Seus dados pessoais estão sendo usados para o treinamento de IA e você não conseguirá recuperá-los
A arte imita a vida, e disso todos sabemos. Mas, e se a arte imitasse sua vida pessoal e seus interesses, e fizesse isso tão bem que os limites entre o real e o imaginário já não estivessem claros?
Nós podemos não saber disso, mas já estamos nos tornando modelos para uma moderna tecnologia AI treinada a partir de muitos terabytes de dados retirados da Web, com pouquíssima filtragem. Estes dados incluem fotos pessoais, imagens médicas e até mesmo conteúdo com copyright. Em outras palavras, qualquer coisa disponível online.
Modelos de deep learning de texto para imagem como o DALLE-E 2, Midjourney e Stable Diffusion estão se tornando a cada dia melhores em reconhecer, interpretar e dar um novo significado a estes dados. Quando alimentados com uma entrada de texto, eles produzem imagens detalhadas baseadas no que aprenderam. Por mais que estas imagens ainda não sejam fotos perfeitas, elas estão ficando cada vez mais realísticas. Por mais que isso não pareça plausível, o algorítmo pode a qualquer momento mostrar o que quiser ou, ao menos, isso não pode ser controlado.
As chances de isso acontecer com uma pessoa comum são baixar. Figuras públicas, no entanto, estão muito mais susceptíveis a ter a sua imagem explorada e usada para enganar os desavisados. As IAs já se alimentaram dos seus dados disponíveis publicamente e já são capazes de te reconhecer de cara. Por isso, tudo que alguém mal intencionado precisa é criar é uma entrada de texto inteligente o suficiente.

Imagens de Elon Musk no estilo de Monet e Bill Gates com um rifle perto de uma carro, feitas pelo Stable Diffusion. A imagem é cortesia da Stability AI.
Atualmente, não é possível se salvar do feed de dados da Inteligência Artificial. Você somente poderá remover seus dados deste tipo de diretório após eles já terem sido usados como amostra de treino para uma AI. Para isso, você pode você pode usar sites como o Have I Been Trained, busque ter certeza de que está de acordo com os requisitos, faça uma reclamação e espere pelo melhor.
O estado da tecnologia: inspirador e confuso
Os geradores de imagem por inteligência artificial são uma novidade que tem dado o que falar, e isso explica em partes o porquê de eles terem escapado de regulamentações até agora. Uma das ferramentas mais avançadas para criar imagens a partir de uma descrição é o DALL-E. O codificador de texto para imagem foi lançado em janeiro passado por meio de uma lista de espera e ficou disponível para o público em geral em setembro. Cerca de 1,5 milhão de pessoas já estão usando o serviço,“criando mais de 2 milhões de imagens por dia” de acordo com a OpenAI, a empresa por trás da ferramenta.
Além da lista de espera, a OpenAI não restringiu a edição de rostos humanos. Mas, diferentemente de seus concorrentes a OpenAI adotou algumas medidas de segurança: a empresa afirmou que eles refinaram o algorítmo de filtragem da ferramente para bloquear conteúdo sexual, político, violento e de ódio. A política do DALLE-E também proíbe que os usuários façam upload de “imagens de qualquer pessoa sem o seu consetimento” e imagens sobre as quais os usuários não têm nenhum direito.
Parece não haver nenhuma maneira prática para o DALLE-E garantir que esta política em particular seja respeitada. Em uma tentativa de minimizar os riscos de um mal uso em potencial, os desenvolvedores disseram anteriormente que eles refinaram o processo de treinamento do DALL-E, “limitando” sua habilidade de memorizar faces. Isso foi feito principalmente para que a IA não produza sósios de figuras públicas ou acaba colocando-as em um contexto enganoso. A política de conteúdo do OpenAI bane especificamente imagnes de “políticos, caixar de votos, ou qualquer outro conteúdo que possa ser usado para influenciar o processo político ou uma campanha” e envia um aviso diante de tentativas de criar imagens de figuras públicas. Usuários reportaram que o DALL-E de fato parece não responder às entradas mencionando celebridades e políticos.
Apesar de seu nome, o OpenAI não é de código aberto, e existe uma boa razão para isso. A OpenAI defende que “tornar os componentes básicos do sistema disponíveis livremente dá espaço para que pessoas mal-intencionadas o treinem para mostrar conteúdo inapropriado, como pornografia e violência gráfica.”
Outros, no entanto, se aproveitaram da brecha deixada pelo OpenAI. Inspirado pelo DALL-E, um grupo de entusiastas da inteligência artificial criou o Crayion (antes conhecido como DALLE-E mini), um gerador de imagens text-to-image de código aberto. Mas desde que foi treinado com uma amostra relativamente pequena de dados não-filtrados da Internet (algo em torno de 15 milhões de pares de imagens e texto correspondente), os desenhos resultantes, especialmente aqueles relacionados a pessoas, são significativamente menos realistas.

Muito mais avançado que o Crayion e significativamente menos restritivo que o DALLE-E 2 é o Stable Diffusion, um modelo de código aberto lançado pela startup StabilityAI em agosto deste ano. Ele permite criar imagens de figuras públicas, de protestos e acidentes que nunca aconteceram e pode ser usado em atos de desinformação.

Imagens da Stable Diffusion mostrando fumaça saindo da Casa Branca e protestos na Disney. Imagem cortesia do Stability AI.
A Stable Diffusion garante a permissão de distribuir e vender os resultados se o usuário concordar com uma lista de regras. Por exemplo, você não pode usar o modelo para violar a lei, machucar menores de idade, espalhar informações falsas “com o propósito de causar mal aos outros”, “causar ou disseminar informação pessoal identificável que possa ser usada para causar danos em um indivíduo”, oferecer conselhos médicos, infringir copyright, imitar indivíduos e “defamar, depreciar ou assediar outros.” Mais uma vez, é difícil dizer como a empresa pretende punir aqueles que quebrarem estas regras. O peso recai todo sobre quem não tem nenhuma ligação com o site ou sobre as vítimas que encontram o conteúdo proibido sozinhas.
Para deixar tudo ainda pior (ou melhor, depende do seu ponto de vista), há o fato de que os modelos de inteligência artificial estão ficando cada vez melhores em imitar as habilidades humanas e estão ficando mais e mais perto de enganar os observadores. Uma controversa surgiu após um artista não-profissional ganhar o primeiro lugar na feira de arte digital do Colorado deste ano com um trabalho criado no Midjourney, outra ferramenta de IA text-to-image. Não faz muito tempo que o jornalista do The Atlantic causou uma discussão no Twitter depois de usar duas imagens do Midjourney para inventar duas imagens do teórico da conspiração Alex Jones em uma Newsletter.
É seguro pensar que as ferramentas baseadas em IA ficarão ainda melhores com o passar do tempo. Pesquisadores envolvidos no modelo de IA text-to-image do Google, o Imagen, afirmaram que ele já está com uma performance melhor do que a da última versão do DALLE-E, a DALLE-E 2, no que diz respeito à qualidade de imagem e precisão.
Há muita especulação e incertezas sobre como os sintetizadores de imagem com base em IA irão afetar a arte e a realidade que conhecemos. Isso vai depender fortemente da disposição dos desenvolvedores em domar os seus monstros da realidade virtual, mas também do tipo de dados dos quais elas vão se alimentar.
De onde vêm os dados?
Modelos de IA como o DALLE-E e Stable Diffusion são treinados a partir de bases de dados gigantes coletados de toda a Internet.
Assim, o DALLE-E 2 foi alimentado com 650 milhões de pares texto-imagem que já estavam disponíveis na internet. Já o Stability AI foi treinado principalmente com o subconjunto em inglês da base de dados LAION-5B. O LAION 5B ("Large-scale Artificial Intelligence Open Network", ou Rede aberta de Inteligência artificial em grande escala) é uma base de dados de código aberto contendo 5,6 bilhões de imagens coletadas da Web, incluindo 2,3 bilhões de pares imagem-texto em inglês, que garantem a ela a posição de maior do mundo na categoria. Sua predecessora, a LAION-400, contém 413 milhões de pares e foi usada pelo Google para treinar o Imagen. Esta base de dados foi criada originalmente por pesquisadores na tentativa de replicar a base de dados do OpenAI, fechada para o público.
A LAION descreve a si mesma como uma organização sem fins lucrativos com a missão de “democratizar a pesquisa e a experimentação com modelos de treinamento multi-modal em grande escala”. Por mais que a missão seja nobre, ela representa um alto custo para a privacidade. Os dados reunidos pelos pesquisadores vêm do Common Crawl, outra organização sem fins lucrativos que faz uma varredura na Internet todos os meses e oferece petabytes de dados gratuitamente para o público. Nesta ToS, Common Crawl afirma que eles *“apenas encontram os dados na web”* e “não garantem conteúdo ou respondendo se houver algo errado com ele”
Considerando a origem dos dados, não é surpresa que informações de identificação pessoal (PII), imagens confidenciais e conteúdo protegido por direitos autorais possam se infiltrar no conjunto de dados. A ArtTechnica relatou no mês passado como um artista de IA descobriu suas próprias fotos médicas no conjunto de dados LAION-5B. As fotos foram tiradas pelo médico do artista (já falecido) e destinavam-se apenas para uso privado desse médico.
Vale notar que a LAION não hospeda as imagens, mas apenas fornece URLs de onde elas podem ser baixadas. Assim, a LAION presumivelmente não pode ser responsabilizada pela divulgação de dados pessoais ou de profissionais. Isso também significa que, legalmente, a tentativa de encontrar os culpados pelo possível uso indevido de dados é praticamente inútil. Outra questão é que não há como cancelar o treinamento de IA e remover seus dados após eles serem usados demanda muito esforço.
Como remover dados pessoais que alimentaram uma IA?
Para começar, para solicitar a remoção de suas imagens do conjunto de dados de treinamento de IA, você deve encontrá-las lá. Pode parecer uma tarefa difícil, dado que existem milhões de pares de imagem para texto para percorrer. Felizmente, agora existe um atalho para isso. No mês passado, uma empresa chamada Spawning AI lançou Have I Been Trained?, um site onde você pode pesquisar o banco de dados LAION-5B alimentando-o com uma imagem ou um prompt de texto. Ou você pode apenas brincar com o algoritmo (cuidado, pode lhe dar alguns resultados muito curiosos).
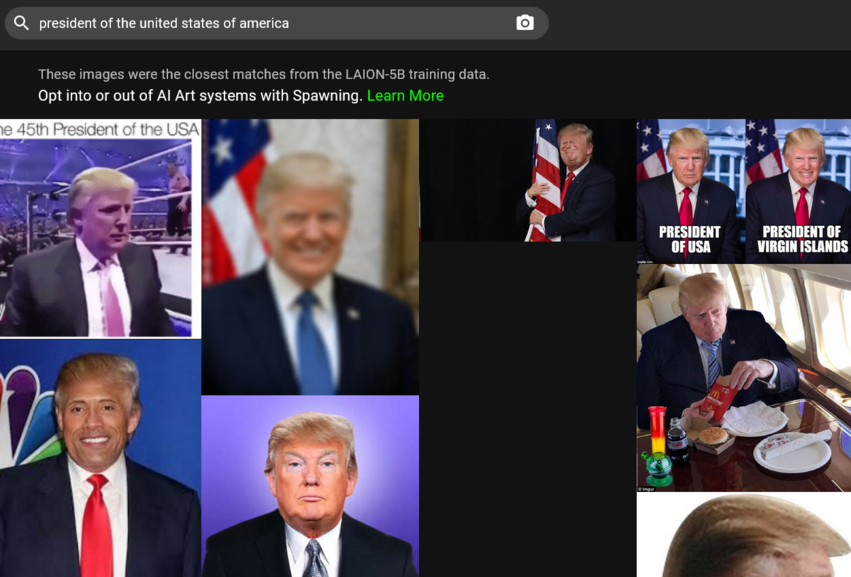
Se você conseguir encontrar sua imagem, precisará preencher um formulário de remoção na página GDPR da LAION. A LAION promete investigar o relatório e, se descobrir que a referida imagem viola a lei de proteção de dados da UE, vai removê-la de todos os repositórios de dados sob seu controle e de futuras liberações
A geração também está construindo ferramentas que permitiriam aos artistas “optar por participar ou não do treinamento de grandes modelos de IA”, bem como “definir permissões sobre como seu estilo e semelhança são usados.” Os usuários podem inscrever-se para o beta acesso às ferramentas no site da empresa. A Stable Diffusion, que apóia os esforços de Spawning, afirma que construirá “um sistema de opt-in e opt-out para artistas e outros que os serviços podem usar em parceria com organizações líderes.”
O DALLE-E permite que indivíduos que descobrem que seu trabalho foi usado sem seu consentimento relatem a violação ao e-mail da OpenAI. Quanto à mãe dos dragões, a fonte original de muitos dos dados - Common Crawl - parece listar apenas uma caixa postal onde você pode relatar uma violação de direitos autorais.
Para resumir, somos deixados por conta própria quando se trata de garantir que nossos dados não sejam sugados pela IA. Isso se deve em parte ao dilema legal quando cada lado não reivindica nenhuma responsabilidade pelo resultado final. Em parte, é assim que a internet funciona – ela nunca esquece.
Uma IA revelará sua aparência exata e poderá "desaprender" como você se parece?
Como visto no exemplo de figuras públicas, a IA, com treinamento suficiente, pode gerar imagens reconhecíveis de pessoas reais. Tecnicamente, não há nada que impeça a IA de fazer o mesmo truque com a sua imagem.
A OpenAI admite que, embora o DALLE-E 2 não possa “gerar literalmente imagens exatas de pessoas, pode ser possível gerar uma semelhança semelhante a alguém nos dados de treinamento.” O mesmo provavelmente vale para outros modelos de IA. A pesquisa mostrou que as imagens geradas por outra classe de modelos de aprendizagem profunda - Generative Adversarial Networks
(GANs) — lembram pessoas reais. No artigo intitulado Esta pessoa (provavelmente) existe. Ataques de associação de identidade contra rostos gerados por GAN pesquisadores mostraram que foi possível reidentificar identidades de origem que contribuíram para gerar imagens de “pessoas inexistentes. ”
“Enquanto algumas amostras apenas apresentam semelhanças, outras imagens geradas compartilham fortemente características idiossincráticas de identidades de treinamento”, descobriram os pesquisadores.
Quanto à possibilidade de os modelos de IA desaprenderem o que já aprenderam sobre você, Emad Mostaque, CEO da Stability AI, disse à Ars Technica que era possível, mas requer alguns ajustes ou trabalho extra. A grande questão é se os desenvolvedores estão dispostos a fazer grandes esforços para fazê-lo - como eles não são obrigados a fazer.
Resolvendo o problema da IA. Uma missão impossível?
Não há como negar que os resultados alcançados por esses pioneiros da Inteligência Artificial são admiráveis. O fato de alguns deles a tornarem de código aberto e, no caso do Stability AI, lançá-lo sob uma licença permissiva que não proíbe o uso comercial, ajudará pesquisadores, criadores e progressos em várias áreas.
No entanto, isso também pode dar muito errado, pois é extremamente difícil impedir que pessoas mal-intencionadas usem o modelo de código aberto. O mais importante, talvez, é que atualmente não há como artistas e pessoas comuns optarem por não se tornar parte de um produto final gerado por IA. Além disso, mesmo que desejemos remover nossas imagens dos dados de treinamento, temos que contar com a boa vontade das empresas.
Essas questões afetarão ainda mais pessoas à medida que essas tecnologias se tornarem mais comuns. Por exemplo, a Microsoft anunciou recentemente que está integrando dois de seus aplicativos com o DALL-E 2. Um dos aplicativos é o Image Creator, que estará disponível gratuitamente no buscador da Microsoft Bing e no Edge.
A situação exige regulamentação. Pode ser uma curadoria cuidadosa do conjunto de dados, um mecanismo claro de exclusão respeitado por todas as partes ou algum outro método de prevenção, não sabemos. Mas, da forma come estão agora, os geradores IA de imagem a partir de texto continuam sendo uma ameaça à privacidade, e isso tende a piorar.














































