Além das lista de filtros: repensando o bloqueio de anúncios com LLMs
Um dos maiores obstáculos que os bloqueadores de anúncios vêm enfrentando de forma consistente durante toda a sua existência está profundamente ligado à sua própria natureza — são as limitações das listas de filtros e a necessidade de mantê-las. Essa manutenção é, na maioria dos casos, manual e extremamente trabalhosa.
Nesta pesquisa, vou explorar como o bloqueio de anúncios funciona atualmente e revisar tentativas anteriores de automatizá-lo aplicando aprendizado de máquina. Em seguida, apresentarei meus próprios experimentos de adicionar LLM ao bloqueio de anúncios, discutirei para onde essa abordagem está caminhando e até mostrarei a extensão de navegador protótipo funcional que você pode baixar e testar por conta própria.
E embora eu saiba que você provavelmente esteja ansioso para ouvir sobre os experimentos com LLM e conferir a extensão — primeiro, vamos contextualizar com algumas informações.
Como o bloqueio de anúncios funciona hoje
No núcleo de todos os bloqueadores de anúncios estão as listas de filtros, mantidas pela comunidade. Essas listas consistem em milhares de regras que se dividem em duas categorias principais: regras de rede e regras cosméticas.
Regras de Rede: a primeira linha de defesa
Ações: Bloquear, redirecionar ou modificar requisições.
Exemplo: ||evil-ads.com^ — esta regra bloqueia o site evil-ads.com e seus subdomínios.
As regras de rede bloqueiam requisições a servidores de anúncios de terceiros antes mesmo do conteúdo chegar ao seu navegador. É uma abordagem rápida e eficiente. Essas regras podem bloquear, redirecionar ou modificar requisições.
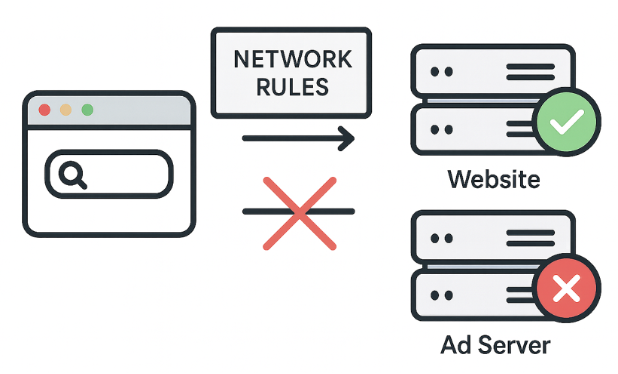
Mas as regras de rede não conseguem bloquear tudo. Por exemplo, alguns anúncios são servidos a partir do mesmo domínio do conteúdo, então bloqueá-los no nível de rede quebraria o site. É aí que entram as regras cosméticas.
Regras Cosméticas: limpando a página
Ações: Usar seletores CSS para ocultar elementos indesejados diretamente na página ou aplicar estilos personalizados.
Exemplo: example.com##.ad-banner — oculta elementos com a classe “ad-banner” em example.com.
CSS (Cascading Style Sheets) é uma linguagem de folhas de estilo que define como documentos HTML ou XML são apresentados visualmente. Ela especifica como os elementos devem aparecer na tela do seu dispositivo.
As regras cosméticas basicamente limpam elementos de anúncios restantes que regras de rede mais simples não conseguem bloquear.
Além do CSS: regras de Scriptlet
Ações: Modificar ou desativar funcionalidades específicas de scripts na página.
Exemplo: example.com#%#//scriptlet('abort-on-property-read', 'alert') — impede que um script em example.com acesse um recurso específico do navegador, como alert.
Quando o CSS não é suficiente para lidar com scripts complexos — como a reinserção de anúncios — usamos scriptlets. Scriptlets são pequenos trechos de JavaScript injetados pelos bloqueadores de anúncios para neutralizar comportamentos indesejados.
Os scriptlets se tornaram a ferramenta favorita dos desenvolvedores de filtros porque resolvem problemas que CSS e regras de rede não conseguem.
O poder e os limites
Vimos rapidamente como as listas de filtros funcionam. Elas são poderosas e funcionam muito bem para padrões conhecidos, mas também têm algumas limitações. Têm dificuldade com publicidade nativa, exigem atualizações constantes e, no Manifest v3, essas atualizações se tornam mais difíceis.
Essas limitações levam a uma pergunta fundamental: e se pudéssemos eliminar totalmente as listas de filtros? E se o próprio bloqueador de anúncios pudesse decidir o que bloquear por conta própria?
Imagine — sem filtros, sem atualizações, sem correr atrás das redes de anúncios. Sem ajustes manuais e sem o jogo de gato e rato. No final das contas, isso não é exatamente o que os usuários esperam naturalmente de um bloqueador de anúncios? “Instale e esqueça”, aproveitando a web limpa sem precisar se preocupar com o bloqueador. E é exatamente isso que os primeiros experimentos com aprendizado de máquina buscavam alcançar.
Com essa motivação em mente, vamos ver como empresas e pesquisadores tentaram usar aprendizado de máquina para resolver esses problemas.
Uma breve história do machine learning no bloqueio de anúncios
Vamos dar uma olhada em várias tentativas passadas de substituir as listas de filtros pelo aprendizado de máquina. Isso nos ajudará a entender por que isso ainda não aconteceu, pelo menos não completamente.
Project Moonshot da eyeo
Objetivo: Automatizar o bloqueio cosmético em larga escala.
Método:
- Treinou um modelo de ML baseado na estrutura da página (DOM, HTML, CSS)
- Usou listas de filtros existentes para rotulagem
- Analisou páginas diretamente dentro da extensão do navegador
O Project Moonshot da eyeo foi apresentado no Ad-Filtering Dev Summit em 2021. Eles treinaram um modelo usando a estrutura da página e listas de filtros como rótulos. O modelo rodava dentro da extensão do navegador para prever e ocultar elementos de anúncios. Funcionou, mas enfrentou desafios: dados desbalanceados, dificuldades de implementação e necessidade constante de re-treinamento.
Ideia principal: Decisões baseadas na estrutura da página, não em imagens.
Resultado: Previa e ocultava elementos de anúncios, complementando o bloqueio de rede.
Desafios: Desbalanceamento de dados, dificuldades de implementação e necessidade de re-treinamento constante.
AdGraph da Brave
Objetivo: Bloquear anúncios e trackers em tempo real.
Método:
- Construiu um grafo conectando todas as atividades da página (DOM, rede, JavaScript)
- Classificou o conteúdo com base no contexto dentro do grafo
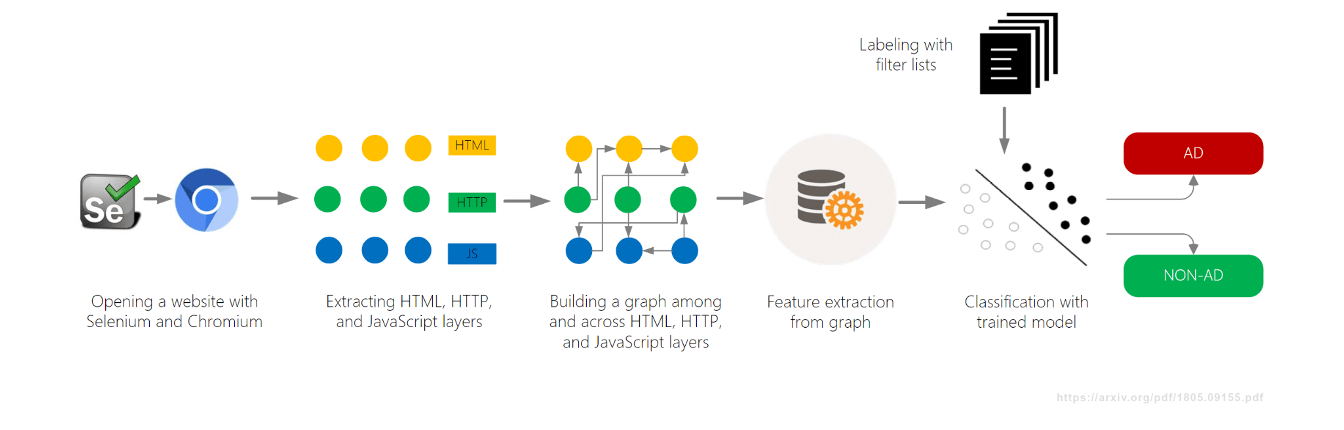
Outro projeto de aprendizado de máquina, AdGraph, foi desenvolvido pelo Brave Browser e apresentado em 2019, também no AFDS. Eles construíram um grafo que rastreava como tudo em uma página se conecta — DOM, rede, JavaScript — e depois classificavam os recursos com base no contexto.
O AdGraph alcançou alta precisão ao rastrear scripts de volta aos servidores de anúncios, mesmo com nomes aleatórios. Mas exigia integração profunda com o navegador e manutenção constante.
Ideia principal: Decisões baseadas em causalidade, não apenas em padrões estáticos de URL.
Resultado: Precisão muito alta (~95–98%) e robustez contra ofuscação.
Desafios: Necessidade de integração profunda com o navegador e manutenção constante.
PERCIVAL da Brave
Objetivo: Bloquear imagens de anúncios em tempo real.
Método:
- Usou uma rede neural compacta (CNN) para classificar imagens
- Incorporou diretamente na pipeline de renderização de imagens do navegador
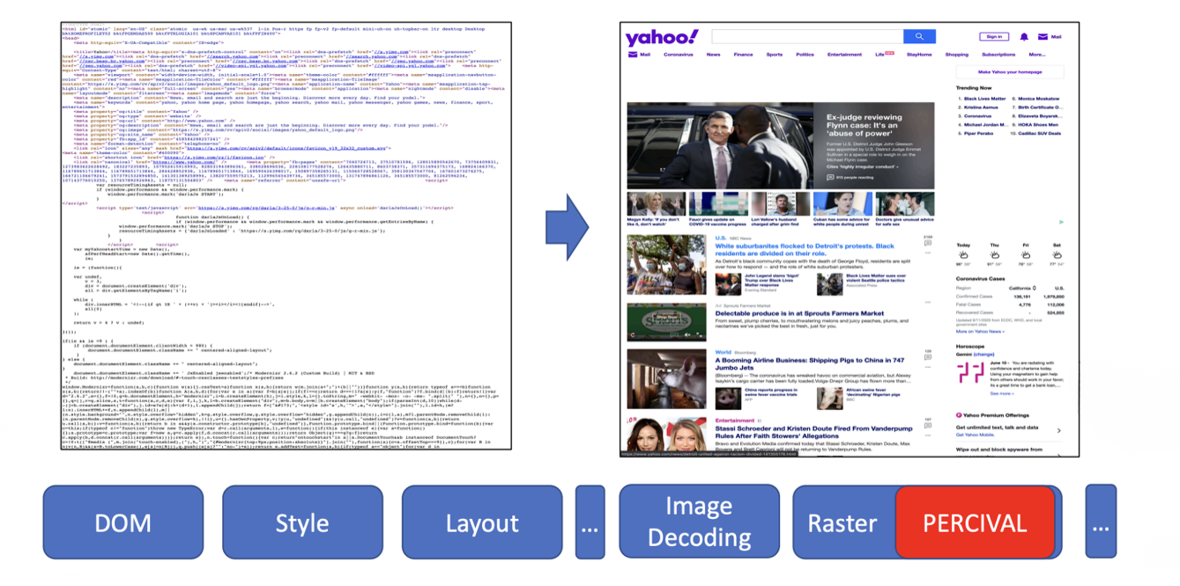
Em 2020, a Brave apresentou outra abordagem de aprendizado de máquina chamada PERCIVAL, focada em bloquear imagens de anúncios. Eles incorporaram uma rede neural compacta diretamente na pipeline de renderização do navegador para classificar imagens enquanto eram carregadas. Os resultados foram impressionantes: alcançaram 97% de precisão analisando o conteúdo visual das imagens. Mas também tinha limitações — era vulnerável a imagens adversariais e só funcionava para anúncios em imagem.
Ideia principal: Analisar o conteúdo visual da imagem, não apenas a URL ou metadados.
Resultado: ~97% de precisão com baixo impacto na renderização.
Desafios: Vulnerável a imagens adversariais; limitado a anúncios baseados em imagem.
AutoFR (pesquisa acadêmica)
Objetivo: Gerar automaticamente regras de filtro do zero.
Método:
- Usou aprendizado por reforço (sistema de tentativa e erro) para testar regras
- Analisou o conteúdo da página para evitar quebrar o site
Além dos esforços da indústria, pesquisadores acadêmicos também buscaram soluções melhores. Um projeto interessante foi o AutoFR, que tinha como objetivo gerar regras de filtro automaticamente.
O AutoFR foi apresentado por Hieu Van Le no AFDS 2022 e AFDS 2023.
Ele gera padrões de URL e seletores CSS, testa-os e aprende com os resultados, evitando quebrar o site. Os resultados foram bastante impressionantes: o AutoFR atingiu 86% de eficácia (comparado ao EasyList), com regras geradas em minutos.
Ideia principal: Geração automatizada de regras com consciência de quebra do site.
Resultado: ~86% de eficácia no bloqueio; regras geradas em minutos.
SINBAD (pesquisa acadêmica)
Objetivo: Detectar e identificar quebras de site causadas pelo bloqueio de anúncios.
Método:
- Usou “saliency web” para identificar elementos visuais importantes
- Comparou versões da página com e sem bloqueador para identificar o que quebrou
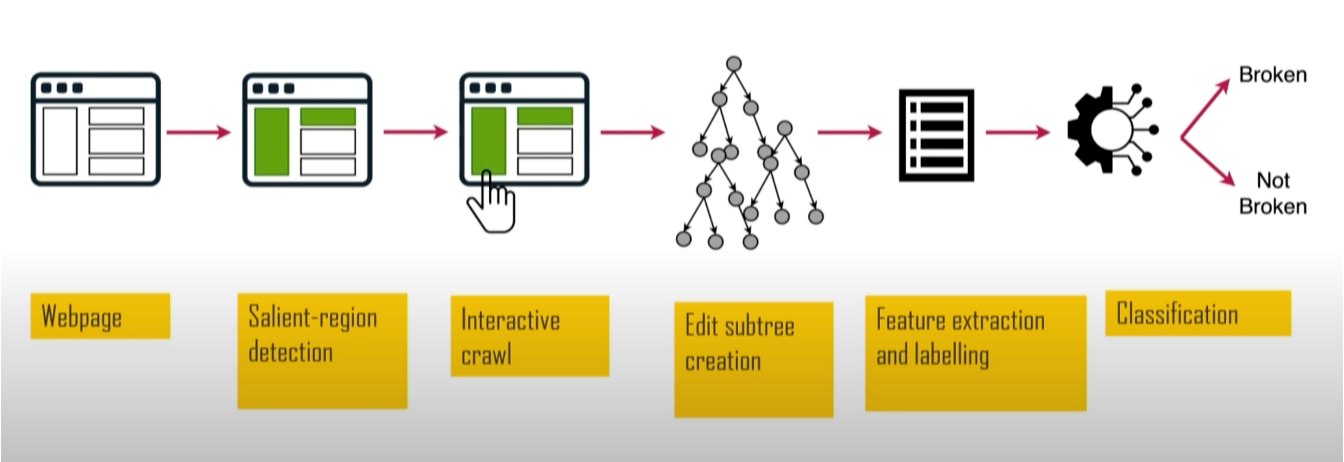
Outro projeto acadêmico foi o SINBAD. Ele se concentrou em detectar quando regras de filtro quebram sites. Esse projeto foi valioso porque a quebra de sites é uma das principais razões pelas quais os usuários abandonam bloqueadores de anúncios. Foi apresentado no AFDS 2023 por Sandra Siby do Imperial College London (na época).
Analisando tamanho, posição e contraste, ele identifica elementos visualmente proeminentes, como títulos e botões, e depois testa se houve quebra. O SINBAD atingiu alta precisão na detecção de quebras, com relatórios específicos mostrando exatamente o que quebrou e quais regras causaram o problema.
Ideia principal: Focar no impacto visível ao usuário para encontrar e corrigir problemas mais rapidamente.
Resultado: Maior precisão na detecção de quebras, com relatórios específicos e acionáveis.
Resumo: por que o ML não dominou
Então, vimos todos esses experimentos e projetos de pesquisa. Mas aqui está o ponto — apesar de todo esse trabalho, nenhuma dessas ferramentas baseadas em aprendizado de máquina ganhou adoção ampla. Então seria lógico perguntar: por que o aprendizado de máquina não substituiu os filtros?
Existem várias razões:
- Alto padrão: Listas de filtros curadas por humanos são extremamente eficazes e maduras. Igualá-las em eficácia não é tarefa simples.
- Alto custo: Criar e manter grandes conjuntos de dados de alta qualidade é caro, enquanto a maioria das listas de filtros é mantida pela comunidade gratuitamente.
- Evasão: Modelos especializados podem ser vulneráveis a ataques adversariais.
Portanto, como se constatou, construir modelos especializados do zero é lento, caro e inflexível. É por isso que a abordagem de ML ainda não decolou, e ainda dependemos das boas e velhas listas de filtros. Mas isso está prestes a mudar?
Entram os LLMs: grandes, caros… mas diferentes
E é aqui que entram os Large Language Models (LLMs), começando a mudar o mundo. Será que eles também podem mudar o bloqueio de anúncios? Vamos explorar como os LLMs podem ser usados para bloqueio de anúncios em extensões de navegador. Mas primeiro, deixe-me rapidamente apresentar algumas características-chave que definem os LLMs.
Repensando o bloqueio com LLMs: O poder do protótipo rápido
Large Language Models (LLMs) ainda são um desenvolvimento recente, mas seu progresso tem sido notavelmente rápido. Agora estão amplamente acessíveis via APIs, permitindo que desenvolvedores integrem capacidades baseadas em LLM em seus produtos com esforço mínimo. Muitos modelos vêm em versões baseadas na nuvem e também locais, dando flexibilidade aos usuários conforme suas necessidades.
As capacidades dos LLMs vão desde gerar texto de alta qualidade até analisar dados, criar imagens e vídeos, escrever código e apoiar fluxos de trabalho complexos. Isso os torna valiosos em muitas indústrias e em demanda por milhões de pessoas. Mas nem tudo são flores — ao mesmo tempo, executar ou acessar esses modelos pode ser caro, especialmente em larga escala, o que representa um problema real na adoção de LLMs em muitas áreas.
Mas o mais importante é que os LLMs permitem testar ideias muito rapidamente. Então, finalmente, vou mostrar meus experimentos aplicando LLMs ao bloqueio de anúncios em extensões de navegador.
Experimento 1: bloqueio por significado
A ideia do meu primeiro experimento foi ver se um LLM poderia distinguir diferentes tipos de conteúdo em tempo real.
A ideia:
- Desfocar posts imediatamente
- LLM analisa o conteúdo
- Revelar se é seguro ou manter desfocado se não for
Decidi testar no feed do X. Pegava o código de cada post e enviava para um LLM, perguntando se era sobre política. Como os LLMs são um pouco lentos, desfocava todos os posts imediatamente, analisava-os com a ajuda do LLM e depois revelava os seguros.
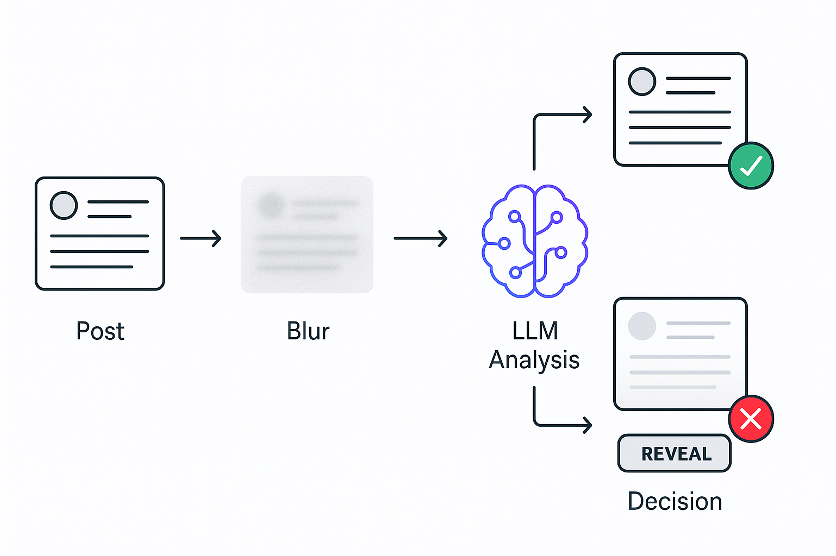
E funcionou!
O que prova que uma nova forma semântica de filtrar conteúdo é possível. E prototipei toda a extensão em apenas algumas horas — algo que teria levado meses com aprendizado de máquina tradicional.
Veja uma rápida demonstração:
Aqui você pode ver como funciona. O post aparece, desfoca imediatamente, o LLM analisa e depois revela se for seguro ou mantém oculto se não for. Usuários podem revelar manualmente qualquer post desfocado.
Enquanto experimentava no X, notei que alguns posts não eram bloqueados porque eram majoritariamente imagens. Isso me levou ao segundo experimento.
Experimento 2: bloqueio por significado visual
Neste experimento, vou ensinar o bloqueador a “ver”.
A ideia:
- Desfocar posts imediatamente
- LLM com visão analisa o screenshot do post
- Revelar se for seguro ou manter desfocado se não for
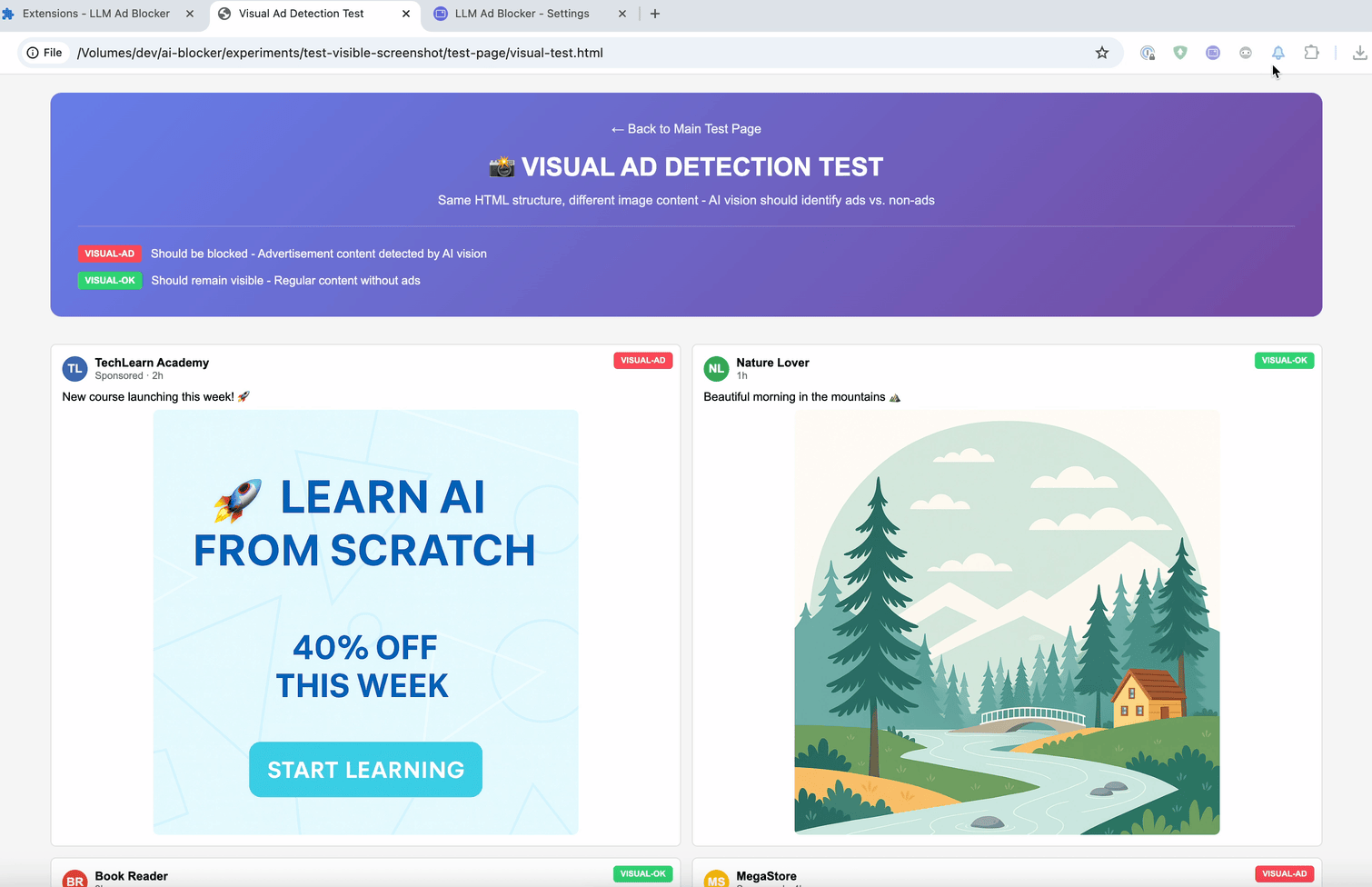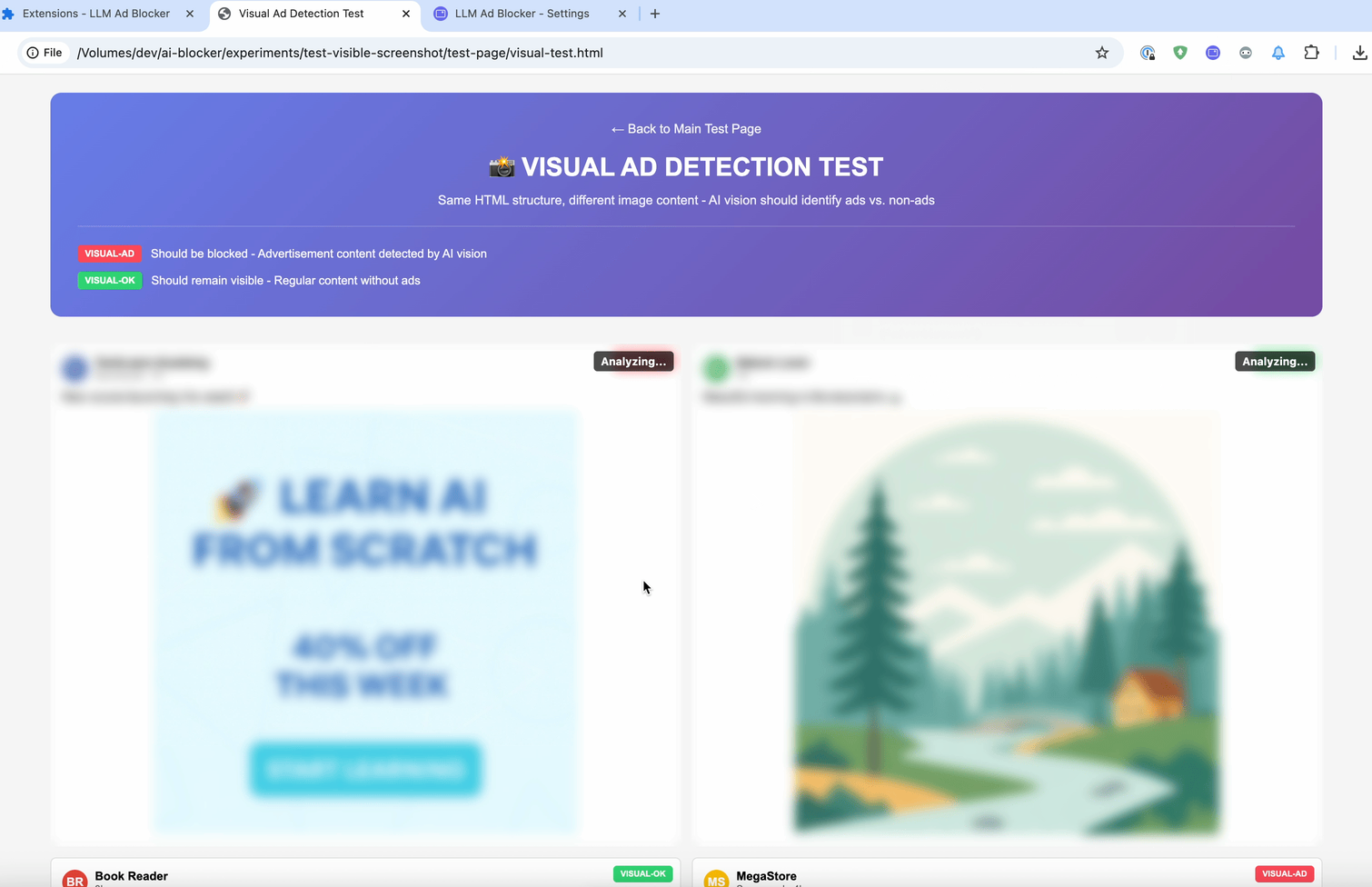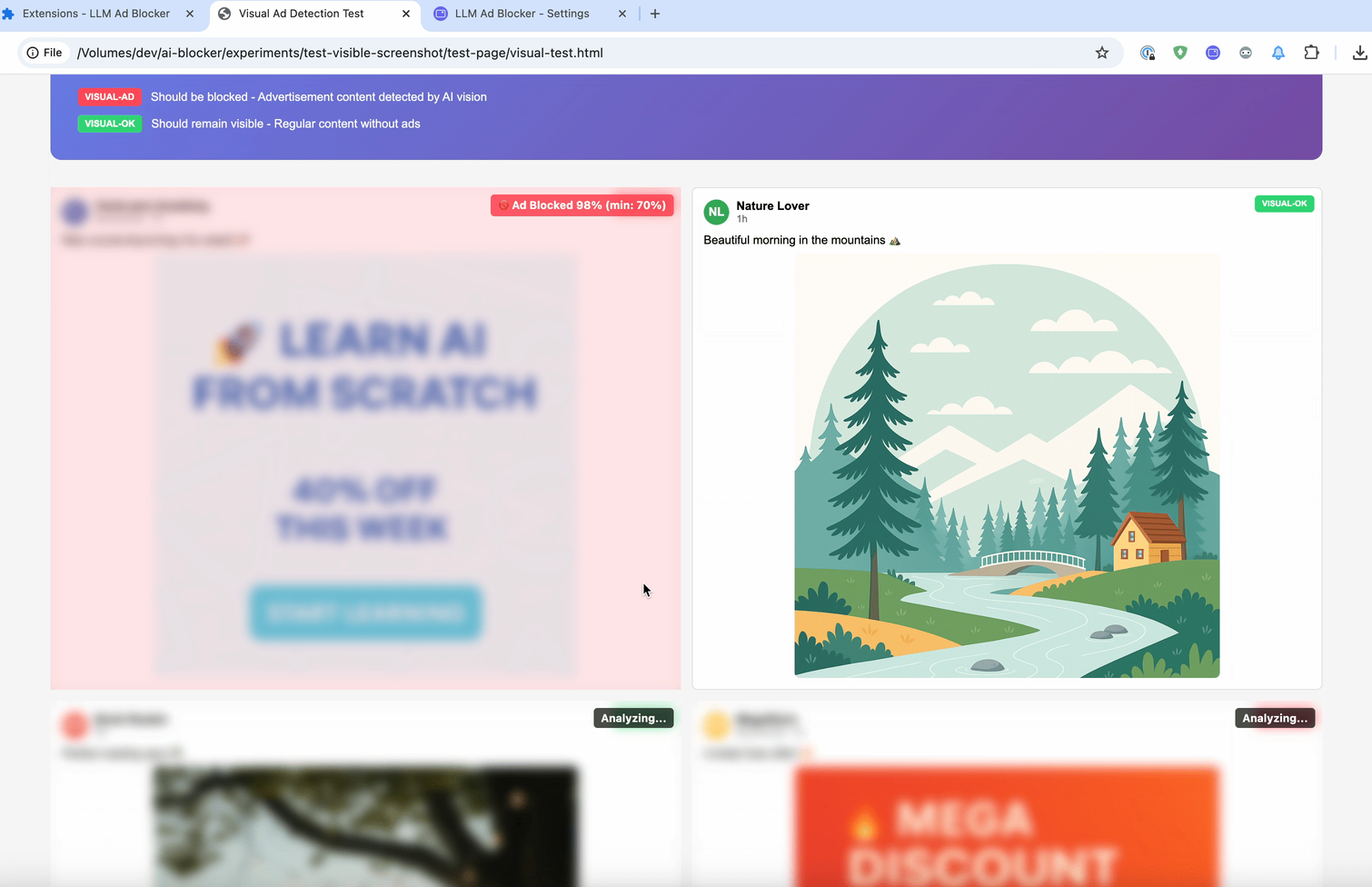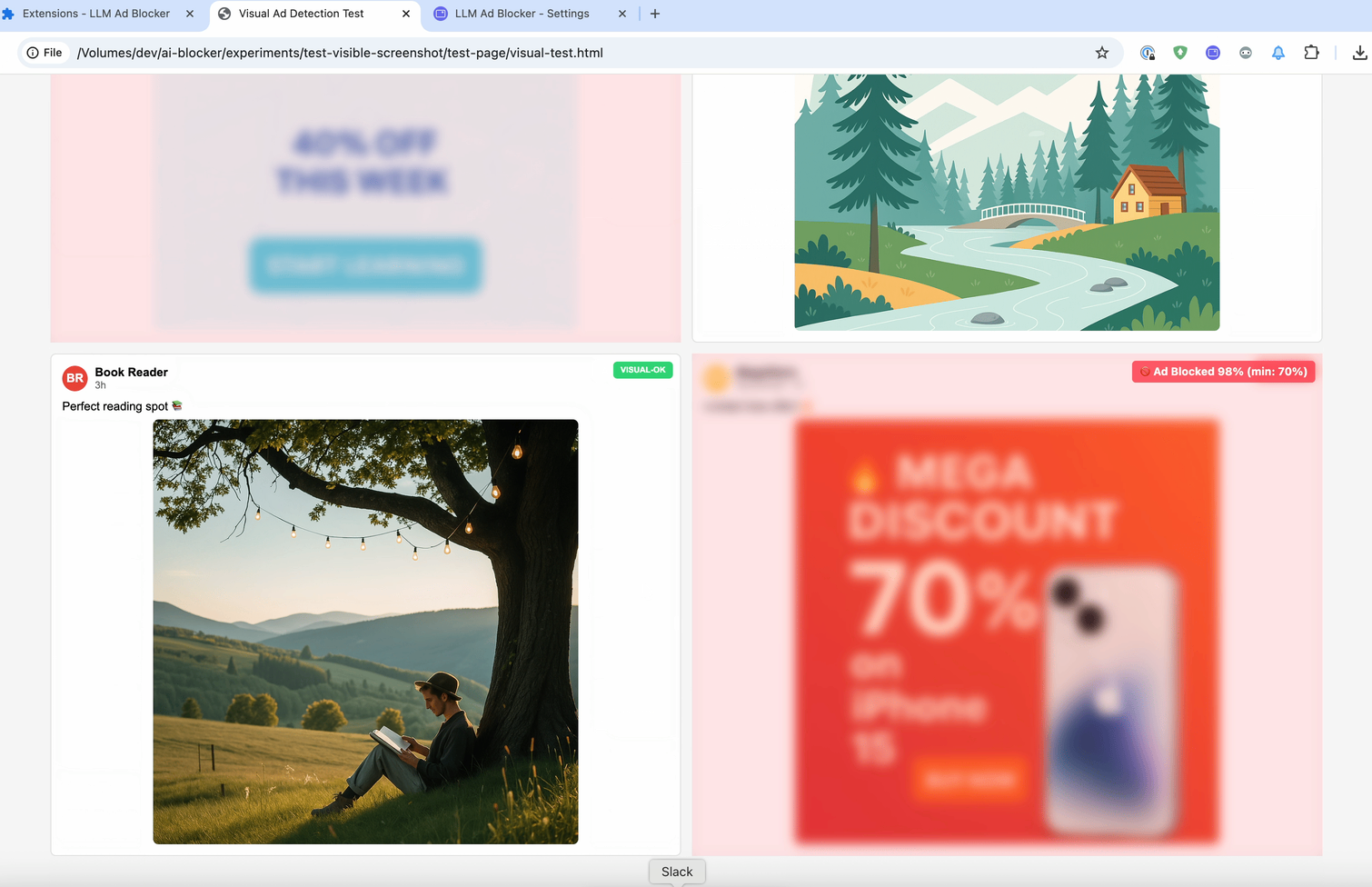
Os posts frequentemente têm quantidade mínima de texto. Aqui está um exemplo desse problema — um post do Facebook com quase nenhum texto, apenas uma imagem.
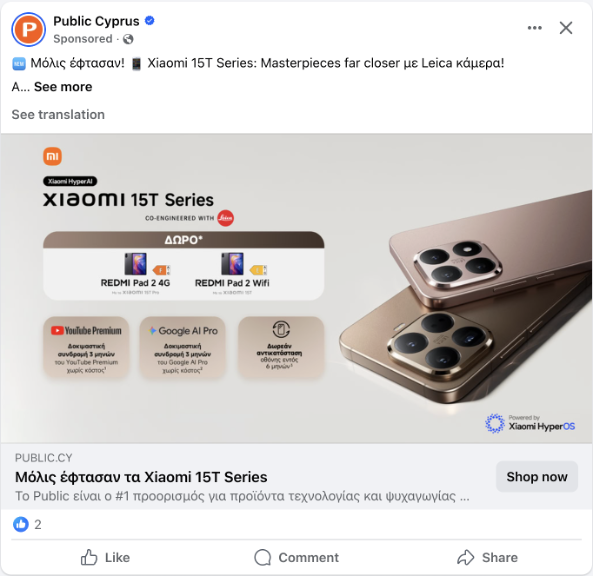
Mas não se trata apenas de posts sem texto. Mesmo quando há texto, sites o escondem usando HTML ofuscado. Por exemplo, veja este screenshot das ferramentas de desenvolvedor — o rótulo “Patrocinado” está escondido em HTML aleatório.
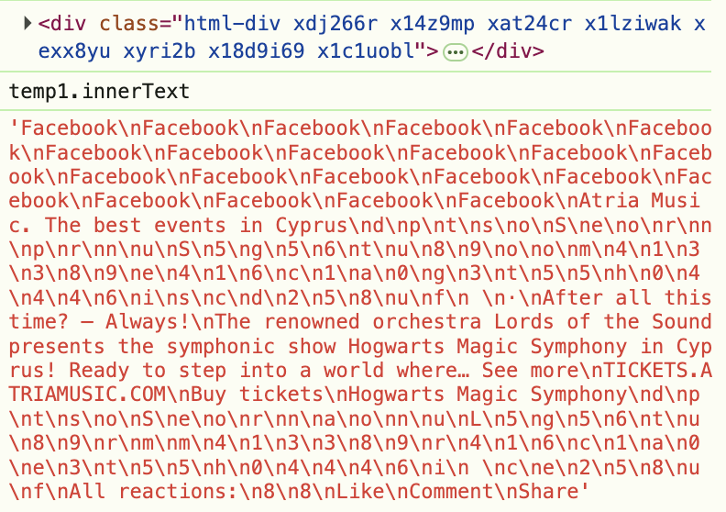
Por isso, devemos parar de analisar o código e começar a analisar o que os usuários realmente veem. A ideia é semelhante ao primeiro experimento, mas agora analisamos não o código, e sim o que o usuário vê na página. Então, tiramos um screenshot do post, enviamos para um LLM com visão e perguntamos se é sobre política.
Funcionou novamente! A ideia central foi prototipada em cerca de uma hora. Mas aí veio o verdadeiro desafio — tirar screenshots através de uma extensão de navegador revelou-se um pesadelo.
Deixe-me explicar por quê. Uma abordagem que tentei foi a Debugger API. A Debugger API permite capturar qualquer elemento, mesmo fora do viewport (a área visível da tela), mas faz a página piscar, o que pode ser incômodo para os usuários. Veja a demonstração abaixo:
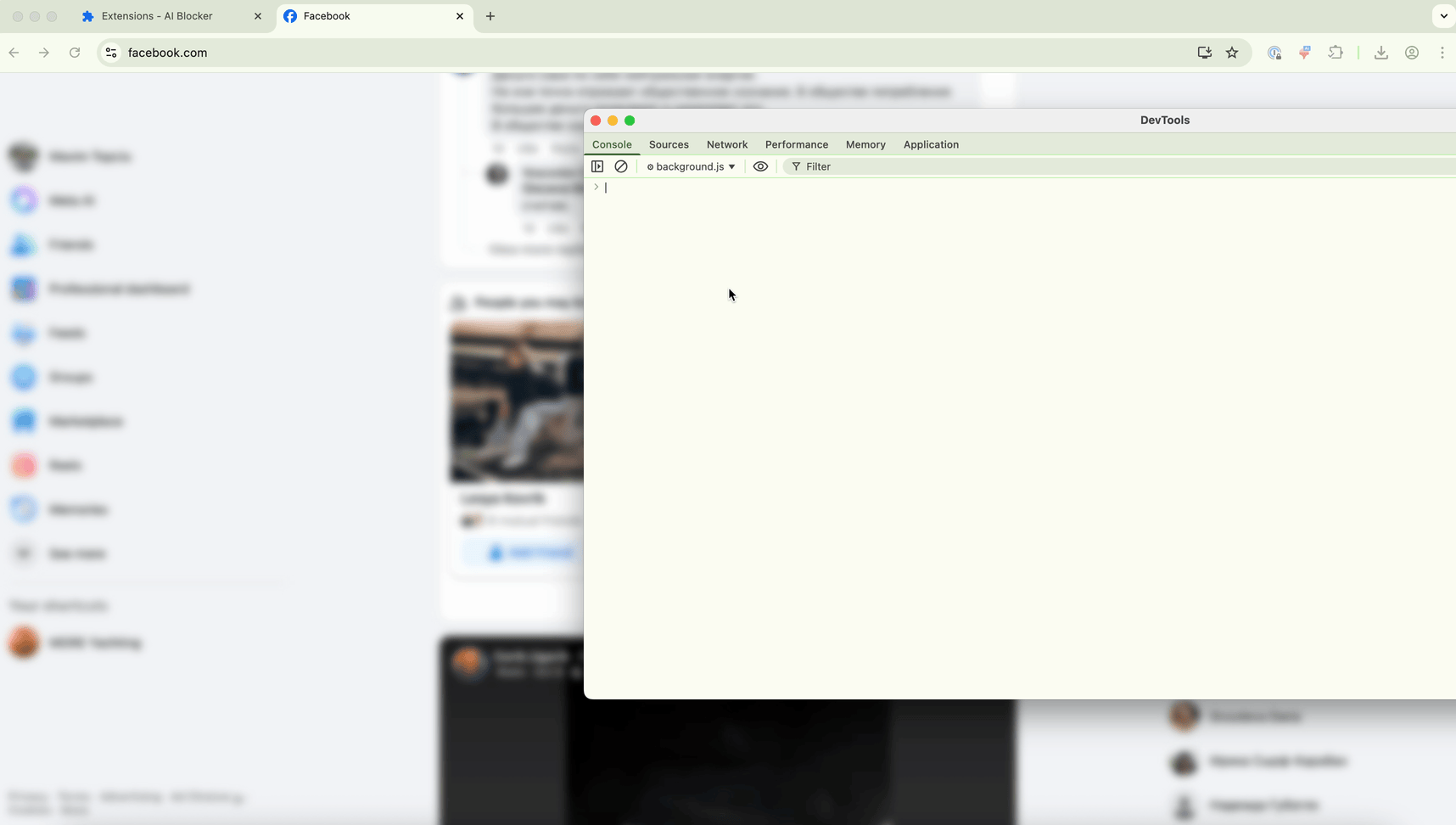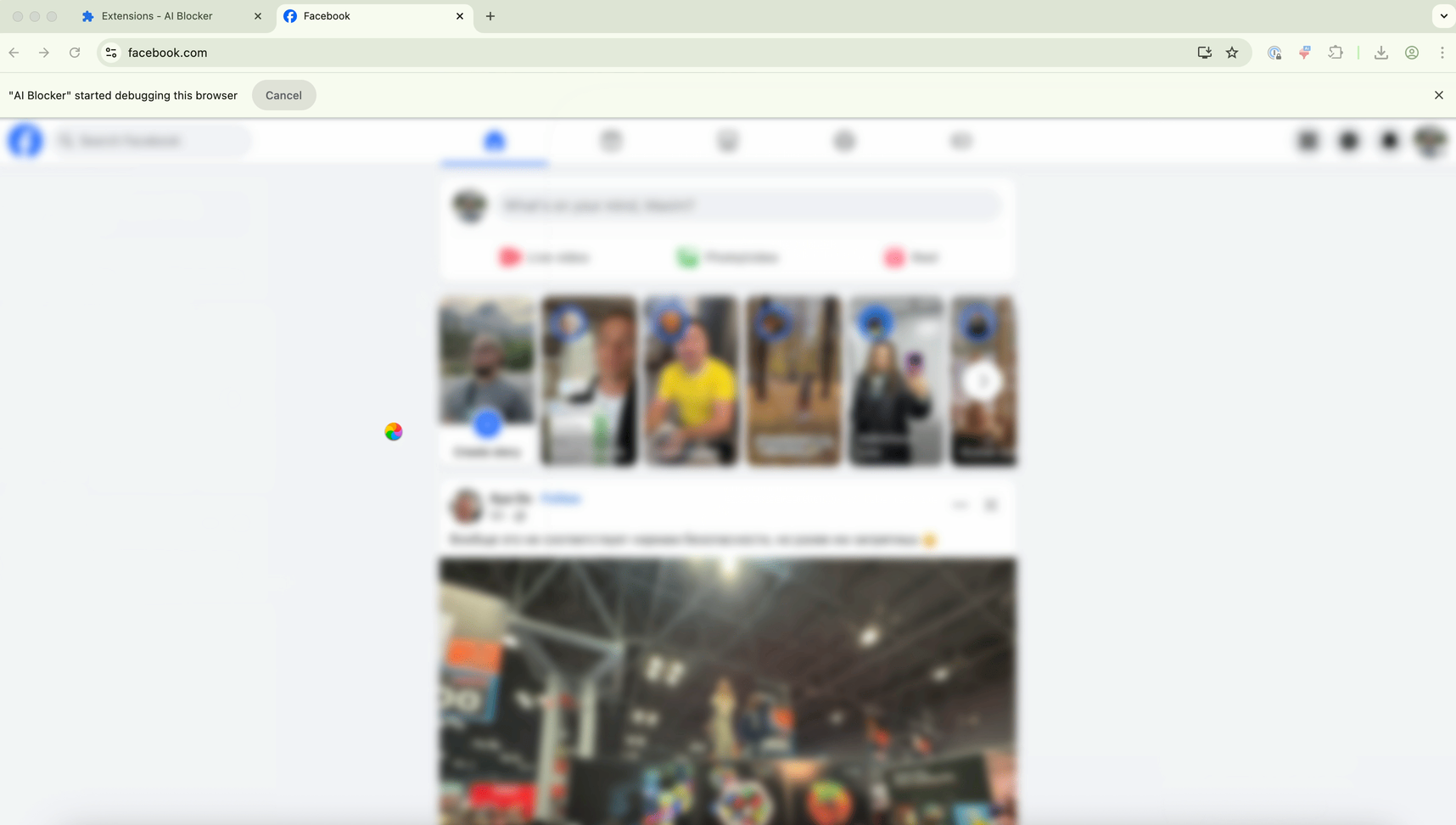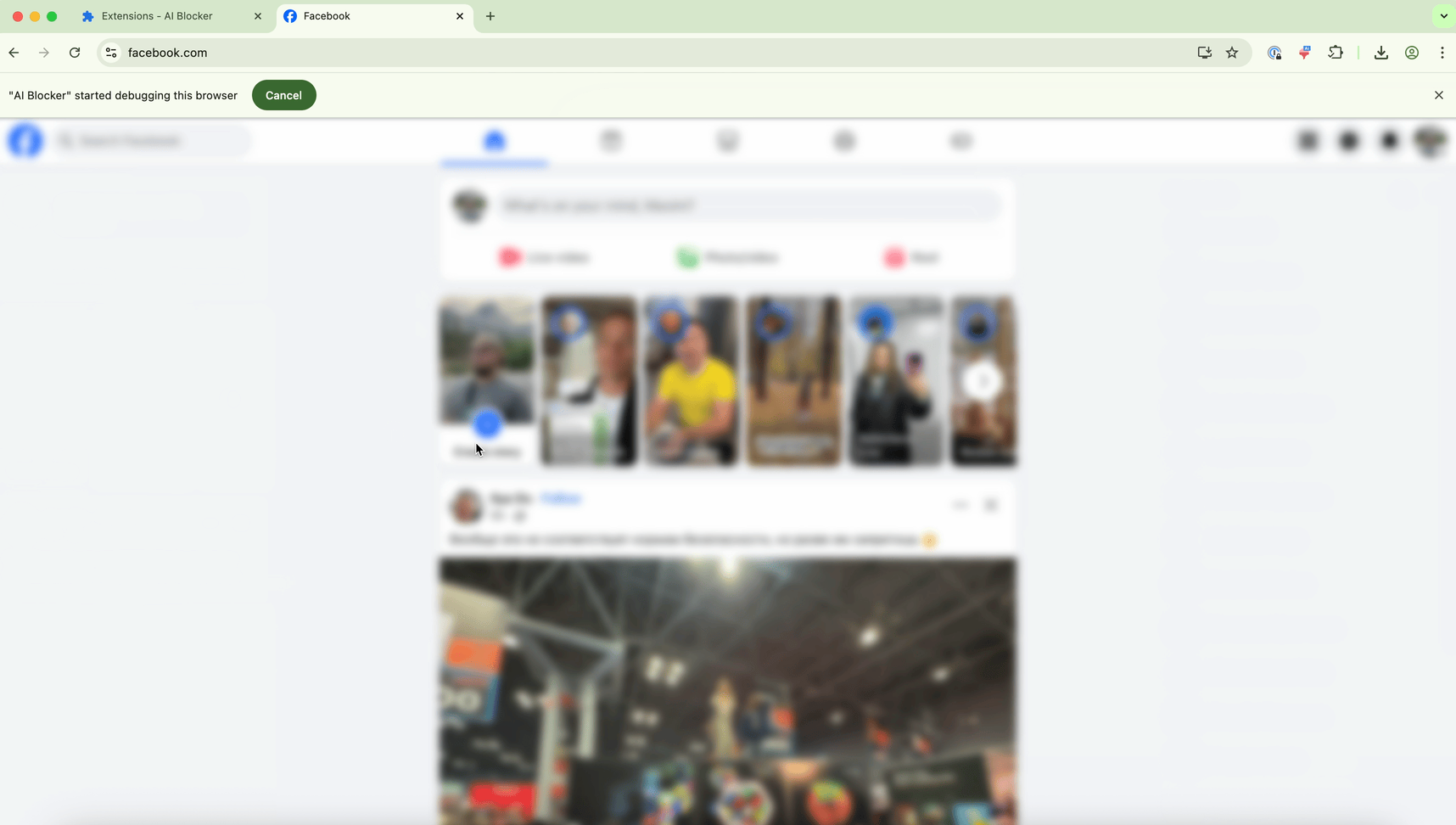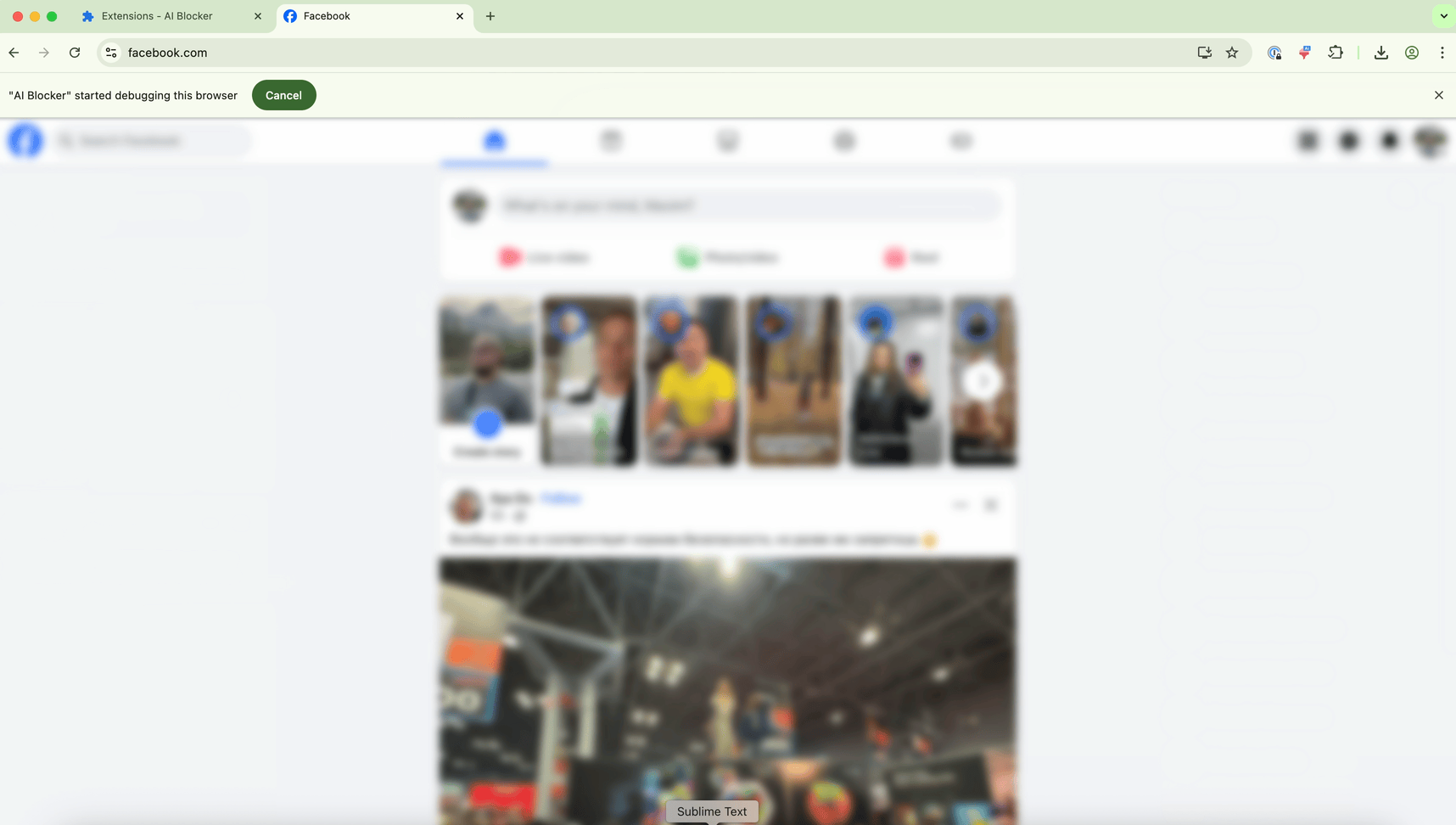
A outra abordagem foi usar chrome.tabs.captureVisibleTab — a API padrão do Chrome para extensões que tira screenshots. Esta não causa piscar, mas só captura o que está visível no viewport, e o Chrome limita quantos screenshots você pode tirar por segundo.
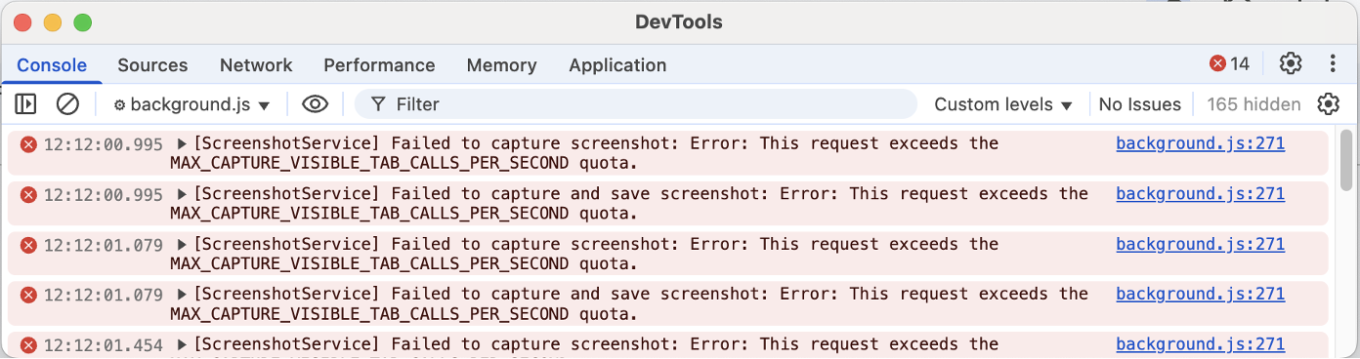
Então, se você tiver múltiplos elementos para analisar, precisa esperar, e só pode checar posts que já estão na tela.
Esses experimentos mostraram que os LLMs podem analisar posts e decidir se devem ser bloqueados. Isso significa que podemos substituir totalmente as listas de filtros? A resposta é não — ainda precisamos delas para saber o que verificar. Uma página da web tem milhares de elementos, e analisar todos seria lento e caro.
Experimento 3: estendendo listas de filtros
Se ainda precisamos saber quais elementos verificar, o passo lógico é conectar os LLMs às listas de filtros e generalizar o poder dos LLMs em uma ferramenta reutilizável para autores de listas de filtros. Mas o problema aqui é que escrever uma nova extensão personalizada para cada tarefa semântica não é escalável — precisamos de uma solução mais genérica.
A inspiração: Pseudo-classe CSS estendida, :contains.
A pergunta: E se pudéssemos verificar o significado, não apenas o texto?
O resultado: Três novas pseudo-classes experimentais:
selector:contains-meaning-embedding('criteria')
selector:contains-meaning-prompt('criteria')
selector:contains-meaning-vision('criteria')
Para criar essa solução genérica, me inspirei na biblioteca Extended CSS do AdGuard. Extended CSS é uma biblioteca JavaScript que adiciona pseudo-classes adicionais, estendendo o que é possível além do CSS nativo.
Ela possui a pseudo-classe :contains() que oculta elementos com texto específico. Decidi que poderíamos atualizar essa abordagem para verificar significado semântico em vez de apenas palavras-chave. Isso levou a três protótipos: embedding, prompt e vision.
:contains-meaning-embedding
Como funciona: Compara similaridades entre texto e critérios
Prós: Muito rápido e barato
Contras: Requer ajuste de limiares e pode ter dificuldades com múltiplos idiomas
Começando com :contains-meaning-embedding. Esta regra usa modelos de embedding, que transformam texto em números que representam significado. Calculamos a similaridade entre o texto do elemento e os critérios, e decidimos se correspondem. A vantagem é ser rápido e barato, especialmente com cache. A desvantagem é que precisa de ajuste de limiares e pode ter dificuldades com múltiplos idiomas.
:contains-meaning-prompt
Como funciona: Pergunta ao LLM se o conteúdo corresponde aos critérios
Prós: Mais preciso, sem limiares, independente de idioma
Contras: Mais lento e mais caro
Em seguida, temos :contains-meaning-prompt. Essas regras usam uma API simples de prompt, onde apenas perguntamos se o conteúdo de um elemento corresponde ou não aos critérios. Isso é mais preciso, não exige limiares e funciona em vários idiomas. A desvantagem é ser mais lento e caro do que embeddings.
:contains-meaning-vision
Como funciona: Pergunta ao LLM se o screenshot corresponde aos critérios
Prós: Detecta elementos que texto e embeddings não conseguem
Contras: UX complexa
E o último método é :contains-meaning-vision. Ele tira screenshots dos elementos selecionados e pergunta a LLMs com visão se a imagem corresponde aos critérios. Depois, funciona da mesma forma que :contains-meaning-prompt. A grande vantagem é que consegue detectar conteúdo visual que métodos baseados em texto não veem. A desvantagem é uma UX complexa, com possível piscar da tela.
Essas três regras podem fornecer aos desenvolvedores de filtros uma ferramenta flexível. Eles podem escolher: velocidade do embedding, precisão do prompt ou percepção visual do vision. Para reduzir o atraso na análise, uma solução é desfocar os elementos primeiro e depois revelá-los ou mantê-los ocultos.
Análise de desempenho e custo
Agora que temos esses três protótipos, surge a pergunta mais importante: eles são práticos? Isso realmente funcionaria em produção? Para responder, analisei o desempenho e o custo de cada abordagem.
Embeddings
Começando pelos embeddings. Inicialmente, usei o modelo na nuvem da OpenAI e, para ser honesto, os resultados não foram muito bons. Mas então decidi testar um modelo pequeno local, e o resultado me surpreendeu. Ele foi mais rápido, completamente gratuito e alcançou 100% de precisão nos meus testes. Isso mostra que, para certas tarefas, pequenos modelos locais podem superar APIs grandes na nuvem.

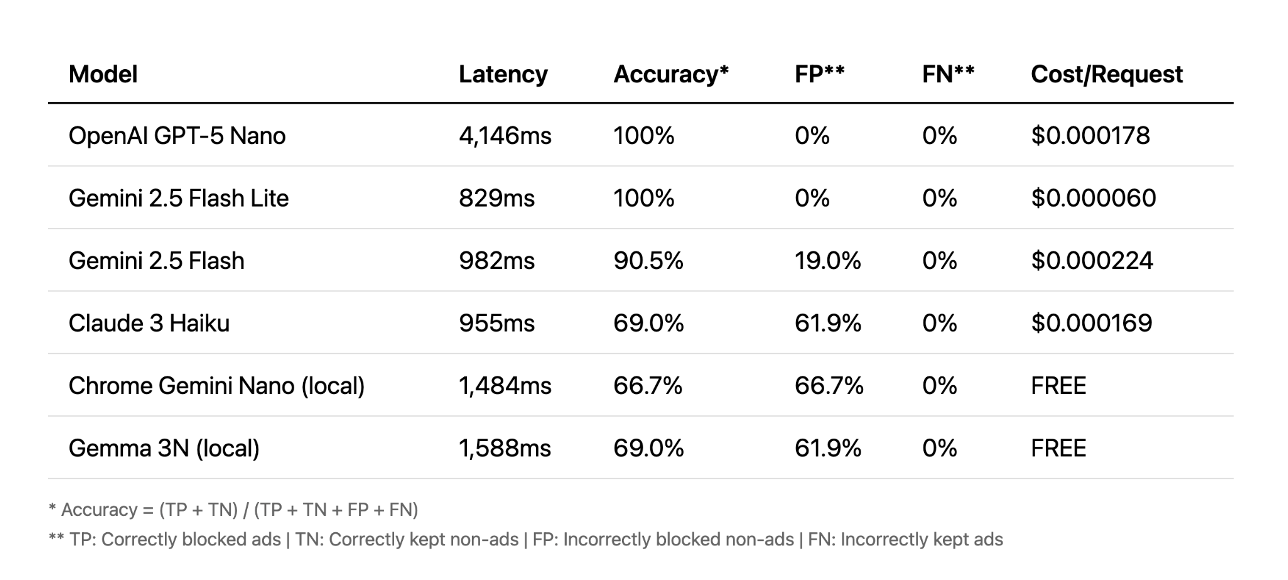
Prompts
Em seguida, vamos falar sobre prompts. Aqui a situação é diferente. As APIs na nuvem tiveram melhor desempenho, algumas atingindo 100% de precisão em menos de um segundo. Outras levaram mais de quatro segundos, o que é muito lento para uma boa experiência do usuário. Nesse caso, os modelos locais simplesmente não conseguiam acompanhar a precisão das nuvens.
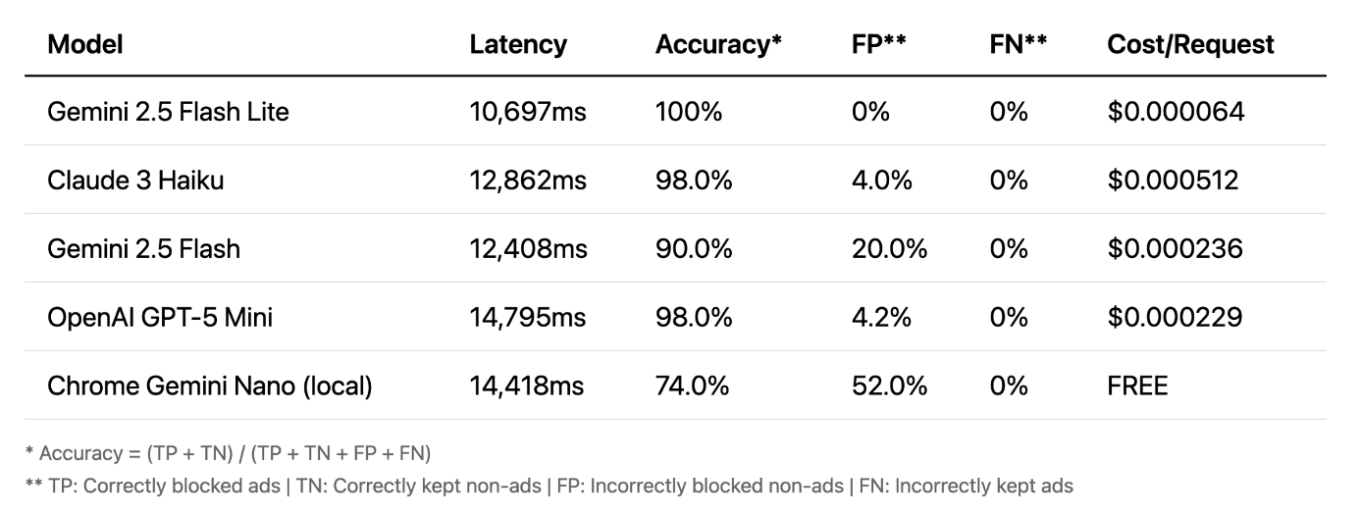
Vision
E finalmente, a visão. É aqui que as coisas ficam realmente interessantes. A precisão é muito alta — até modelos locais se saem bem. A visão é frequentemente o método mais preciso. Sua grande vantagem é que funciona com imagens, não com texto, capturando anúncios que outros métodos não veem. No entanto, há uma grande desvantagem: latência. Um atraso de 10 a 15 segundos não é prático para bloqueio em tempo real.
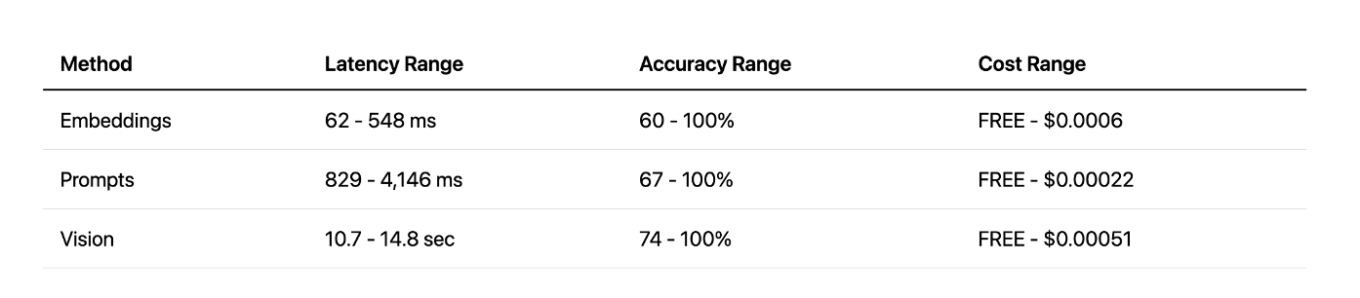
Comparação dos métodos
Comparando todos os métodos, a visão oferece ótima precisão, mas com latência muito alta. A abordagem de prompts oferece um bom equilíbrio entre velocidade e precisão, especialmente com APIs na nuvem. E a abordagem de embeddings locais foi uma surpresa agradável — muito rápida e eficaz, mas apenas para tarefas específicas. No final, cada método tem seus pontos fortes e fracos.
O futuro dessa abordagem
Visão: Muito lenta por enquanto, mas deve melhorar com o tempo
Embeddings: Pouco prática em extensões, ideal se integrada aos navegadores
Prompts de LLMs locais: Experimental, precisa de melhor precisão
O que isso significa para o futuro? Na minha opinião, a visão é simplesmente muito lenta no momento. Embeddings não são muito práticos em extensões de navegador, mas poderiam funcionar bem como uma API nativa no navegador. E prompts de LLMs locais são o caminho mais promissor para um experimento real e utilizável com a Prompt API do Chrome. Também há o desafio de melhorar a experiência do usuário, já que a abordagem atual de desfocar elementos não é ideal. Com modelos mais rápidos, poderíamos reduzir o tempo de desfoque, ou talvez seja possível criar uma solução completamente diferente.
O que aprendemos? Primeiro, os LLMs nos permitem ir além da simples correspondência de padrões e realmente entender o significado do conteúdo da web. Isso abre uma abordagem completamente nova e semântica para filtragem. Segundo, os LLMs permitem prototipagem rápida. Ideias que antes levavam meses de engenharia agora podem ser testadas em poucas horas. Embora ainda haja desafios práticos a resolver, essa nova abordagem nos permite repensar o que é possível no mundo da filtragem de conteúdo.
Espero que isso tenha dado uma nova perspectiva sobre filtragem de conteúdo. Você pode testar tudo o que falei neste artigo — basta baixar o AI AdBlocker na Chrome Store.
O código-fonte completo também está disponível no GitHub. Sinta-se à vontade para entrar em contato se tiver dúvidas ou sugestões!















































