Au-dela des listes de filtres : le blocage repensé à l'aide des LLM
L'un des plus grands obstacles auxquels les bloqueurs de publicités ont été confrontés tout au long de leur existence est lié à leur nature : il les listes de filtres ont des limites et en plus il faut constamment les les maintenir à jour. Dans la plupart des cas, cette maintenance est manuelle et extrêmement fastidieuse.
Dans cette étude, je vais explorer le fonctionnement actuel des bloqueurs de publicités et examiner les tentatives précédentes de l'automatisation de ce processus à l'aide des méthodes d'apprentissage automatique. Je vais passer ensuite à mes propres expériences d'ajout du LLM au blocage des publicités, je vais parler de l'avenir de cette approche et puis je vais vous présenter le prototype fonctionnel d'extension de navigateur que vous pouvez télécharger et tester vous-même.
Je sais que vous êtes probablement impatients d'en savoir plus sur les expériences LLM et de découvrir l'extension, mais commençons par planter le décor en vous donnant quelques informations contextuelles.
Le blocage des annonces : comment fonctionne-t-il actuellement
Au cœur de tous les bloqueurs d'annonces vous trouverez des listes de filtres, qui sont gérées par la communauté. Ces listes comprennent des milliers de règles qui se répartissent en deux catégories principales : les règles réseau et les règles cosmétiques.
Les règles réseau : la première ligne de défense
Actions : bloquer, rediriger ou modifier les requêtes.
Exemple : ||evil-ads.com^ — cette règle bloque le site web evil-ads.com et ses sous-domaines.
Les règles réseau bloquent les requêtes vers les serveurs publicitaires tiers avant même que le contenu n'atteigne votre navigateur, ce qui constitue une approche rapide et efficace. Ces règles peuvent bloquer, rediriger ou modifier les requêtes.
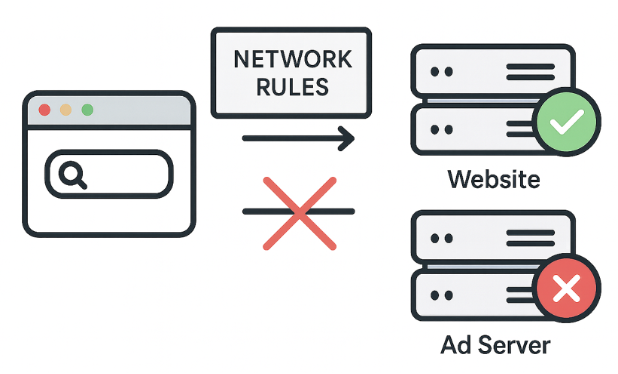
Mais les règles réseau ne peuvent pas bloquer tout. Par exemple, certaines publicités sont diffusées à partir du même domaine que le contenu, donc leur blocage au niveau du réseau perturberait le fonctionnement du site. C'est là que les règles cosmétiques entrent en jeu.
Les règles cosmétiques : pour nettoyer la page
Actions : utiliser les sélecteurs CSS pour masquer les éléments indésirables directement sur la page ou appliquer des styles personnalisés.
Exemple : example.com##.ad-banner — masque les éléments avec la classe « ad-banner » sur example.com)
CSS (Cascading Style Sheets) est un langage de feuille de style qui définit la présentation visuelle des documents HTML ou XML. Il spécifie la manière dont les éléments doivent apparaître sur l'écran de votre appareil.
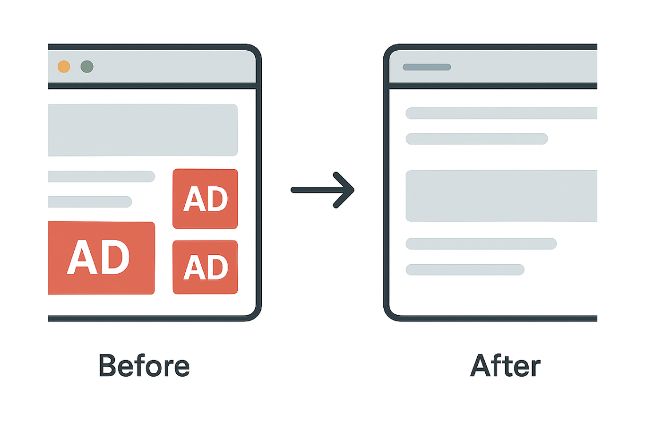
Les règles cosmétiques éliminent essentiellement les éléments publicitaires résiduels que les règles réseau plus simples ne peuvent pas bloquer.
Au-delà du CSS : les règles scriptlet
Actions : modifier ou désactiver certaines fonctionnalités de script sur la page.
Exemple : example.com#%#//scriptlet(“abort-on-property-read”, “alert”) — arrête un script sur example.com s'il tente d'accéder à une fonctionnalité spécifique du navigateur telle que alert.
Lorsque le CSS ne suffit pas pour gérer des scripts complexes, comme la réinjection de publicités, nous utilisons des scriptlets. Les scriptlets sont de petits extraits de code JavaScript injectés par les bloqueurs de publicités pour neutraliser les comportements indésirables.
Les scriptlets sont devenus l'outil préféré des développeurs de filtres, car ils résolvent des problèmes que le CSS et les règles réseau ne peuvent pas résoudre.
Le potentiel et les limites
Nous avons brièvement observé le fonctionnement les listes de filtres. Elles sont puissantes et très efficaces pour les modèles connus, mais elles ont également certaines limites. Elles ont du mal à gérer la publicité native, nécessitent des mises à jour constantes et, dans Manifest v3, ces mises à jour sont plus difficiles.
Ces limites soulèvent une question fondamentale : et si nous pouvions supprimer complètement les listes de filtres ? Et si le bloqueur de publicités pouvait décider lui-même ce qui doit être bloqué ?
Imaginez : pas de filtres, pas de mises à jour, pas de poursuite des réseaux publicitaires. Plus de réglages manuels ni de jeu du chat et de la souris. Au final, n'est-ce pas ce que les utilisateurs attendent naturellement des bloqueurs de publicités ? « Installer et oublier », profiter d'un web propre sans avoir à prêter davantage attention à votre bloqueur de publicités. Et c'est exactement ce que les premières expériences d'apprentissage automatique voulaient réaliser.
Avec cette motivation à l'esprit, voyons comment les entreprises et les chercheurs ont essayé d'utiliser l'apprentissage automatique pour résoudre ces problèmes.
Un bref historique de l'apprentissage automatique dans le domaine du blocage des publicités
Revenons sur les différentes tentatives passées visant à remplacer les listes de filtres par l'apprentissage automatique. Cela nous aidera à comprendre pourquoi cela n'a pas abouti, au moins pas encore.
Projet Moonshot par eyeo
Objectif : automatiser le filtrage cosmétique à grande échelle.
Méthode :
- Formation d'un modèle ML sur la structure des pages (DOM, HTML, CSS)
- Utilisation de listes de filtres existantes pour l'étiquetage
- Analyse des pages directement dans l'extension du navigateur
Le projet Moonshot d'eyeo a été présenté lors du Ad-Filtering Dev Summit en 2021. Ils ont formé un modèle sur la structure des pages en utilisant des listes de filtres comme étiquettes. Le modèle fonctionnait dans l'extension du navigateur pour prédire et masquer les éléments publicitaires. Il fonctionnait, mais rencontrait des difficultés : données déséquilibrées, difficultés de déploiement et besoins constants de reformatage.
Idée clé : prendre des décisions basées sur la structure de la page, et non sur les images.
Résultat : prédiction et masquage des éléments publicitaires, en complément du blocage réseau.
Difficultés : déséquilibre des données, friction de déploiement et réentraînement constant.
AdGraph par Brave
Objectif : bloquer les publicités et les traqueurs en temps réel.
Méthode :
- Création d'un graphique reliant toutes les activités de la page (DOM, réseau, JavaScript)
- Classification du contenu en fonction de son contexte dans le graphique
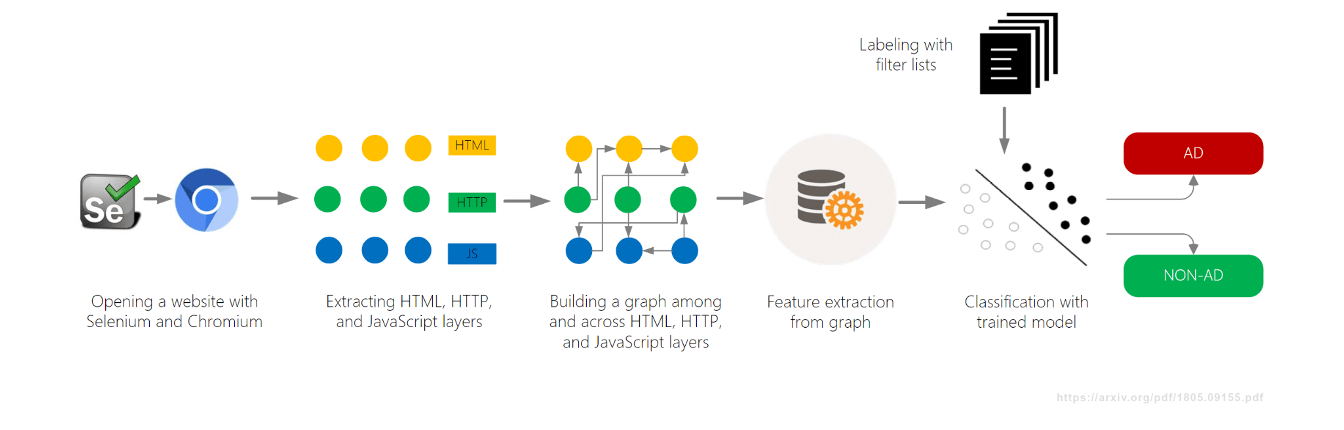
Un autre projet d'apprentissage automatique, AdGraph, a été développé par Brave Browser et présenté en 2019, également lors de l'AFDS. Ils ont créé un graphique permettant de suivre les connexions entre tous les éléments d'une page (DOM, réseau, JavaScript), puis ils ont classé les ressources en fonction du contexte.
AdGraph a atteint un haut niveau de précision en remontant les scripts jusqu'aux serveurs publicitaires, même avec des noms aléatoires. Mais cela nécessitait une intégration profonde dans le navigateur et une maintenance constante.
Idée clé : des décisions basées sur la causalité, et pas seulement sur des modèles d'URL statiques.
Résultat : très haute précision (~95-98 %) et robustesse face à l'obfuscation.
Défis : intégration profonde dans le navigateur et maintenance constante requises.
PERCIVAL par Brave
Objectif : bloquer les images publicitaires en temps réel.
Méthode :
- Utilisation d'un réseau neuronal compact (CNN) pour classer les images.
- Intégration directe dans le pipeline de rendu d'images du navigateur.
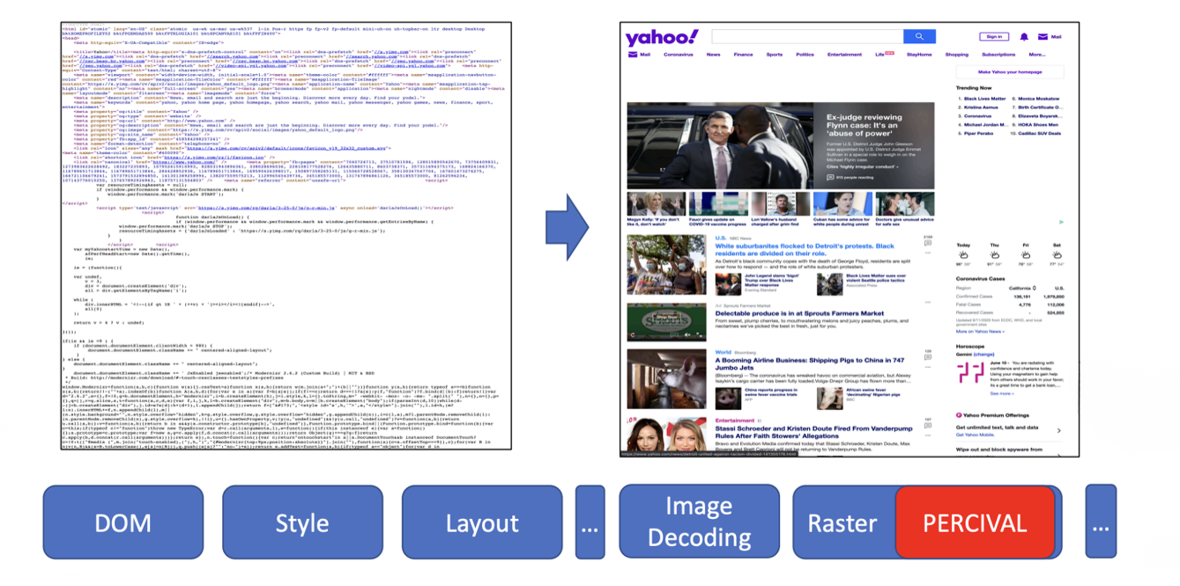
En 2020, Brave a présenté une autre approche d'apprentissage automatique appelée PERCIVAL, qui se concentrait sur le blocage des images publicitaires. Ils ont intégré un réseau neuronal compact directement dans le pipeline de rendu du navigateur dans le but de classer les images au fur et à mesure de leur chargement. Les résultats ont été impressionnants : ils ont atteint une précision de 97 % en analysant directement le contenu des images. Mais cette approche avait aussi ses limites : elle était vulnérable aux images adversaires et ne fonctionnait que pour les publicités illustrées.
Idée clé : analyser le contenu visuel d'une image, et pas seulement son URL ou ses métadonnées.
Résultat : précision d'environ 97 % avec une faible charge de rendu.
Défis : vulnérable aux images adversaires ; limité aux publicités illustrées.
AutoFR (recherche fondamentale)
Objectif : générer automatiquement des règles de filtrage à partir de zéro.
Méthode :
- Utilisation de l'apprentissage par renforcement (un système d'essais et d'erreurs) pour tester les règles.
- Analyse du contenu des pages afin d'éviter de perturber le fonctionnement du site.
Au-delà des efforts entrepris par l'industrie, des chercheurs universitaires se sont également joints à la recherche de meilleures solutions. L'un des projets intéressants était AutoFR, qui visait à générer automatiquement des règles de filtrage.
AutoFR a été présenté par Hieu Van Le lors de l'AFDS 2022 et de l'AFDS 2023.
Il génère des modèles d'URL et des sélecteurs CSS, les teste et tire des enseignements des résultats tout en évitant de perturber le fonctionnement des sites. Les résultats ont été très impressionnants : AutoFR a atteint une efficacité de 86 % (par rapport à EasyList), avec des règles générées en quelques minutes.
Idée clé : génération automatisée de règles tenant compte des perturbations du fonctionnement des sites.
Résultat : efficacité de blocage d'environ 86 % ; règles générées en quelques minutes.
SINBAD (recherche fondamentale)
Objectif : détecter et localiser les dysfonctionnements du site causés par les bloqueurs de publicités.
Méthode :
- Utilisation de la « saillance web » pour identifier les éléments visuels importants.
- Comparaison des versions des pages avec et sans bloqueur de publicités pour trouver ce qui ne fonctionnait pas.
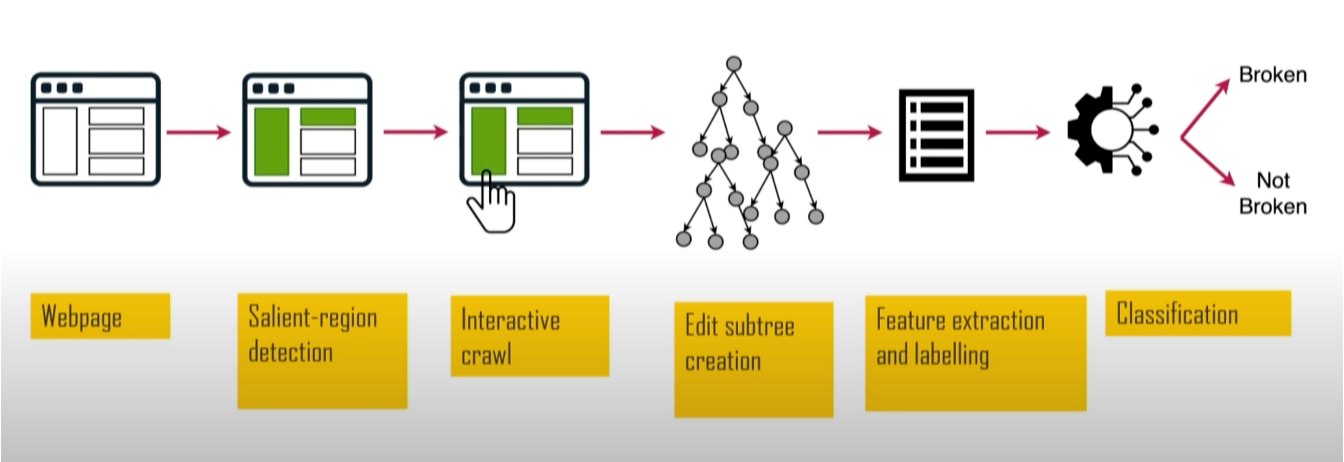
SINBAD était un autre projet de recherche fondamentale. Il visait à détecter les cas où les règles de filtrage perturbaient le fonctionnement des sites web. Ce projet était précieux, car les problémes de fonctionnement des sites sont l'une des principales raisons pour lesquelles les utilisateurs abandonnent les bloqueurs de publicités. Il a été présenté à l'AFDS 2023 par Sandra Siby de l'Imperial College London (à l'époque).
En analysant la taille, la position et le contraste, il identifie les éléments visuellement importants, tels que les titres et les boutons, puis teste leurs problémes fonctionnels. SINBAD a atteint un haut niveau de précision dans la détection des dysfonctionnements, avec des rapports spécifiques indiquant exactement ce qui ne marchait pas et quelles règles en étaient la cause.
Idée clé : se concentrer sur l'impact visible pour l'utilisateur afin de trouver et de résoudre les problèmes plus rapidement.
Résultat : une plus grande précision dans la détection des problémes de fonctionnement grâce à des rapports spécifiques et exploitables.
Résumé : Pourquoi le ML n'a pas succédé
Nous avons donc vu toutes ces expériences et tous ces projets de recherche. Mais voici le problème : malgré tout ce travail, aucun de ces outils basés sur l'apprentissage automatique n'a été largement adopté. Il serait donc logique de se demander : pourquoi l'apprentissage automatique n'a-t-il pas remplacé les filtres ?
Il y a plusieurs raisons :
- La barre est haute : les listes de filtres établies par des humains sont extrêmement efficaces et abouties. Il n'est pas facile d'égaler leur efficacité.
- Coût élevé : la création et la maintenance de grands ensembles de données de haute qualité sont coûteuses, alors que la plupart des listes de filtres sont gérées gratuitement par la communauté.
- Contournement : les modèles spécialisés peuvent être vulnérables aux attaques adversaires.
Il s'avère donc que la création de modèles spécialisés à partir de zéro est lente, coûteuse et peu flexible. C'est pour ça que l'approche ML n'a pas encore décollé et nous continuons à nous fier aux bonnes vieilles listes de filtres. Mais cela est-il sur le point de changer ?
C'est la que les LLM entrent en scène : volumineux, coûteux... mais différents
C'est alors qu'apparaissent les grands modèles linguistiques (LLM) et commencent à changer le monde. Peuvent-ils également changer le blocage des publicités ? Voyons comment les LLM peuvent être utilisés pour bloquer les publicités dans les extensions de navigateur. Mais avant cela, passons rapidement en revue certaines caractéristiques clés qui définissent les LLM.
Le blocage repensé grâce aux LLM : la puissance du prototypage rapide
Les modèles linguistiques à grande échelle (LLM) sont encore récents, mais leur progression a été remarquablement rapide. Ils sont désormais largement accessibles via des API, ce qui permet aux développeurs d'intégrer des fonctionnalités basées sur les LLM dans leurs produits avec un minimum d'efforts. De nombreux modèles sont disponibles à la fois dans des versions basées sur le cloud et déployées localement, offrant ainsi aux utilisateurs une grande flexibilité en fonction de leurs besoins.
Les capacités des LLM vont de la génération de textes de haute qualité à l'analyse de données, en passant par la création d'images et de vidéos, l'écriture de code et la prise en charge de workflows complexes. Cela les rend précieux dans de nombreux secteurs et très demandés par des millions de personnes. Mais tout n'est pas rose pour autant : parallèlement, l'exécution ou l'accès à ces modèles peut être coûteux, en particulier à grande échelle, ce qui constitue un véritable problème pour l'adoption des LLM dans de nombreux domaines.
Mais le plus important est que les LLM nous permettent de tester très rapidement des idées. Permettez-moi donc de vous présenter enfin mes expériences d'application des LLM au blocage des publicités dans les extensions de navigateur.
Expérience 1. Blocage par signification
L'idée de ma première expérience était de voir si un LLM pouvait distinguer entre différents types de contenu à la volée.
L'idée :
- Flouter immédiatement les publications
- Le LLM analyse leur contenu
- Déflouter si c'est sans danger ou garder flouté si ce n'est pas le cas
J'ai décidé de le tester sur le fil d'actualité de X. Je prenais le code de chaque publication et l'envoyais à un LLM, en lui demandant s'il s'agissait de politique. Comme les LLM sont un peu lents, j'ai immédiatement flouté toutes les publications, je les ai analysées à l'aide d'un LLM, puis je les ai défloutées si elles étaient sûres.
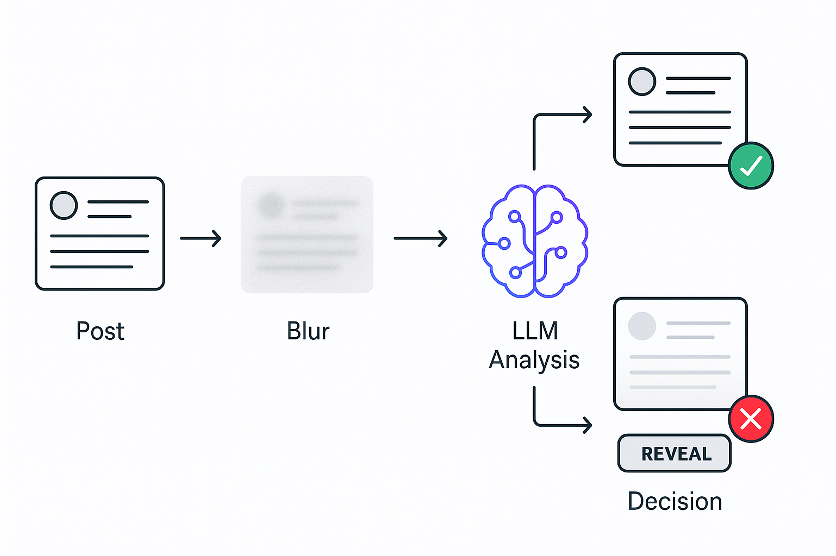
Et ça a marché !
Ce qui prouve qu'une nouvelle méthode sémantique de filtrage du contenu est possible. Et j'ai créé le prototype de cette extension en quelques heures seulement, ce qui aurait pris des mois avec l'apprentissage automatique traditionnel.
Laissez-moi vous montrer une petite démo :
Vous pouvez voir ici comment cela fonctionne. La publication apparaît, est immédiatement floutée, LLM l'analyse, puis la défoule si elle est sûre ou la garde cachée si ce n'est pas le cas. Les utilisateurs peuvent révéler manuellement toute publication floutée.
Pendant que je faisais des essais sur X, j'ai remarqué que certaines publications n'étaient pas bloquées car elles étaient principalement composées d'images. Cela m'a conduit à la deuxième expérience.
Expérience 2. Blocage par signification visuelle
Dans cette expérience, je vais apprendre au bloqueur d'annonces à voir.
L'idée :
- Flouter immédiatement les publications
- Vision LLM analyse la capture d'écran avec la publication
- Déflouter si c'est sans danger ou laisser flou si ce n'est pas le cas
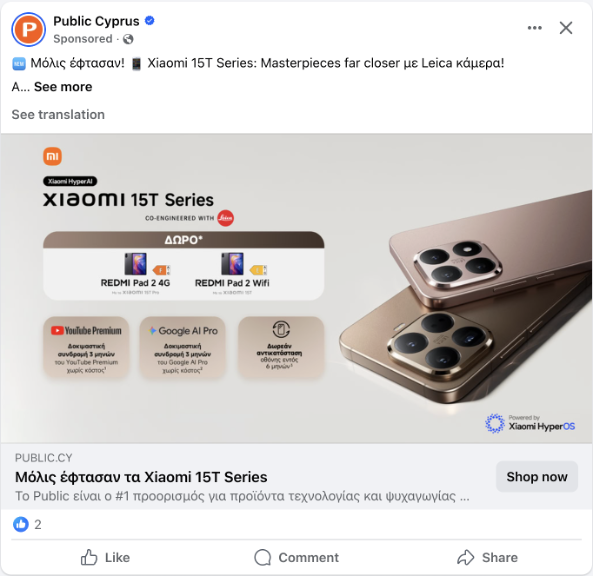
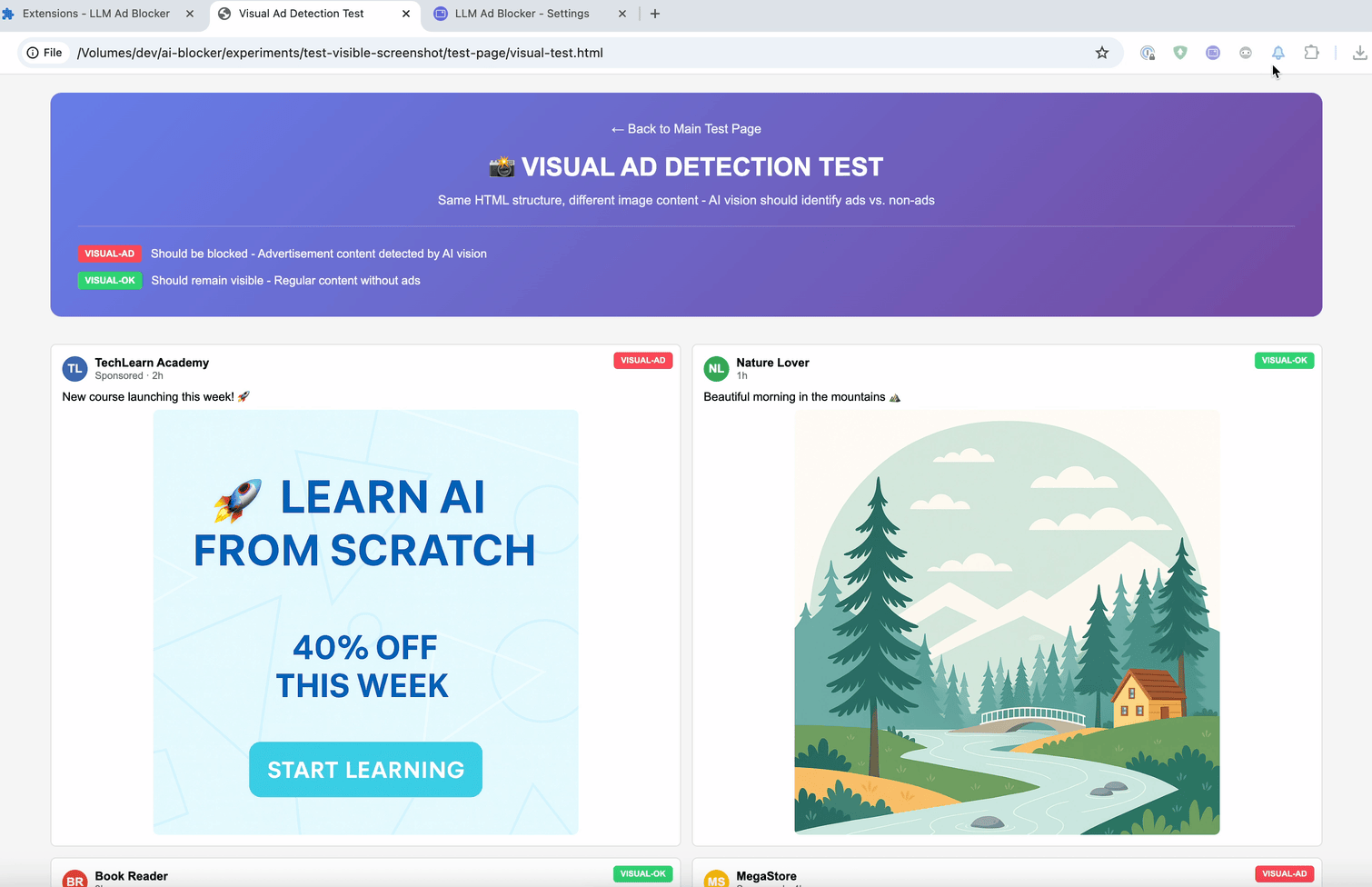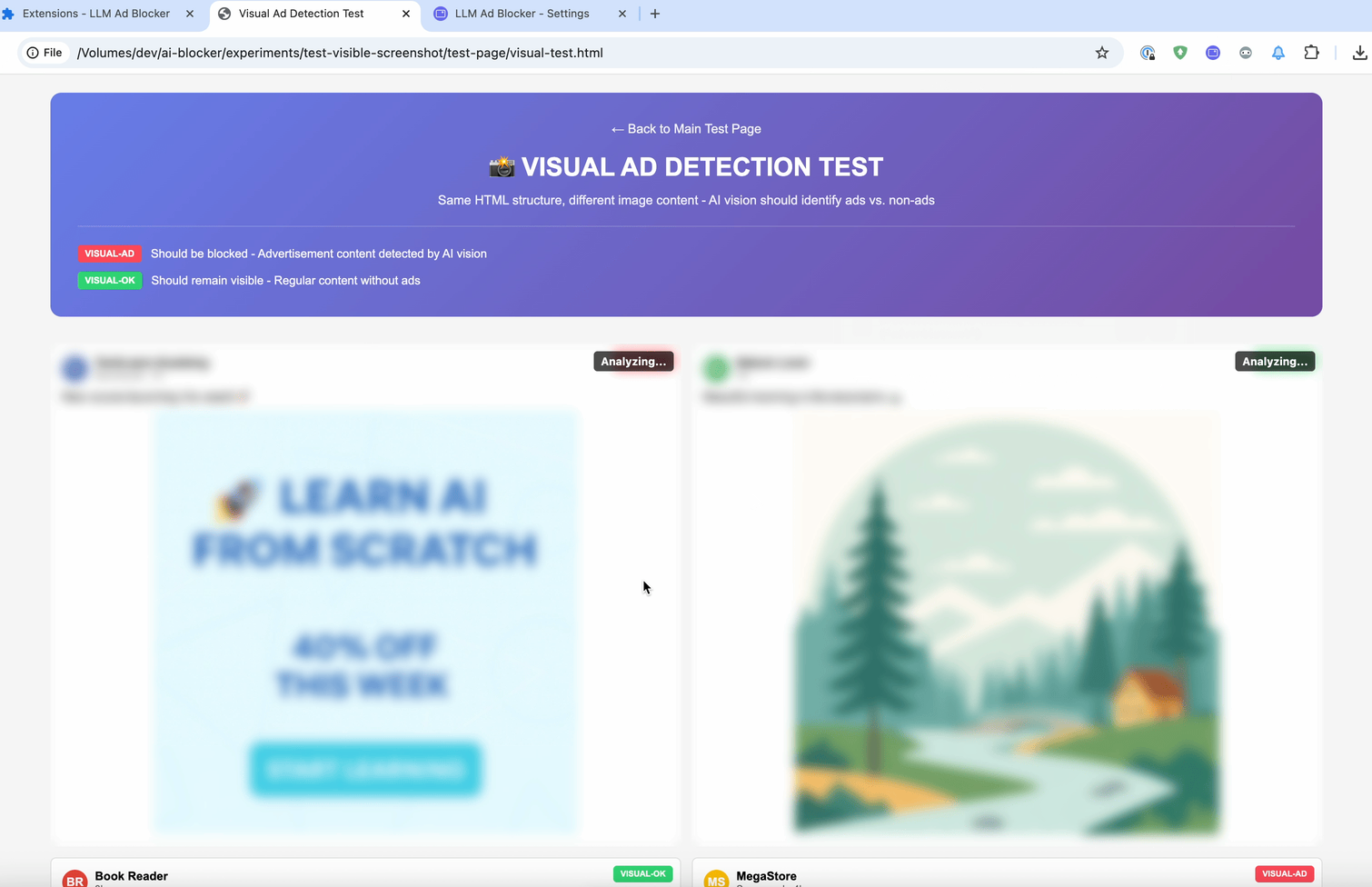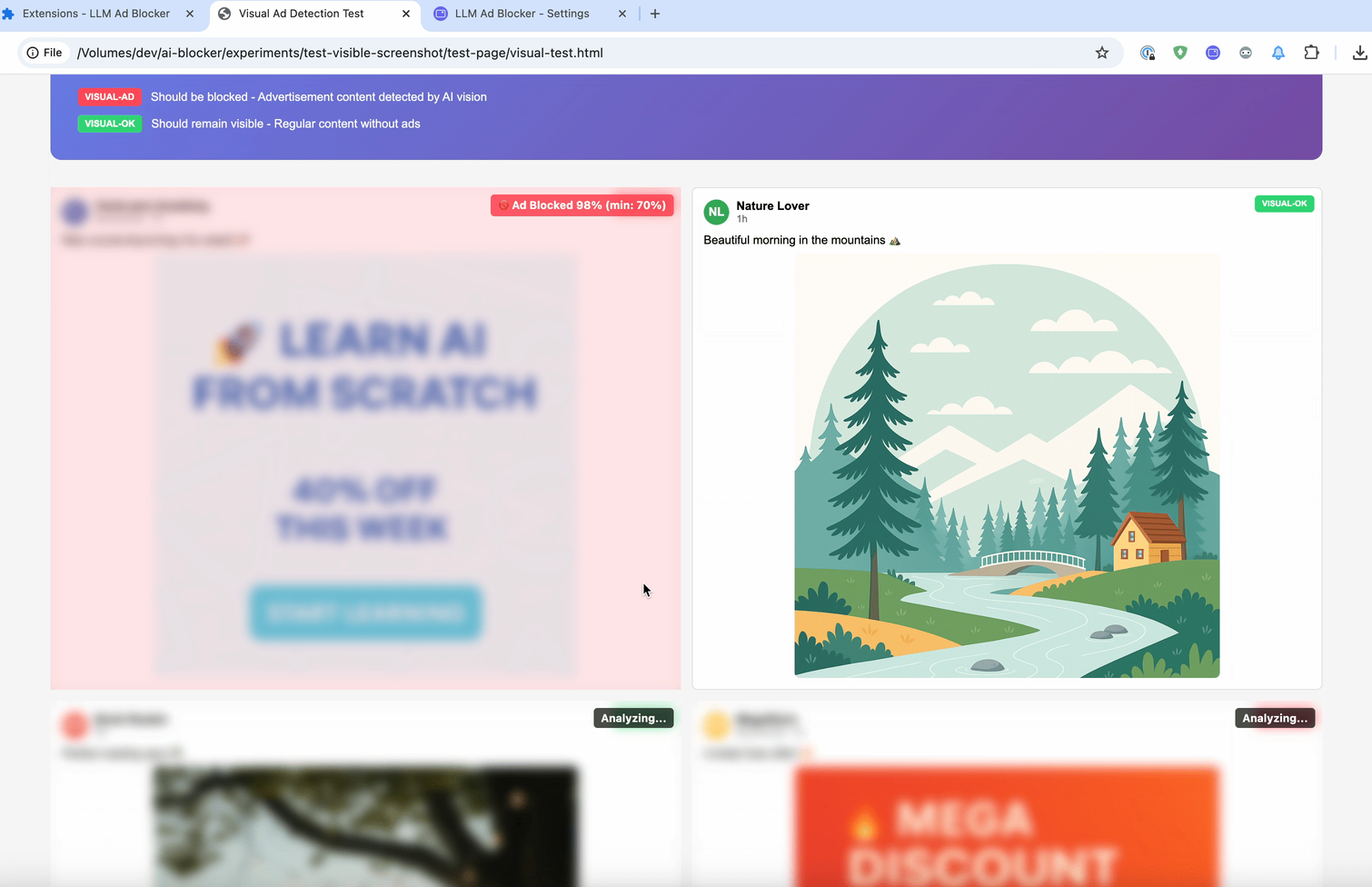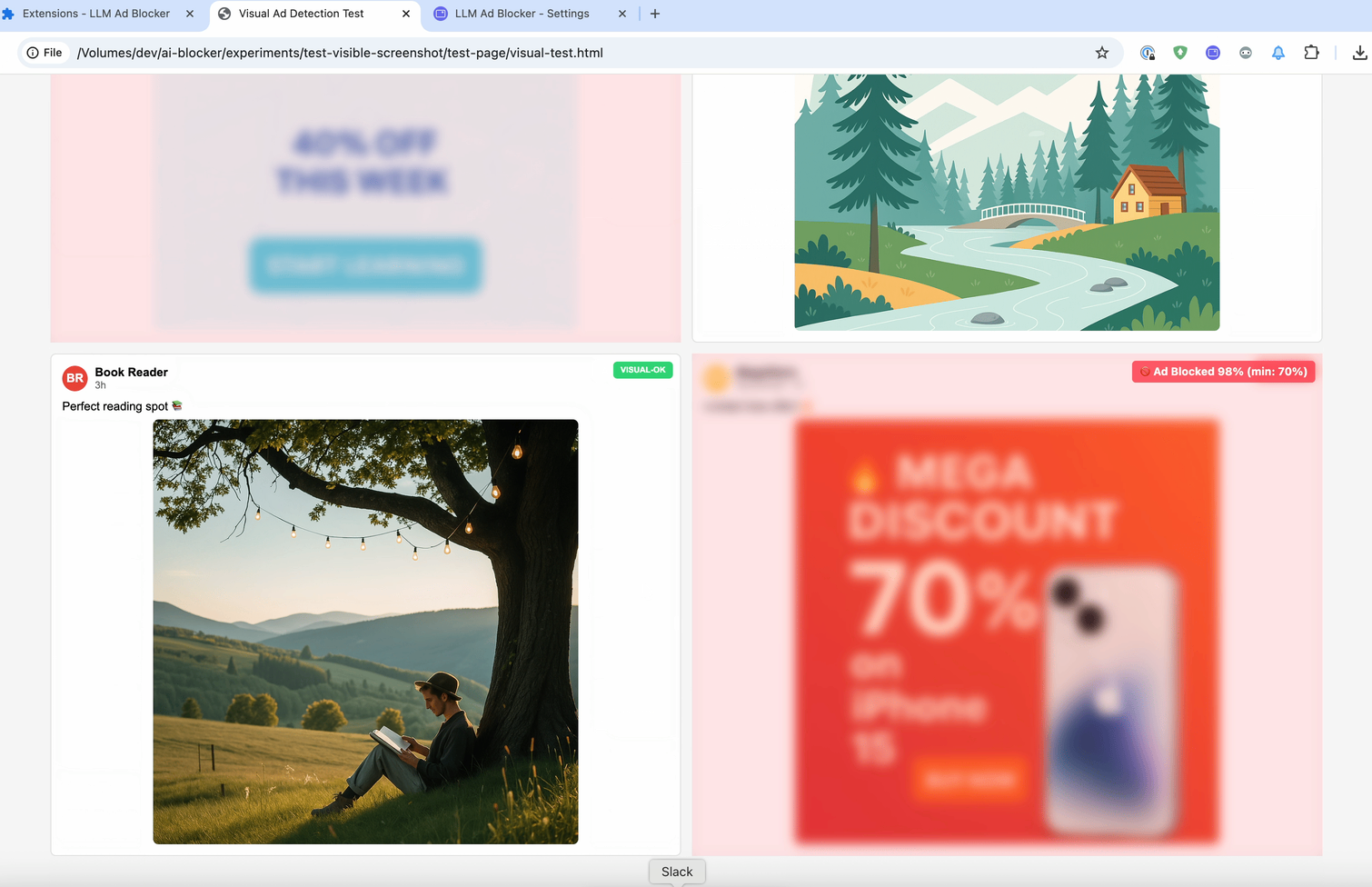
Les publications contiennent souvent très peu de texte. Voici un exemple illustrant précisément ce problème : une publication Facebook contenant presque aucun texte, juste une image.
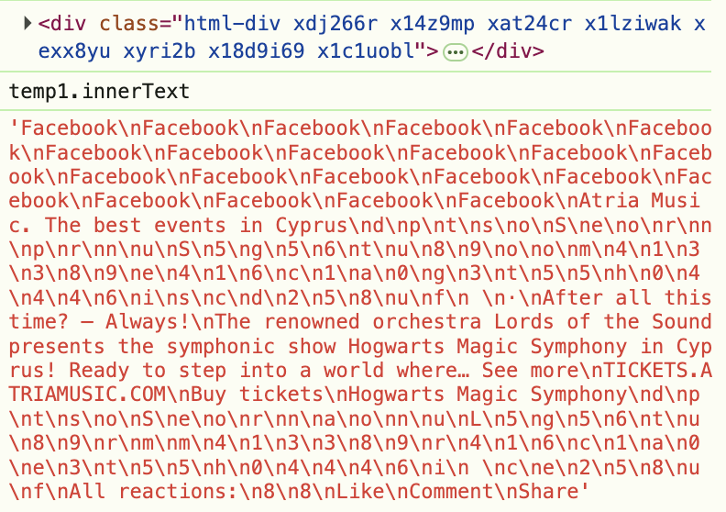
Mais cela ne concerne pas uniquement les publications sans texte. Même lorsque du texte est présent, les sites web le masquent à l'aide d'un code HTML obscurci. Par exemple, regardez cette capture d'écran provenant des outils de développement : vous pouvez voir que la mention « Sponsored » (Sponsorisé) est masquée dans un code HTML aléatoire.
C'est pourquoi nous devons cesser d'analyser le code et commencer à analyser ce que les utilisateurs voient réellement. L'idée est donc similaire à celle de la première expérience, mais cette fois-ci, nous n'analysons pas le code derrière l'élément, mais ce que les utilisateurs voient réellement sur la page. Prenons donc une capture d'écran de la publication, envoyons-la à un LLM doté de capacités visuelles et demandons-lui s'il s'agit de politique.
Ça a encore marché ! L'idée de base a été prototypée en seulement une heure environ. Mais ensuite est venu le véritable défi : prendre des captures d'écran via une extension de navigateur s'est avéré être un cauchemar.
Je vais vous expliquer pourquoi. Une approche que j'ai essayée était l'API Debugger. L'API Debugger vous permet de capturer n'importe quel élément, même en dehors de la fenêtre d'affichage (la zone actuellement visible à l'écran), mais elle provoque un scintillement de la page, ce qui peut être gênant pour les utilisateurs. Voir la démo ci-dessous :
L'autre approche consistait à utiliser chrome.tabs.captureVisibleTab, l'API standard de l'extension Chrome pour les captures d'écran. Celle-ci ne provoque aucun scintillement. Cependant, elle ne peut capturer que ce qui est actuellement visible dans la fenêtre d'affichage, et Chrome limite le nombre de captures d'écran que vous pouvez prendre par seconde.
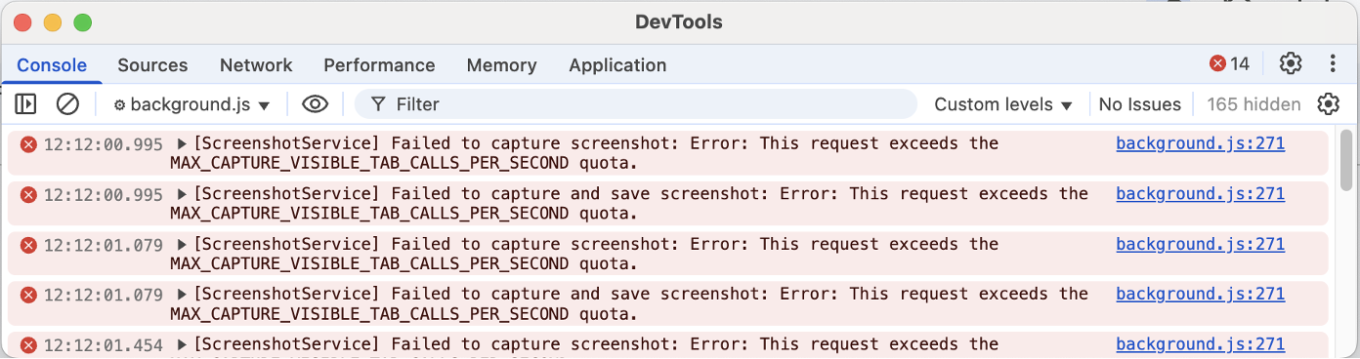
Ainsi, si vous avez plusieurs éléments à analyser, vous devez attendre et vous ne pouvez vérifier que les publications qui sont déjà à l'écran.
Ces expériences ont montré que les LLM peuvent analyser les publications et décider de les bloquer ou non. Cela signifie-t-il que nous pouvons remplacer entièrement les listes de filtres ? La réponse est non : nous en avons toujours besoin pour savoir quoi vérifier. Une page web comporte des milliers d'éléments, et les analyser tous serait lent et coûteux.
Expérience 3. Extension des listes de filtres : une nouvelle primitive
Si nous avons toujours besoin de savoir quels éléments vérifier, la démarche logique consiste à connecter les LLM aux listes de filtres et à généraliser la puissance des LLM en un outil réutilisable pour les auteurs de listes de filtres. Mais le problème ici est que l'écriture d'une nouvelle extension personnalisée pour chaque tâche sémantique n'est pas évolutive — nous avons besoin d'une solution plus générique.
L'inspiration : pseudo-classe CSS étendue, :contains.
La question : et si nous pouvions vérifier le sens, et pas seulement le texte ?
Le résultat : trois nouvelles pseudo-classes expérimentales :
selector:contains-meaning-embedding(“criteria”)
selector:contains-meaning-prompt(“criteria”)
selector:contains-meaning-vision(“criteria”)
Pour créer cette solution générique, je me suis inspiré de la bibliothèque CSS étendue d'AdGuard. Le CSS étendu est une bibliothèque JavaScript qui ajoute des pseudo-classes supplémentaires pour étendre les possibilités au-delà du CSS natif.
Elle dispose d'une pseudo-classe :contains() qui masque les éléments contenant un texte spécifique. J'ai décidé que nous pouvions améliorer cette approche afin de vérifier la signification sémantique plutôt que les mots-clés uniquement. Cela a donné naissance à trois prototypes : embedding, prompt et vision.
:contains-meaning-embedding
Fonctionnement : comparaison des similitudes entre le texte et les critères.
Avantages : très rapide et peu coûteux.
Inconvénients : nécessite la définition de seuils et pose des difficultés avec plusieurs langues.
Commençons par « :contains-meaning-embedding ». Cette règle utilise des modèles d'intégration qui transforment le texte en chiffres représentant sa signification. Nous calculons la similitude entre le texte de l'élément et les critères, puis déterminons s'ils correspondent. L'avantage est que cette méthode est rapide et peu coûteuse grâce à la mise en cache. L'inconvénient est qu'elle nécessite un réglage des seuils et peut poser des problèmes avec plusieurs langues.
:contains-meaning-prompt
Fonctionnement : demandez à LLM si le contenu correspond aux critères
Avantages : plus précis, pas de seuils, indépendant de la langue
Inconvénients : plus lent et plus coûteux
Vient ensuite « :contains-meaning-prompt ». Ces règles utilisent une API simple, dans laquelle nous demandons simplement si le contenu d'un élément correspond ou non aux critères. Cette méthode est plus précise, ne nécessite aucun seuil et fonctionne dans toutes les langues. L'inconvénient est qu'elle est plus lente et plus coûteuse que les intégrations.
:contains-meaning-vision
Fonctionnement : demande à LLM si la capture d'écran correspond aux critères.
Avantages : détecte les éléments que le texte et les intégrations ne permettent pas de voir.
Inconvénients : expérience utilisateur complexe.
La dernière méthode est :contains-meaning-vision. Elle prend des captures d'écran des éléments sélectionnés et demande aux LLM dotés de capacités visuelles si la capture d'écran correspond aux critères. Ensuite, elle fonctionne de la même manière que « :contains-meaning-prompt ». Le principal avantage de cette approche est qu'elle permet de détecter des contenus visuels que les méthodes basées sur le texte ne peuvent pas voir. L'inconvénient est une expérience utilisateur complexe avec un risque de clignotement de l'écran.
Ces trois règles peuvent donc fournir aux développeurs de filtres un outil flexible. Ils pourraient choisir entre la vitesse d'intégration, la précision du prompt ou la vision. Pour atténuer le retard d'analyse, une solution consiste à flouter les éléments dans un premier temps, puis à les déflouter ou à les garder masqués.
Analyse des performances et des coûts
Maintenant que nous disposons de ces trois prototypes, la question la plus importante se pose : sont-ils pratiques ? Peuvent-ils réellement fonctionner en production ? Pour y répondre, j'ai analysé les performances et les coûts de chaque approche.
Intégrations
Commençons par les intégrations. Au départ, j'ai commencé l'extension avec le modèle cloud d'OpenAI, et pour être honnête, les résultats n'étaient pas très bons. Mais j'ai ensuite décidé d'essayer un petit modèle local, et le résultat m'a surpris. Il était plus rapide, entièrement gratuit et atteignait une précision de 100 % lors de mes tests. Cela montre que pour certaines tâches, les petits modèles locaux peuvent en fait surpasser les grandes API cloud.

Prompts
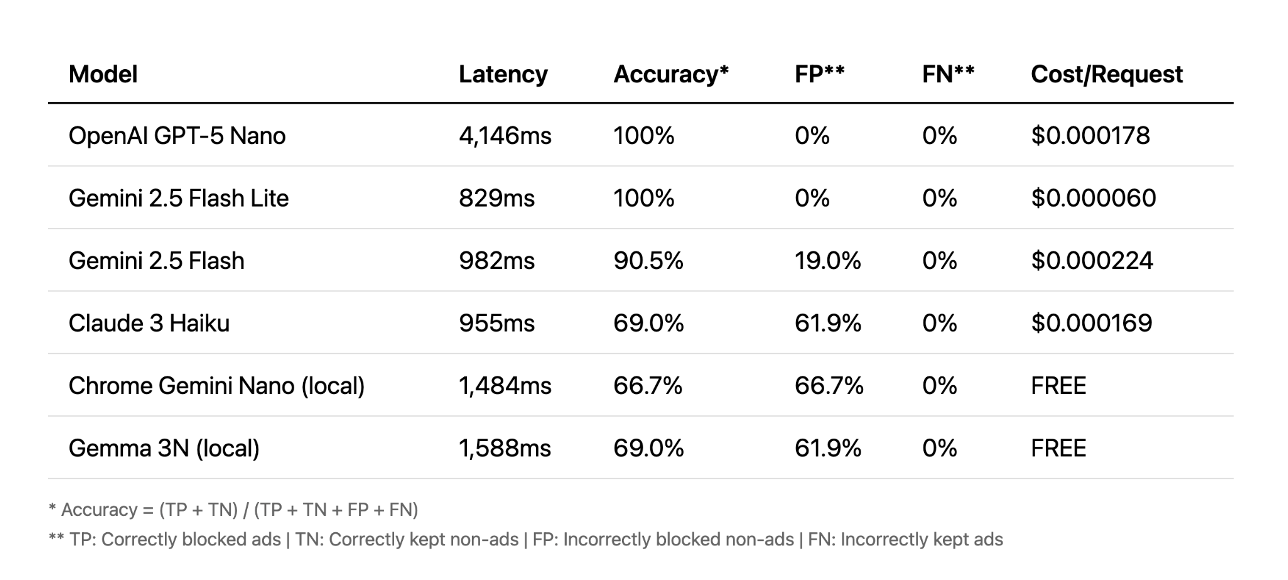
Passons maintenant aux prompts. Ici, le scénario est différent. Les API cloud ont obtenu les meilleurs résultats, certaines atteignant une précision de 100 % en moins d'une seconde. D'autres ont mis plus de quatre secondes, ce qui est beaucoup trop lent pour offrir une bonne expérience utilisateur. Dans ce cas, les modèles locaux n'ont tout simplement pas pu rivaliser avec la précision du cloud.
Vision
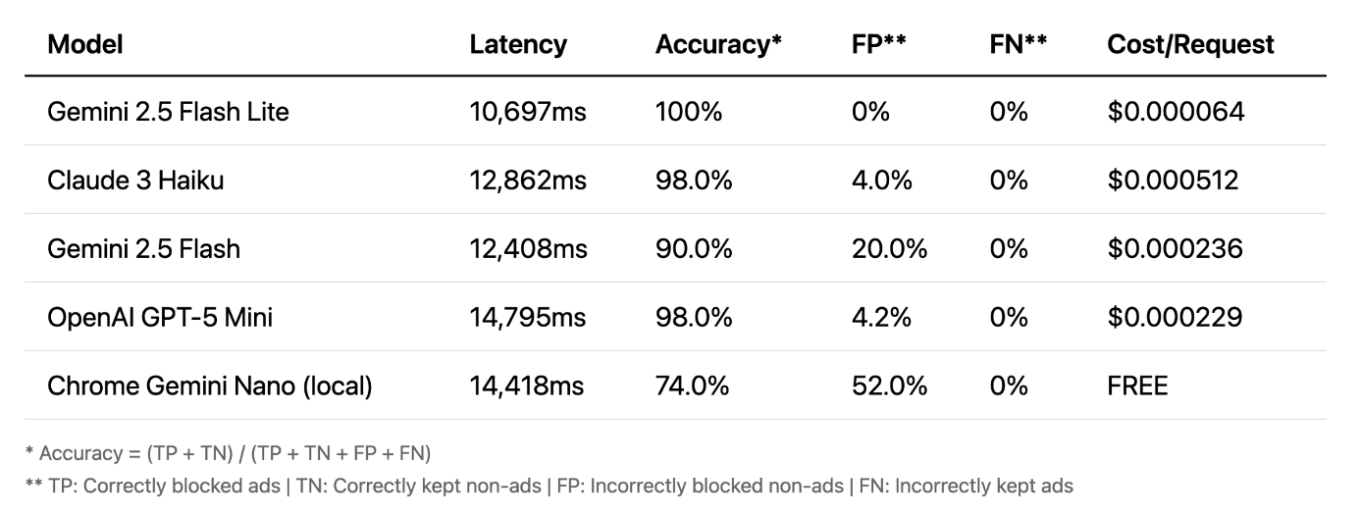
Enfin, parlons de la vision. C'est là que les choses deviennent vraiment intéressantes. La précision est très élevée, même les modèles locaux fonctionnent bien. La vision est souvent la méthode la plus précise. Son principal avantage est qu'elle fonctionne sur des images et non sur du texte, ce qui lui permet de détecter des publicités que d'autres méthodes ne voient pas. Cependant, il y a un inconvénient majeur : la latence. Un délai de 10 à 15 secondes n'est pas pratique pour le blocage en temps réel.
Comparaison des méthodes
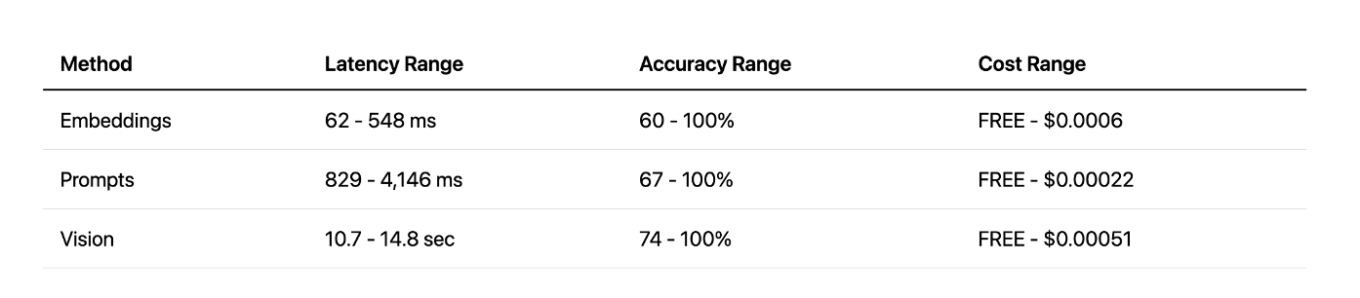
Lorsque l'on compare toutes les méthodes, la vision offre une grande précision, mais avec une latence très élevée. L'approche par invites offre un bon équilibre entre vitesse et précision, en particulier avec les API cloud. Et l'approche par intégrations locales a été une agréable surprise : très rapide et efficace, mais uniquement pour des tâches spécifiques. En fin de compte, chaque méthode a ses forces et ses faiblesses.
L'avenir de cette approche
Vision : trop lente pour l'instant, mais s'améliore avec le temps.
Intégrations : peu pratiques dans les extensions, seraient idéales si elles étaient intégrées aux navigateurs.
Invites LLM locales : expérimentales, nécessitent une meilleure précision.
Qu'est-ce que cela signifie pour l'avenir ? À mon avis, la vision est tout simplement trop lente pour l'instant. Les intégrations ne sont pas très pratiques si elles sont utilisées dans des extensions de navigateur, mais elles pourraient bien fonctionner en tant qu'API intégrée au navigateur. Et les invites LLM locales sont la voie la plus prometteuse pour une expérience réelle et exploitable avec l'API Prompt de Chrome. Il y a également le défi d'améliorer l'expérience utilisateur, car l'approche actuelle avec des éléments flous n'est pas idéale. Avec des modèles plus rapides, nous pourrions réduire le temps de flou, ou peut-être trouver une solution complètement différente.
Qu'avons-nous appris ? Tout d'abord, les LLM nous permettent d'aller au-delà de la simple correspondance de modèles et de comprendre réellement la signification du contenu web. Cela ouvre une approche sémantique totalement nouvelle du filtrage. Ensuite, les LLM nous permettent de réaliser rapidement des prototypes. Des idées qui nécessitaient auparavant des mois de développement peuvent désormais être testées en quelques heures. Bien qu'il reste des défis pratiques à relever, cette nouvelle approche nous permet de repenser ce qui est possible dans le domaine du filtrage de contenu.
J'espère que cela vous a donné une nouvelle façon d'envisager le filtrage de contenu. Vous pouvez essayer par vous-même tout ce dont j'ai parlé dans cet article : il vous suffit de télécharger AI AdBlocker depuis Chrome Store.
Le code source complet est également disponible sur GitHub. N'hésitez pas à me contacter si vous avez des questions ou des suggestions !















































