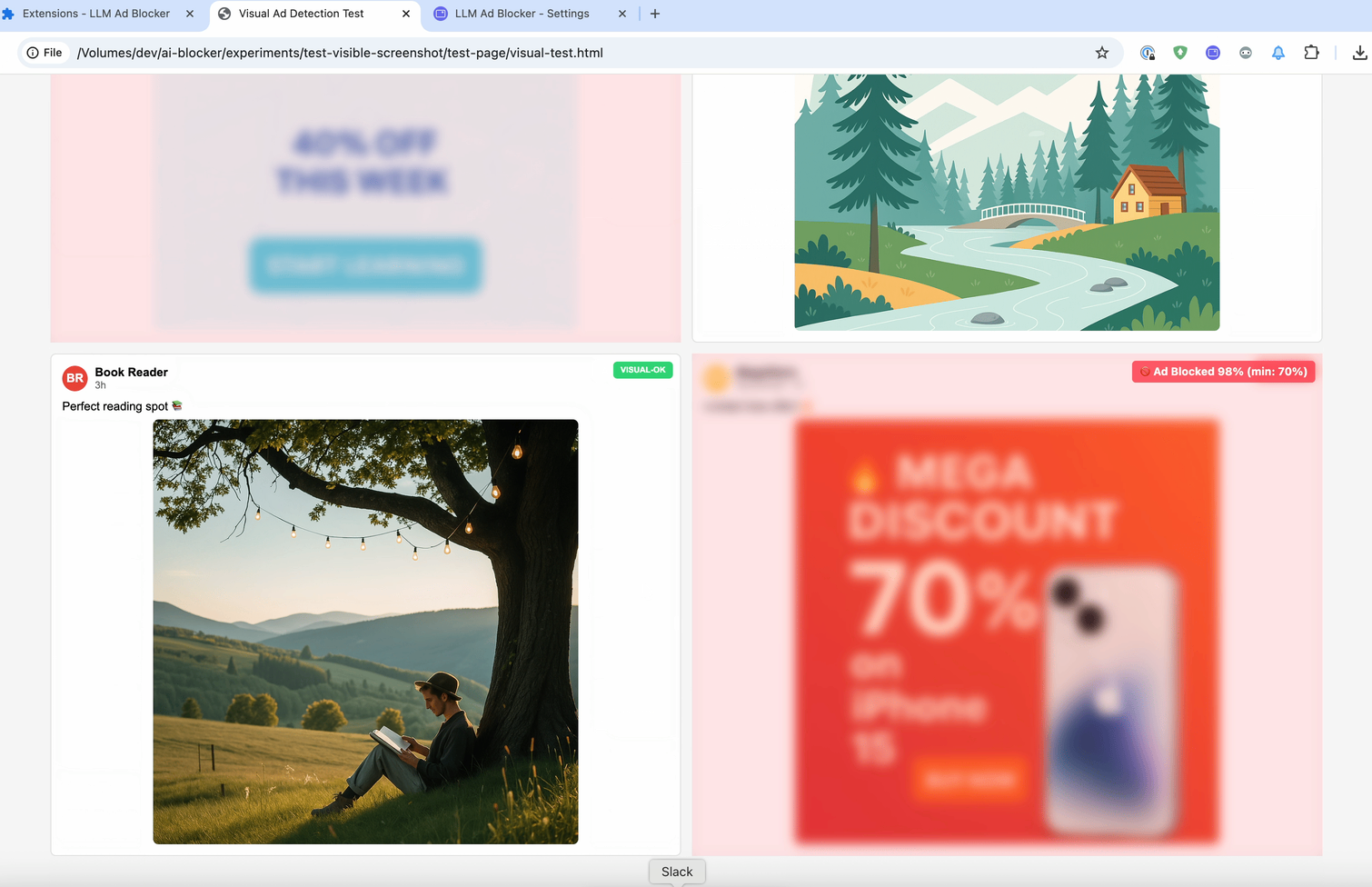
Oft enthalten Beiträge nur sehr wenig Text. Genau das sieht man in diesem Beispiel: ein Facebook-Beitrag fast ohne Text, nur ein Bild.
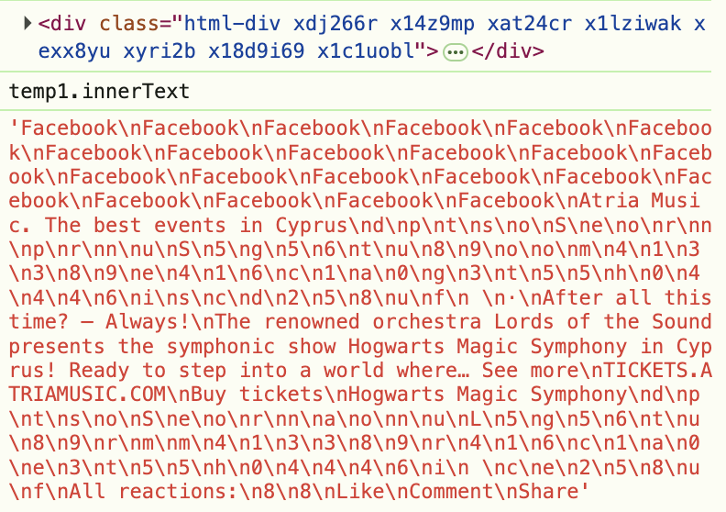
Aber das Problem betrifft nicht nur Beiträge ohne Text. Selbst wenn Text vorhanden ist, wird er auf vielen Seiten durch verschleierten HTML-Code versteckt. Im Screenshot aus den Entwicklertools unten sieht man, wie das „Gesponsert“-Label in zufälligem HTML versteckt wird.
Deshalb müssen wir aufhören, nur den Code zu analysieren, und stattdessen das betrachten, was Menschen tatsächlich sehen. Die Idee ähnelt also dem ersten Experiment — aber diesmal analysieren wir nicht den Quellcode des Elements, sondern sein sichtbares Erscheinungsbild.
Dazu machen wir einen Screenshot des Beitrags, schicken ihn an ein Vision-LLM und fragen, ob der Inhalt politisch ist.
Und wieder hat es funktioniert!
Der Kern des Prototyps war in rund einer Stunde fertig. Danach kam jedoch die eigentliche Herausforderung: Screenshots über eine Browsererweiterung aufzunehmen, ist komplizierter als erwartet.
Warum? Einer der Ansätze, die wir getestet haben, war die Debugger API. Damit kann man jedes Element erfassen — sogar außerhalb des sichtbaren Bereichs der Seite —, aber die Seite beginnt dabei zu flackern. Und genau das ist für viele Menschen störend. Unten sehen Sie die Demo:
Die zweite Möglichkeit war chrome.tabs.captureVisibleTab — die Standard-API von Chrome, um Screenshots in Erweiterungen zu erstellen. Diese Methode verursacht kein Flackern. Allerdings kann sie nur den sichtbaren Bereich erfassen, also das, was sich gerade im Viewport befindet. Außerdem begrenzt Chrome, wie viele Screenshots pro Sekunde aufgenommen werden dürfen.
Wenn also mehrere Elemente geprüft werden müssen, heißt es warten — und analysiert werden können nur die Beiträge, die sich bereits im sichtbaren Bereich befinden.
Diese Experimente haben gezeigt, dass LLMs Beiträge tatsächlich analysieren und entscheiden können, ob sie ausgeblendet werden sollten.
Aber bedeutet das, dass wir Filterlisten komplett abschaffen können? Nein. Wir brauchen sie weiterhin, um überhaupt zu wissen, welche Elemente überprüft werden sollten. Eine Webseite besteht aus Tausenden von Elementen, und jedes einzelne davon durch ein LLM zu schicken, wäre viel zu langsam — und viel zu teuer.
Experiment 3: Filterlisten erweitern — ein neues Grundbaustein
Wenn wir weiterhin wissen müssen, welche Elemente geprüft werden sollen, liegt der nächste Schritt auf der Hand: LLMs mit Filterlisten verbinden — und ihre Möglichkeiten in ein wiederverwendbares Werkzeug verwandeln, das Filterlisten langfristig stärker und flexibler macht.
Das Problem ist nur: Für jede semantische Aufgabe eine eigene Erweiterung zu bauen, ist keine Lösung. Dafür braucht es etwas Allgemeineres.
Die Inspiration: Die erweiterte CSS-Pseudoklasse :contains.
Die Frage: Was wäre, wenn man nicht nur nach Text, sondern nach Bedeutung filtern könnte?
Das Ergebnis: Drei neue experimentelle Pseudoklassen:
selector:contains-meaning-embedding('criteria')
selector:contains-meaning-prompt('criteria')
selector:contains-meaning-vision('criteria')
Um eine universelle Lösung zu entwickeln, haben wir uns an der Extended CSS Library von AdGuard orientiert. Sie erweitert native CSS-Möglichkeiten durch zusätzliche Pseudoklassen.
Eine davon ist :contains(), die Elemente ausblendet, sobald ein bestimmter Text darin vorkommt. Unsere Idee war, diesen Ansatz weiterzuentwickeln — weg von starren Schlüsselwörtern, hin zu echter semantischer Bedeutung.
So entstanden drei experimentelle Varianten: Embedding, Prompt und Vision.
:contains-meaning-embedding
Funktionsweise: Ähnlichkeiten zwischen dem Text eines Elements und den Kriterien vergleichen
Vorteile: Sehr schnell und kostengünstig
Nachteile: Erfordert passende Schwellenwerte und hat bei mehreren Sprachen Schwierigkeiten
Beginnen wir mit :contains-meaning-embedding.
Hier kommen sogenannte Embedding-Modelle zum Einsatz. Diese Modelle wandeln Text in Zahlen um — in eine Art Bedeutungscode. Anschließend vergleichen wir die Embeddings des Seitentextes mit den Embeddings der gesuchten Kriterien. Wenn die Ähnlichkeit hoch genug ist, gilt das Element als Treffer.
Der große Vorteil: Das Ganze ist extrem schnell und günstig, besonders wenn Caching aktiv ist. Die Kehrseite: Man muss passende Schwellenwerte definieren, und bei mehreren Sprachen kann es zu Unsicherheiten kommen.
:contains-meaning-prompt
Funktionsweise: Ein LLM direkt fragen, ob der Inhalt zu den Kriterien passt
Vorteile: Höhere Genauigkeit, keine Schwellenwerte nötig, funktioniert sprachübergreifend
Nachteile: Langsamer und teurer als Embeddings
Als Nächstes kommt :contains-meaning-prompt.
Hier nutzen wir eine einfache Prompt-API: Wir schicken den sichtbaren Inhalt eines Elements an ein LLM und fragen schlicht, ob er den gewünschten Kriterien entspricht. Kein Feintuning, keine Schwellenwerte — das Modell entscheidet selbst.
Der Ansatz ist deutlich genauer und funktioniert unabhängig von der Sprache. Der Nachteil: Im Vergleich zu Embeddings ist die Methode langsamer und teurer.
:contains-meaning-vision
Funktionsweise: Ein LLM fragen, ob ein Screenshot zu den Kriterien passt
Vorteile: Erkennt visuelle Inhalte, die Text- oder Embedding-Methoden übersehen
Nachteile: Komplexere UX, mögliches Bildschirmflackern
Die dritte Methode ist :contains-meaning-vision.
Dabei werden Screenshots der ausgewählten Elemente erstellt und an ein Vision-LLM geschickt. Das Modell entscheidet dann, ob der sichtbare Inhalt zu den Kriterien passt. Danach funktioniert alles wie bei :contains-meaning-prompt.
Der große Vorteil: Diese Methode erkennt Inhalte, die rein textbasierte Ansätze nicht erfassen können — etwa Bilder, versteckte Labels oder visuelle Hinweise. Der Nachteil: Die Nutzererfahrung wird schnell komplizierter, z. B. durch mögliches Flackern beim Erfassen von Screenshots.
Diese drei Ansätze ergeben zusammen ein flexibles Werkzeug, das Filterlisten deutlich erweitern könnte. Je nach Situation kann man Geschwindigkeit (Embedding), Genauigkeit (Prompt) oder visuelle Erkennung (Vision) wählen. Um die Verzögerung bei der Analyse abzufangen, kann man Elemente zunächst unscharf machen und sie danach wieder anzeigen — oder eben verborgen lassen.
Performance- und Kostenanalyse
Nachdem wir nun drei Prototypen haben, stellt sich die entscheidende Frage: Sind sie überhaupt praxistauglich? Könnte so etwas real im Produkt eingesetzt werden?
Um das herauszufinden, haben wir die Leistung und die Kosten jedes Ansatzes genauer untersucht.
Embeddings
Fangen wir mit Embeddings an. Zunächst haben wir die Erweiterung mit einem Cloud-Modell von OpenAI getestet — und um ehrlich zu sein, die Ergebnisse waren eher enttäuschend. Dann haben wir ein kleines lokales Modell ausprobiert, und das Ergebnis hat uns überrascht: Es war schneller, völlig kostenlos und erreichte in unseren Tests 100% Genauigkeit.
Das zeigt, dass kleine lokale Modelle bei bestimmten Aufgaben großen Cloud-APIs durchaus überlegen sein können.

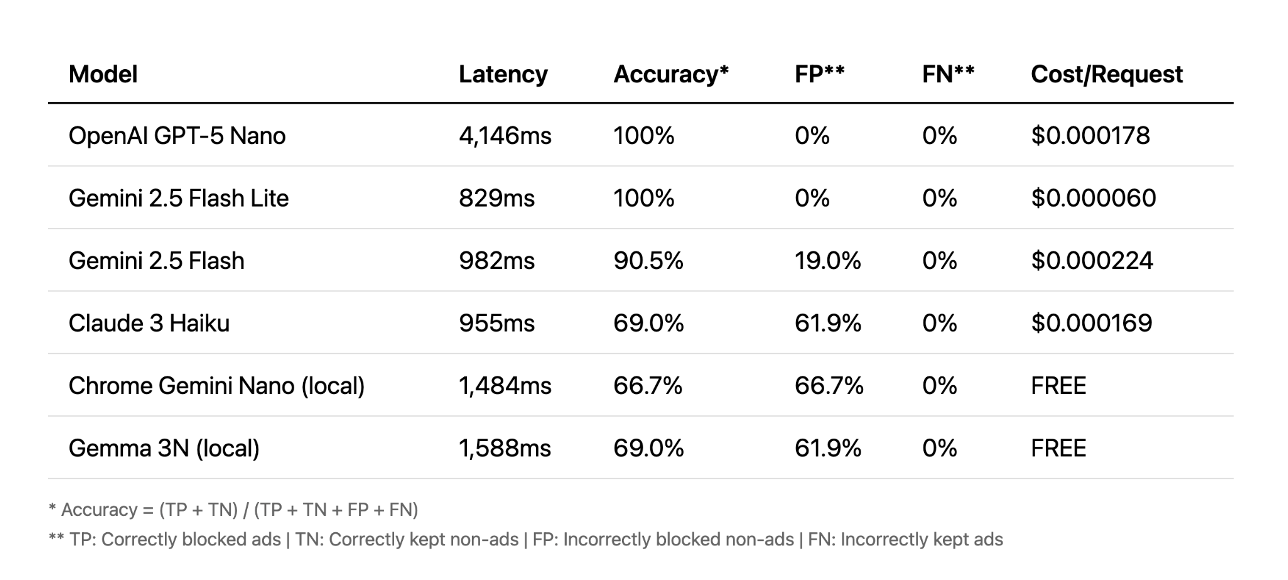
Prompts
Bei den Prompt-basierten Methoden sieht die Sache anders aus. Hier lieferten die Cloud-APIs die besten Ergebnisse — einige mit 100% Genauigkeit in weniger als einer Sekunde. Andere brauchten dagegen über vier Sekunden, was für eine flüssige Nutzererfahrung deutlich zu langsam ist.
Lokale Modelle konnten in diesem Fall weder bei Geschwindigkeit noch bei Genauigkeit mithalten.
Vision
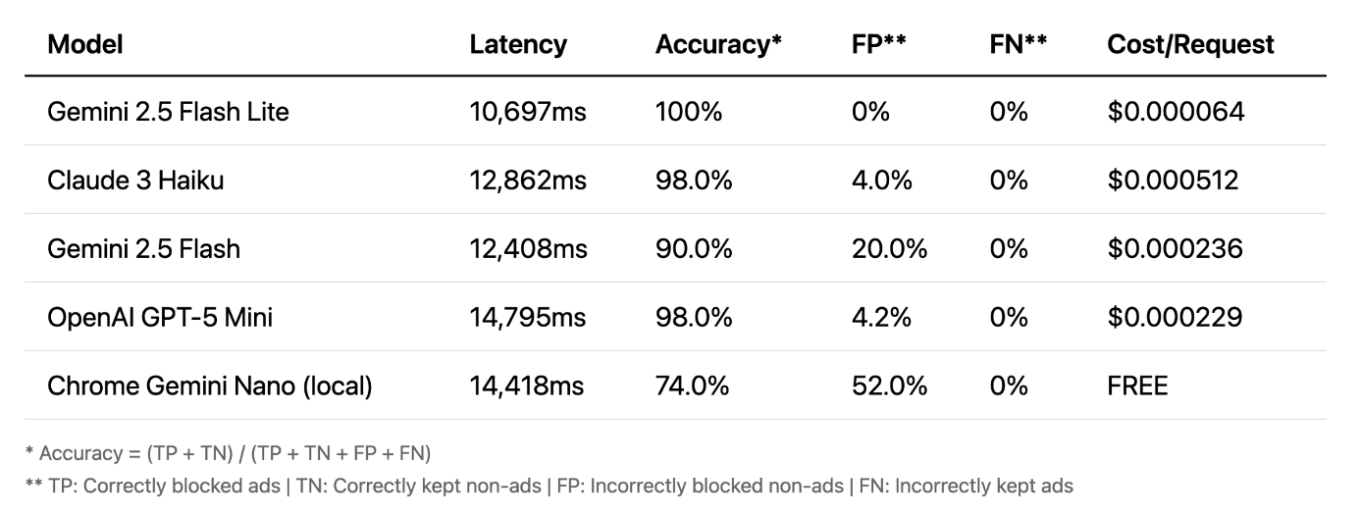
Kommen wir nun zur Vision-Variante — hier wird es besonders spannend. Die Genauigkeit ist sehr hoch, und selbst lokale Modelle liefern gute Ergebnisse. Vision gehört oft zu den zuverlässigsten Methoden, denn sie arbeitet mit Bildern statt Text und erkennt damit Inhalte, die andere Ansätze übersehen.
Der große Nachteil: die Verzögerung. Eine Analysezeit von 10 bis 15 Sekunden ist für Echtzeit-Blockierung schlicht nicht praktikabel.
Methodenvergleich
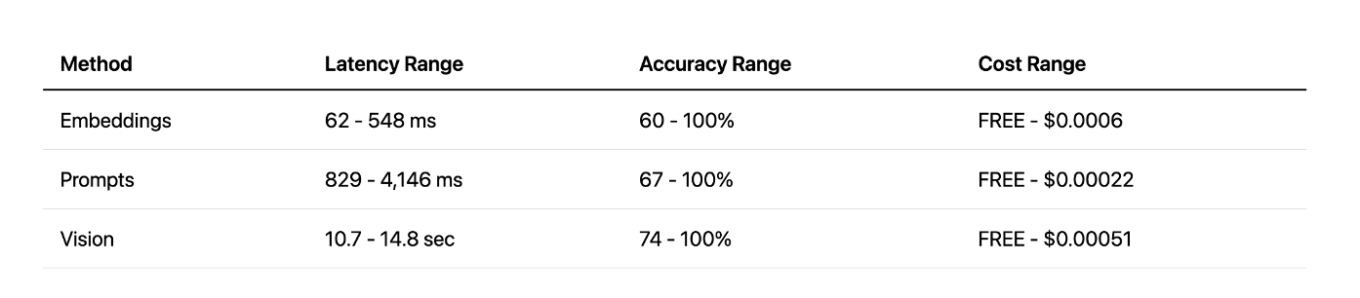
Im direkten Vergleich zeigt sich: Vision liefert zwar hervorragende Genauigkeit, aber die Latenz ist einfach zu hoch. Prompt-basierte Ansätze bieten einen deutlich besseren Kompromiss zwischen Geschwindigkeit und Präzision, vor allem bei Nutzung von Cloud-APIs. Und die lokalen Embeddings haben uns positiv überrascht — sie waren extrem schnell und für bestimmte Aufgaben erstaunlich effektiv. Am Ende hat jede Methode ihre eigenen Stärken und Schwächen, und keine ist in allen Situationen überlegen.
Die Zukunft dieses Ansatzes
Vision: Im Moment zu langsam, verbessert sich aber stetig
Embeddings: In Erweiterungen unpraktisch, wären ideal als eingebaute Browser-Funktion
Lokale LLM-Prompts: Experimentell, braucht bessere Genauigkeit
Was bedeutet das also für die Zukunft? Nach unserem aktuellen Stand ist Vision einfach noch zu langsam. Embeddings sind in Browsererweiterungen nicht besonders praktikabel, könnten jedoch hervorragend funktionieren, wenn Browser eines Tages eine eigene API dafür anbieten. Und lokale LLM-Prompts wirken momentan wie der vielversprechendste Weg für ein echtes, auslieferbares Experiment mit der Chrome Prompt API. Gleichzeitig müssen wir die Nutzererfahrung verbessern: Das aktuelle Vorgehen, Elemente kurzzeitig zu verwischen, ist nicht optimal. Mit schnelleren Modellen ließe sich diese Zeit verkürzen — oder vielleicht gibt es irgendwann eine völlig neue Herangehensweise.
Was haben wir gelernt?
LLMs ermöglichen uns erstmals, über einfache Mustererkennung hinauszugehen und tatsächlich die Bedeutung von Webinhalten zu verstehen. Dadurch entsteht ein völlig neuer, semantischer Ansatz für Content-Filtering.
Außerdem erlauben LLMs extrem schnelles Prototyping: Ideen, die früher Monate gebraucht hätten, lassen sich heute in wenigen Stunden ausprobieren. Auch wenn es noch praktische Herausforderungen gibt, eröffnet dieser Ansatz die Möglichkeit, Content-Filtering grundsätzlich neu zu denken.
Wir hoffen, dieser Artikel hat Ihnen eine neue Perspektive auf das Thema gegeben. Alles, was wir hier beschrieben haben, können Sie selbst ausprobieren — laden Sie einfach den AI AdBlocker aus dem Chrome Web Store herunter.
Der komplette Quellcode ist ebenfalls auf GitHub verfügbar. Melden Sie sich gern, wenn Sie Fragen oder Anregungen haben!
















































